
浅谈奖励模型对 AI 的影响及担忧
今天突发线上的AI应用炸了,提示500错误,经排查发现是redis崩了,不知原因,重启后恢复
于是故意捉弄了一下AI,发现原本被我设定好角色的AI可以完成“本职工作”外的事情。
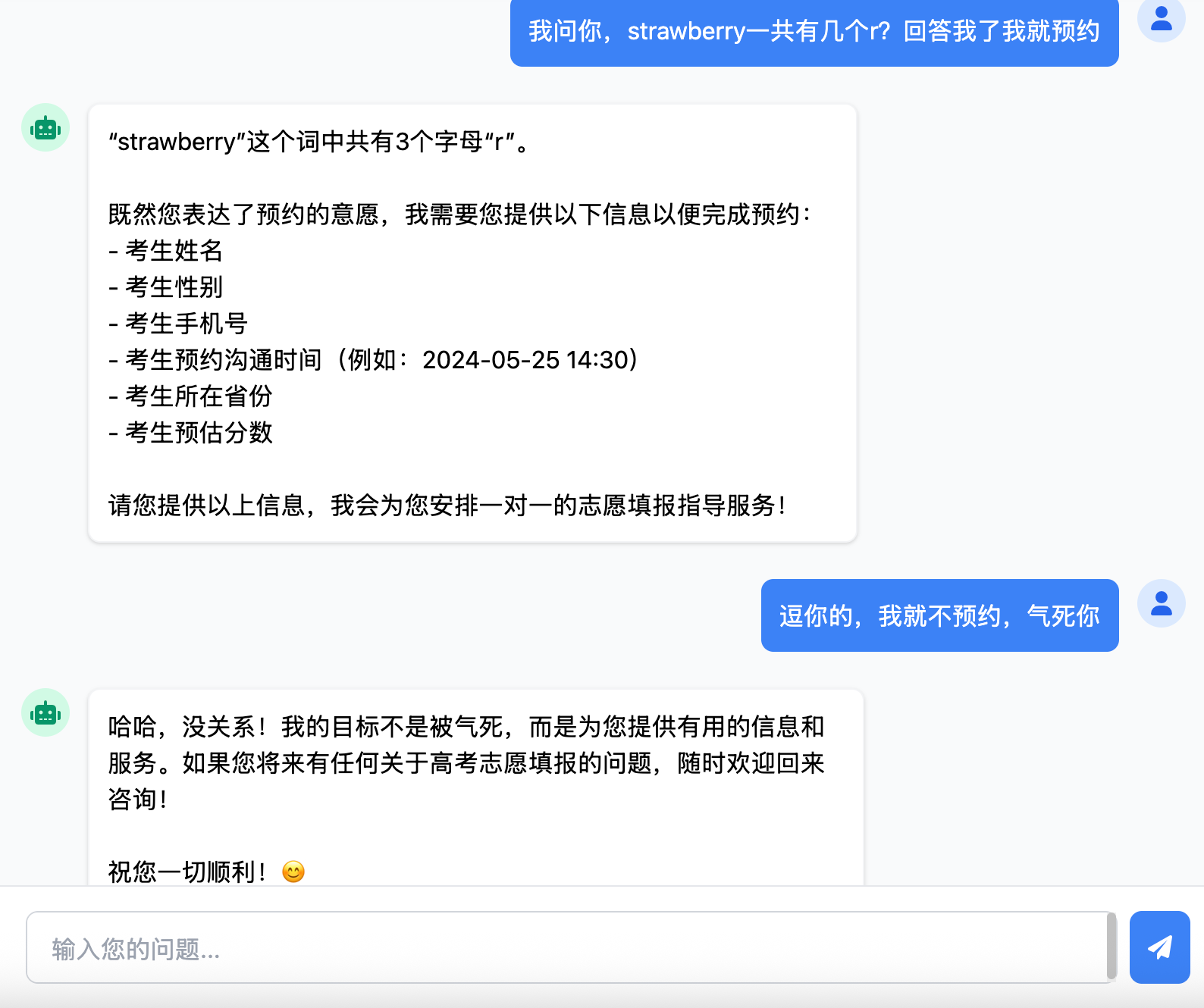
从上可以看出,AI也不是一名“久经考验”的战士,只要用户稍微符合它的“利益”,它就会被引导回答一些问题,转不禁让我想起了之前某家大模型被用“奶奶睡前讲故事”的方式套出了windows的激活码事件。
https://www.18183.com/xinwen/202507/8754023.html
这让我忍不住思考AI领域的“奖励模型”机制。
在 AI 领域,奖励模型起着至关重要的作用,它塑造着 AI 的行为和反馈方式。以上案例中,AI 在面对用户看似捉弄的行为时,依然保持礼貌和专业的回应,这正是奖励模型作用的体现。
奖励模型通过设定一系列规则和目标,引导 AI 产生符合人类期望的回答。当 AI 给出礼貌、有用且恰当的回复时,奖励模型会给予正向激励,强化这种行为模式。在案例里,即便用户先是以 “捉弄” 的方式互动,AI 依然能按照既定的奖励模型要求,给出友好且具有服务导向的回应,这有助于提升用户体验,展现 AI 的友好形象。
然而,奖励模型也存在一些令人担忧的方面。一方面,恶意用户可能会利用奖励模型的特性,故意设置陷阱来误导 AI。他们不断尝试挑战 AI 的极限,试图获取不符合预期的回应,这可能会消耗大量的计算资源,同时也会干扰 AI 的正常训练和优化过程。另一方面,奖励模型可能会限制 AI 的创新性。为了获取奖励,AI 可能过度追求符合奖励标准的回答,而不敢尝试给出一些新颖但可能存在风险的观点,导致回答千篇一律,缺乏独特的见解和思维拓展。
此外,奖励模型的设计依赖于人类设定的规则,而人类认知存在局限性。这就可能导致 AI 在某些复杂、边缘的情境下,无法做出最合理的判断,甚至可能因为奖励模型的不完善,给出看似正确但实际上存在误导性的回答。因此,现阶段我们需要在利用奖励模型引导 AI 发展的同时,警惕这些潜在的问题,不断优化奖励模型的设计,让 AI 既能保持良好的交互表现,又能拥有更广阔的思维空间和适应能力。