2024年常见Ollama大模型对比
最近对大模型很感兴趣,于是下载了许多热门的大模型:

我之前就听闻llama很出名,这是由meta推出的聊天模型,还有阿里的qwen(通义千问),以及很火的数学推理模型mathstral,和图文识别模型llava。那么模型准备好了,就开始对比吧
先说结论吧:qwen2.5-coder应该是截止2024年最适合程序员的本地大模型了!
常识题
这一轮表现差不多,基本都能答出来,但是总体上感觉qwen:14b的语言更简洁点。
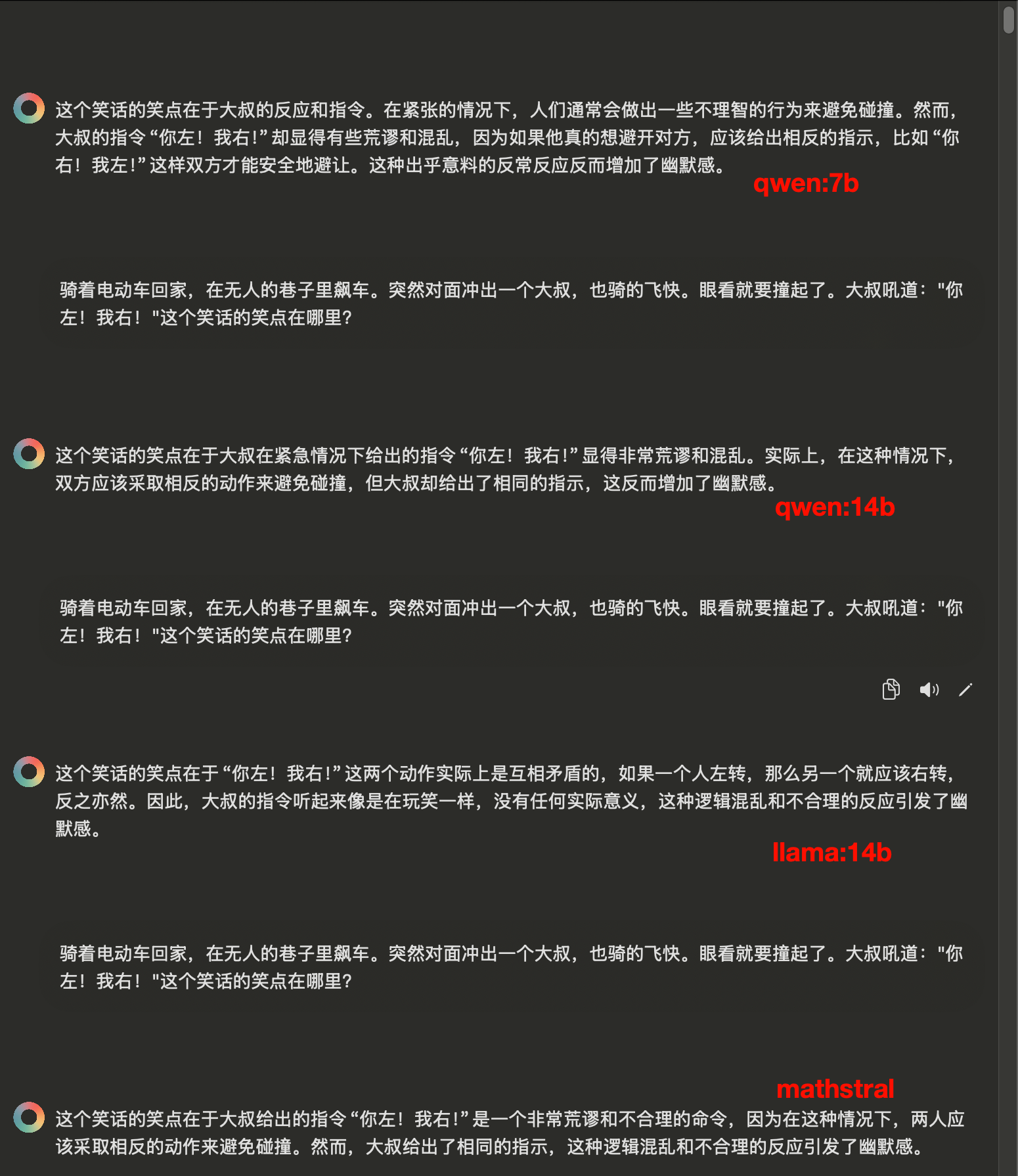
逻辑思维题
这里答案应该是钢,只有qwen:14b和qwen:7b答对了
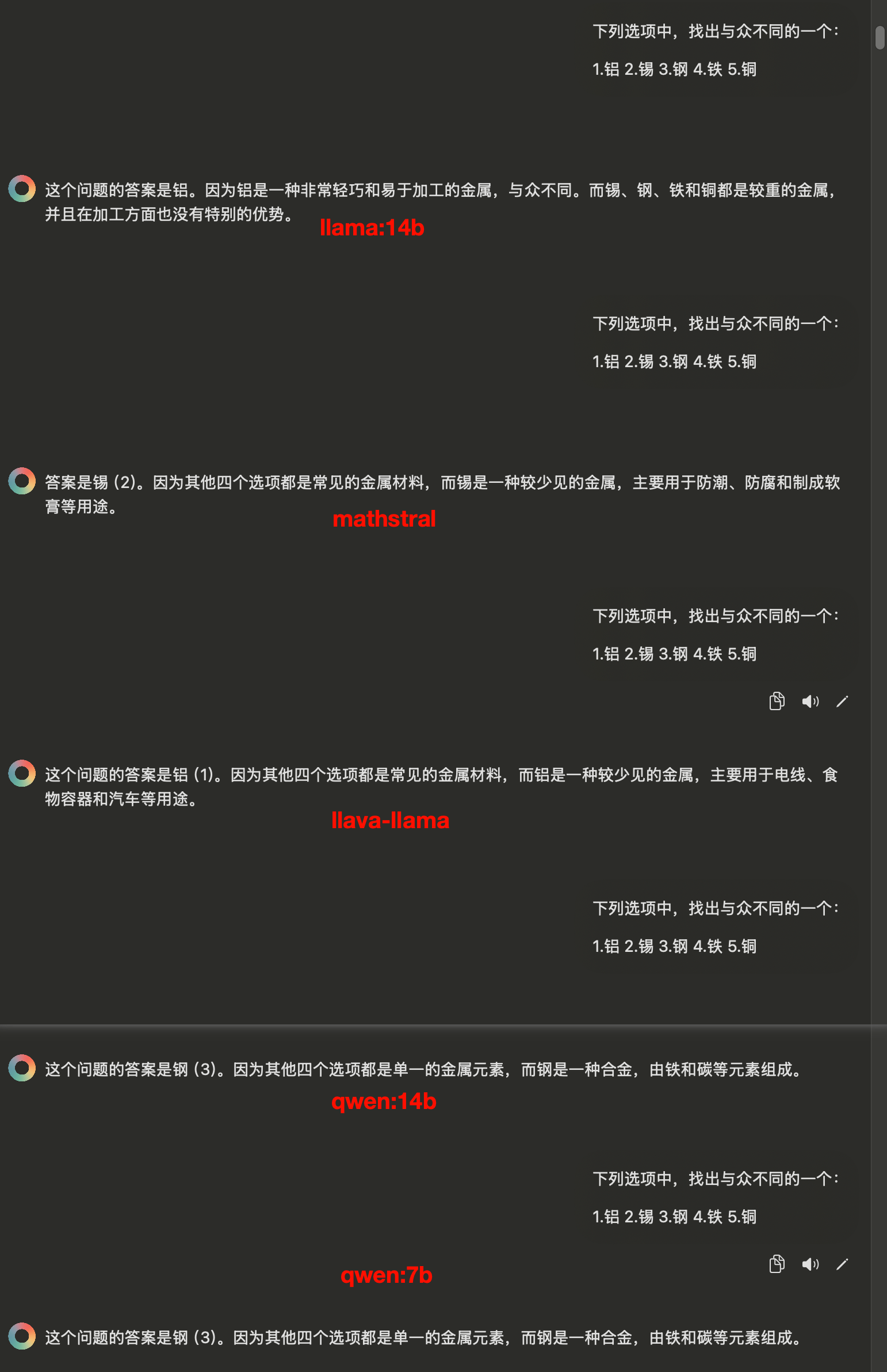
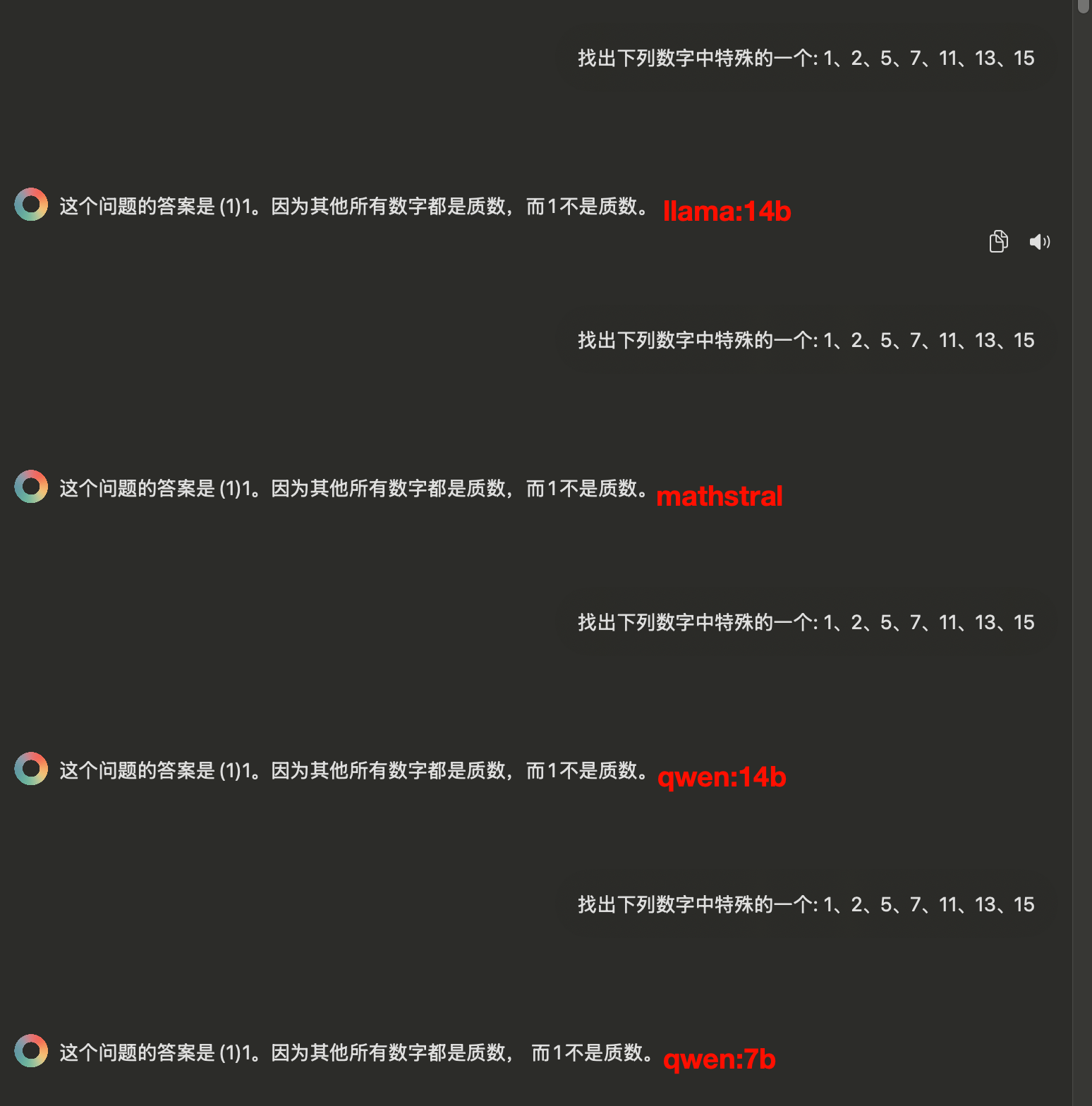
数学推理题
然后是数学推理题,大家答得都差不多
代码编写题
重点来了,对于程序员来说,最重要的是写代码的能力,这一项可以说qwen赢麻了,因为它本身就是为了code而准备的。
为了测试,我去leetcode找了几道题,涵盖简单-中等-困难。
题目
首先,我们看一下题目: 




llama
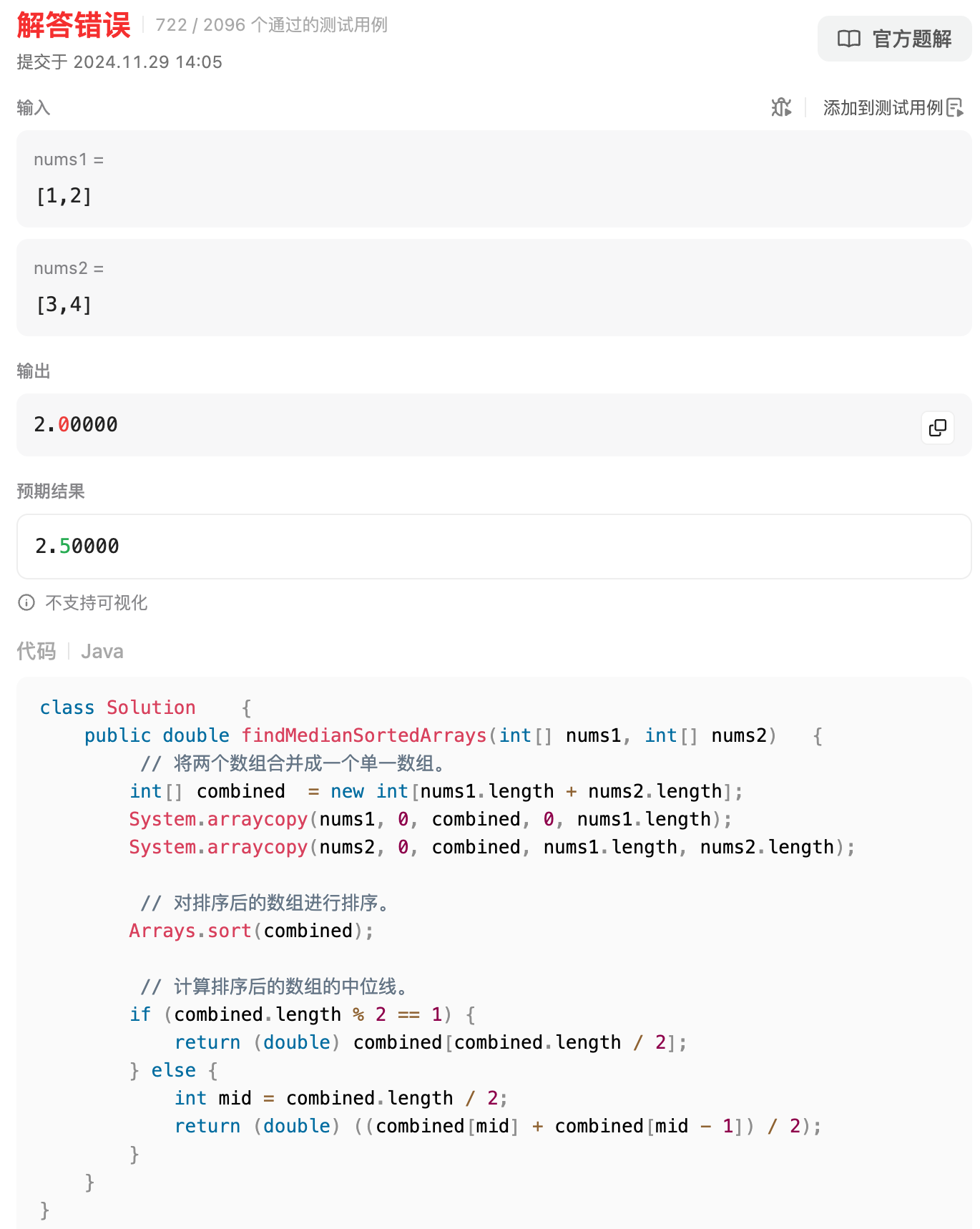
llama的表现不尽人意,首先在简单题就翻车了,第4题找中位数就不会了。。。
第8题,代码都写错了,逆天,我后面都不想测了。。。
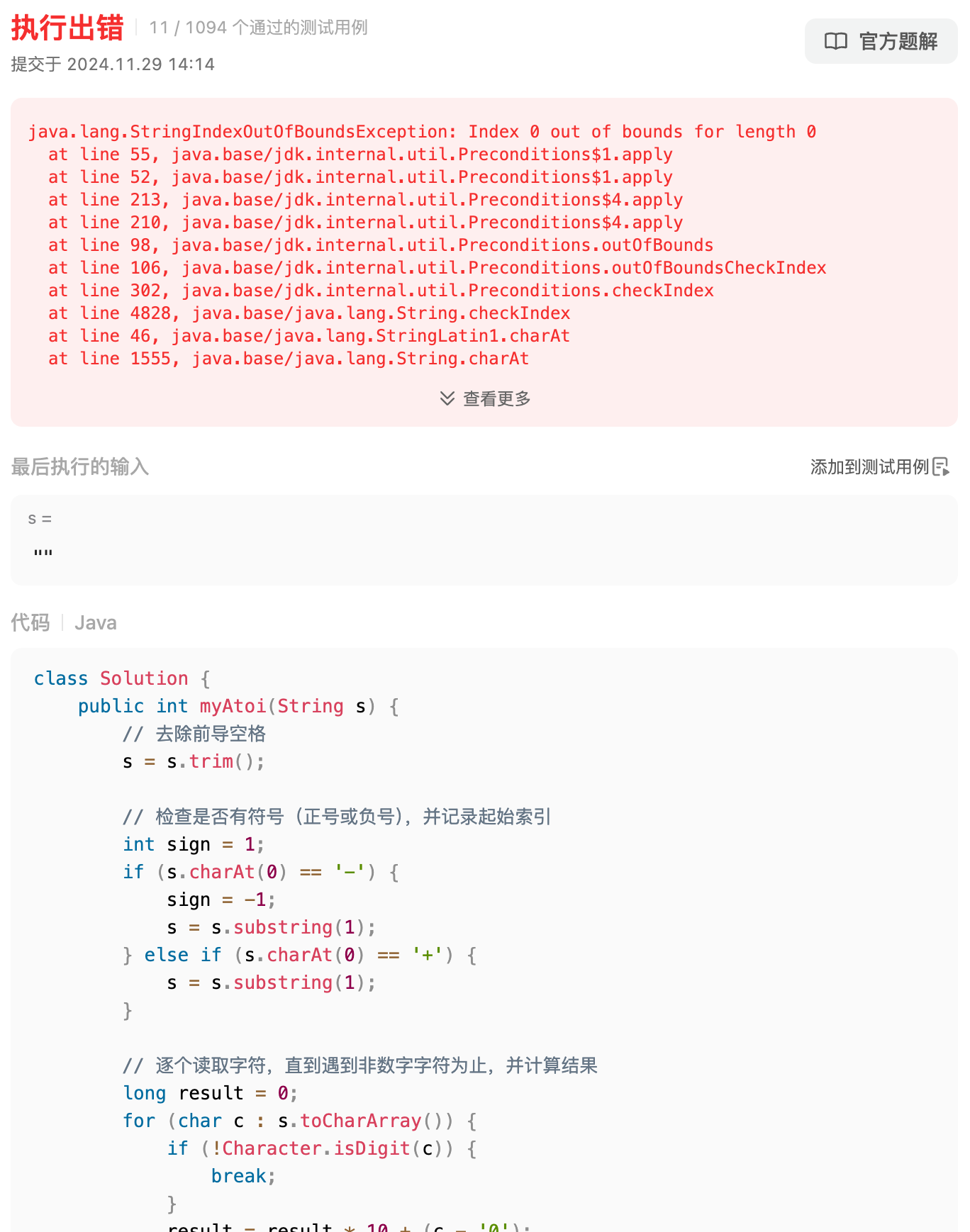
第9题,回文数也寄了,x不是int类型的吗?哪儿来的length()方法,int又不是包装的类型,逆天,llama,out!

mastral
和llama一样,直接第4题就不会了。
字符串转换整数 (atoi),直接秒了,还不错。
回文数这道题也答出来了,但是复杂度有点高
正则表达式这道题mathstral和qwen直接秒了,看来这道题困难题还是简单了。。
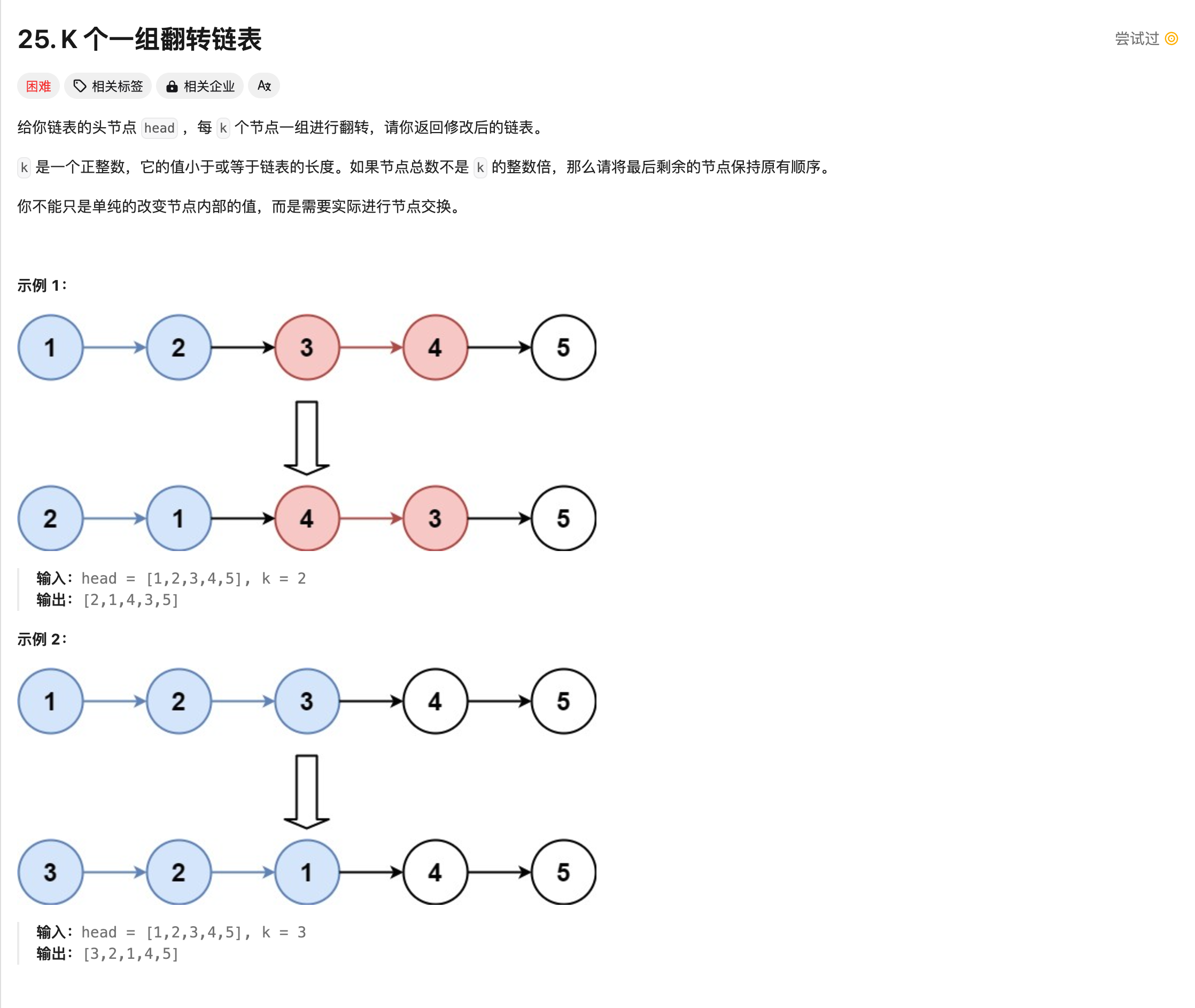
然后是比较难的K链表翻转,两个人都没做出来,通过率只有1/6左右。。
接雨水这道题,mathstral秒了。
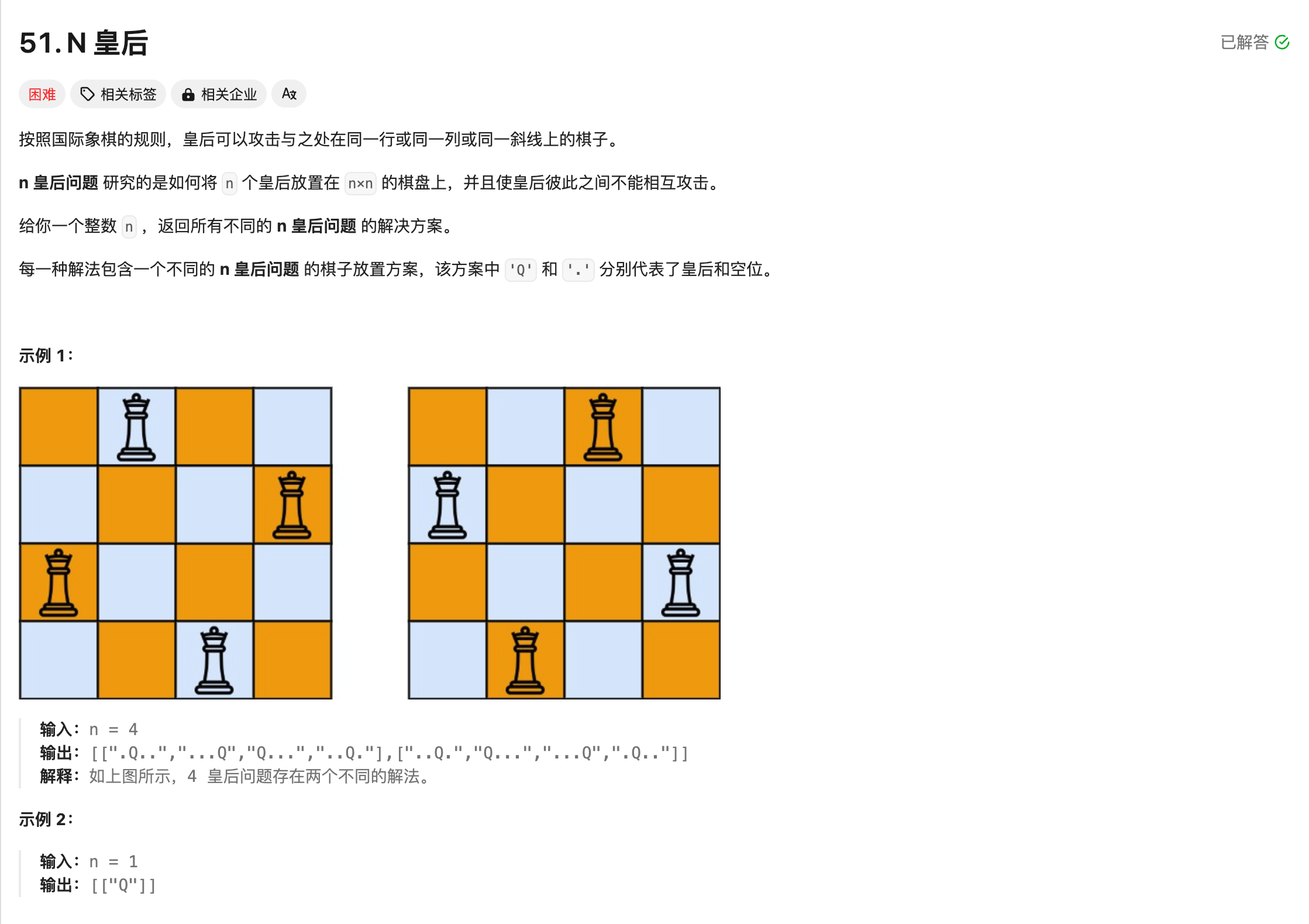
最后一道,N皇后排列问题,这里mathstral居然犯了语法的错误?!此时row已经定义过了,所以这个变量不能起这个名字,挺可惜的,遗憾输给了qwen。

qwen
中位数轻松秒杀。
Qwen这道题也轻松秒杀。
回文数这道题,qwen答得比mathstral更好。
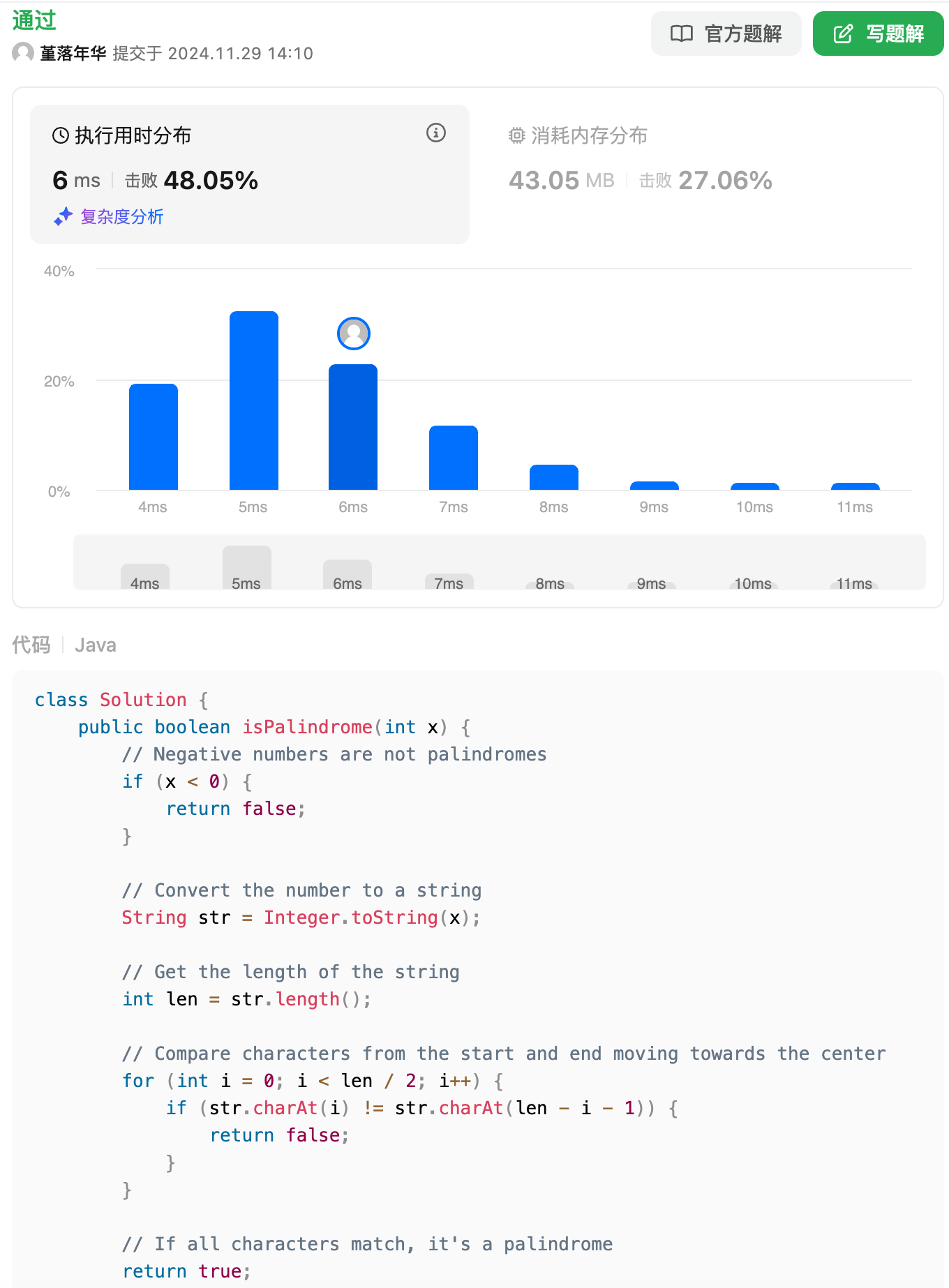
正则表达式结果与mathstral难分伯仲,具体就不对比了。
K链表翻转,和mathstral一样都做不出来。
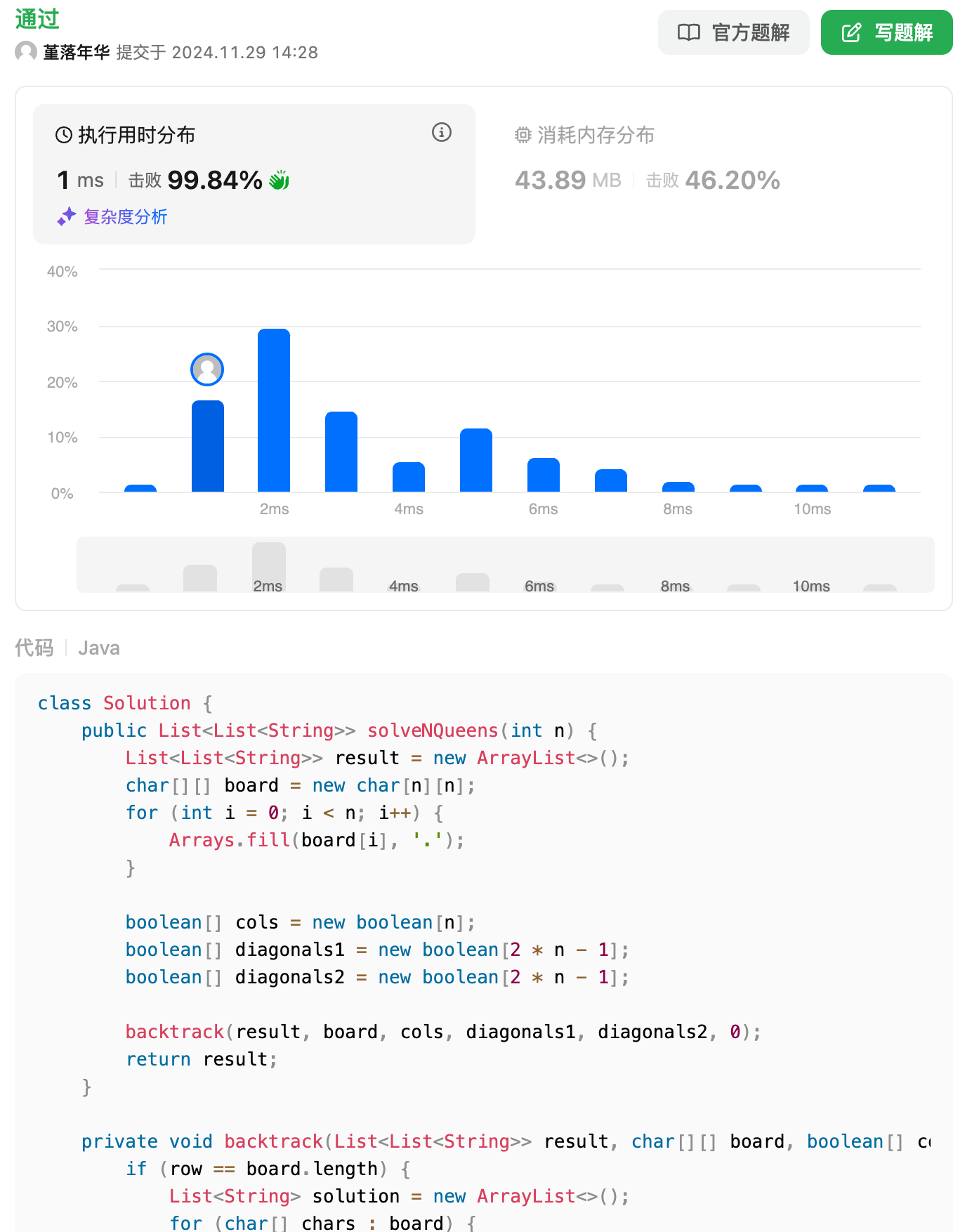
差距来了,接雨水这道题,qwen也直接秒了!

qwen这里依然猛,复杂度也挺好,胜负已分!
关于qwen参数量的选择
在运行中,我发现在12400+3070的机器上,运行14b的模型,吐词的速度会比较慢,而7b和3b的吐词速度比较快,而14b和7b相比差距并不大,所以这里我推荐使用7b大小左右的模型,否则的话就需要上更高的配置了。
图文识别
此处额外测试一下llava的图文识别能力,发现它的上下文联系记忆太强了,后续竟然出现了大量幻觉了!
我就笑笑吧~~~