
------------------Java基础------------------
八种基本的数据类型
Java支持数据类型分为两类: 基本数据类型和引用数据类型。
基本数据类型共有8种,可以分为三类:
- 数值型:整数类型(byte、short、int、long)和浮点类型(float、double)
- 字符型:char
- 布尔型:boolean
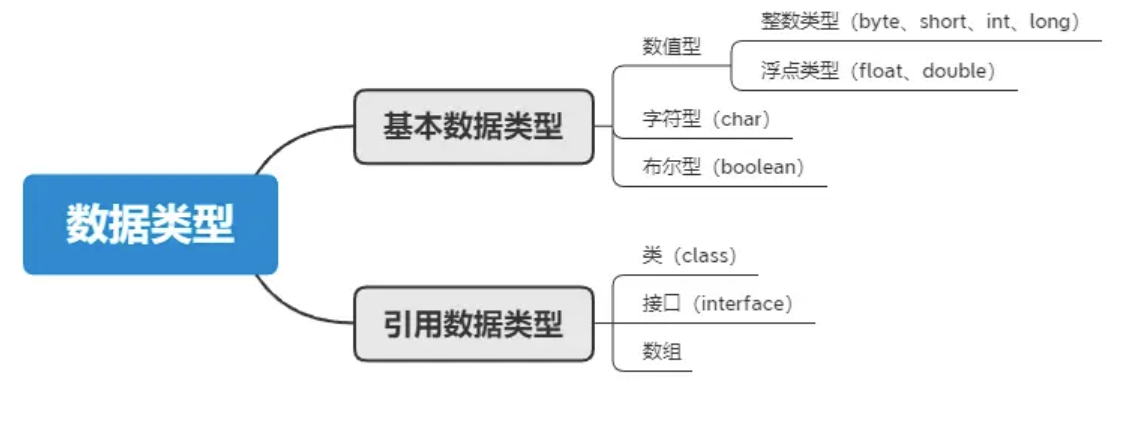
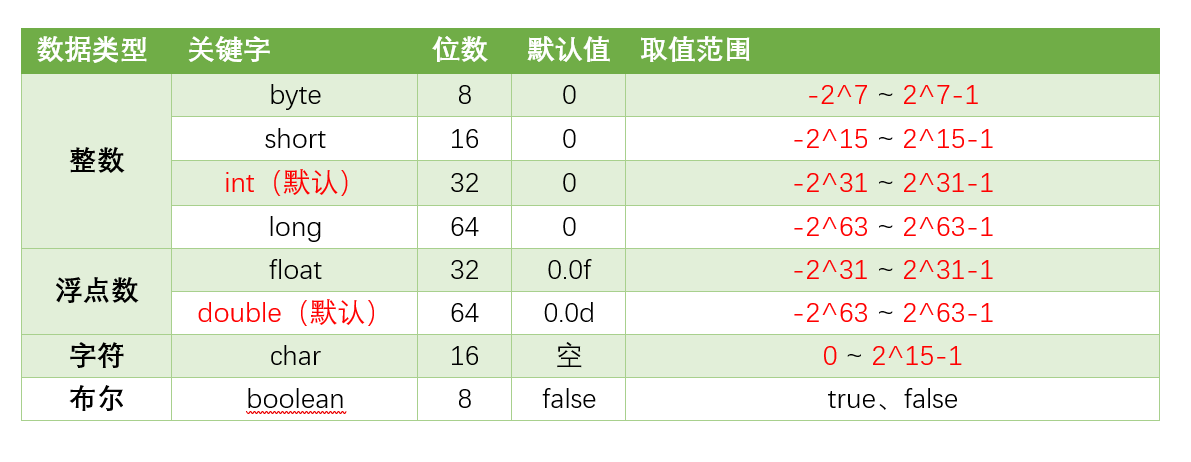
8种基本数据类型的默认值、位数、取值范围,如下表所示:
String、StringBuffer 和 StringBuilder 的区别
- String:不可变,适合少量字符串操作。
- StringBuffer:可变且线程安全,适合多线程环境中的频繁字符串修改,,内部使用了
synchronized关键字来保证多线程环境下的安全性。 - StringBuilder:可变且非线程安全,适合单线程环境中的高性能字符串处理,性能比
StringBuffer更高。
接口和抽象类的区别
接口的设计是自上而下的。我们知晓某一行为,于是基于这些行为约束定义了接口,一些类需要有这些行为,因此实现对应的接口。
抽象类的设计是自下而上的。我们写了很多类,发现它们之间有共性,通过代码复用将公共逻辑封装成一个抽象类,减少代码冗余。
所谓的 自上而下 指的是先约定接口,再实现。
而 自下而上的 是先有一些类,才抽象了共同父类(可能和学校教的不太一样,但是实战中很多时候都是因为重构才有的抽象)。
其他区别
1)方法实现
接口中的方法默认是 public 和 abstract(但在 Java8 之后可以设置 default 方法或者静态方法)。
抽象类可以包含 abstract 方法(没有实现)和具体方法(有实现)。它允许子类继承并重用抽象类中的方法实现。
2)构造函数和成员变量
接口不能包含构造函数,接口中的成员变量默认为常量。
抽象类可以包含构造函数,成员变量可以有不同的访问修饰符。
3)多继承
抽象类只能单继承,接口可以有多个实现。
注解的原理
注解其实就是一个标记,是一种提供元数据的机制,用于给代码添加说明信息。
注解可以标记在类上、方法上、属性上等,标记自身也可以设置一些值。
注解本身不影响程序的逻辑执行,但可以通过工具或框架来利用这些信息进行特定的处理,如代码生成、编译时检查、运行时处理等。
反射机制
反射机制提供了在运行时动态创建对象、调用方法、访问字段等功能,而无需在编译时知道这些类的具体信息。
反射机制的优点:
- 可以动态地获取类的信息,不需要在编译时就知道类的信息。
- 可以动态地创建对象,不需要在编译时就知道对象的类型。
- 可以动态地调用对象的属性和方法,在运行时动态地改变对象的行为。
反射机制的缺点:
- 性能损失。
- 安全风险。
反射机制的应用场景:
- 动态代理。
- 测试工具。
- ORM框架。
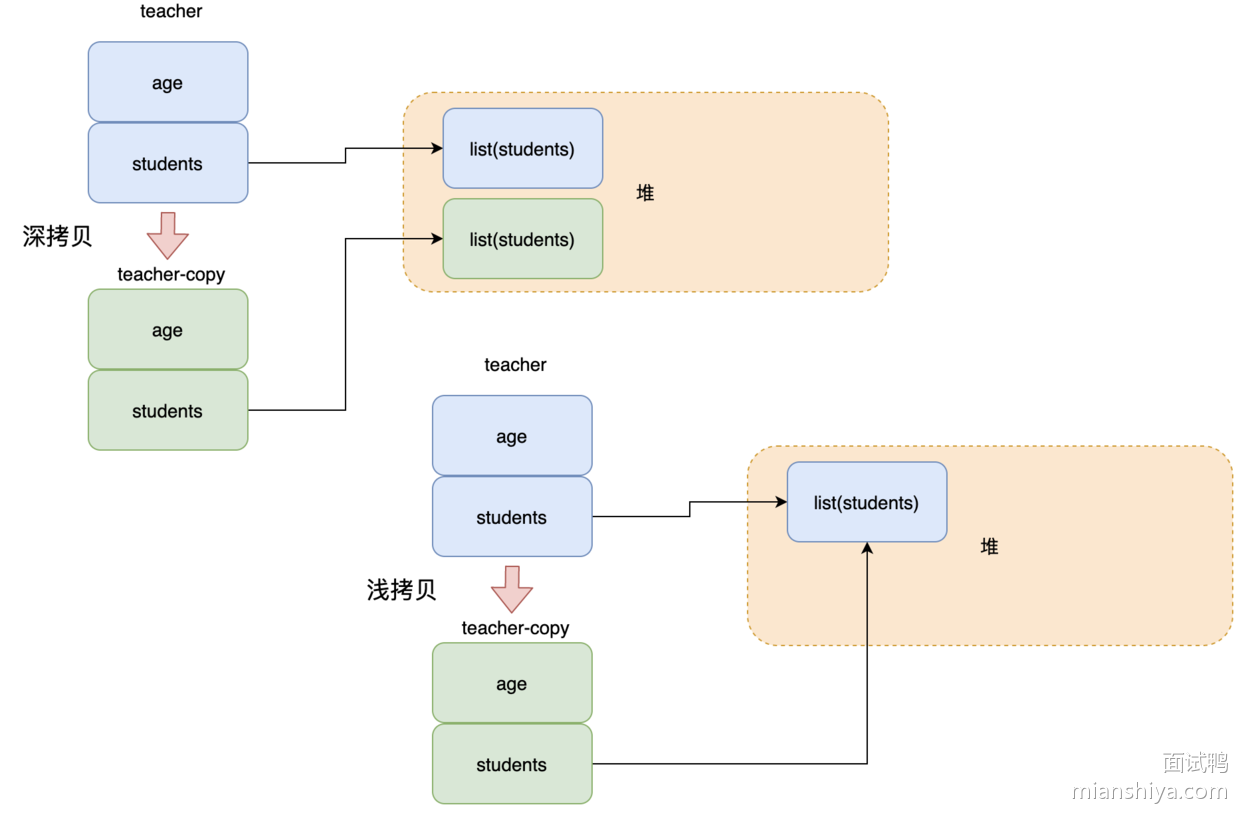
深拷贝和浅拷贝的区别
深拷贝:深拷贝不仅复制对象本身,还递归复制对象中所有引用的对象。这样新对象与原对象完全独立,修改新对象不会影响到原对象。即包括基本类型和引用类型,堆内的引用对象也会复制一份。
浅拷贝:拷贝只复制对象的引用,而不复制引用指向的实际对象。也就是说,浅拷贝创建一个新对象,但它的字段(若是对象类型)指向的是原对象中的相同内存地。
深拷贝创建的新对象与原对象完全独立,任何一个对象的修改都不会影响另一个。而修改浅拷贝对象中引用类型的字段会影响到原对象,因为它们共享相同的引用。
网络通信协议名词解释
以一个点外卖的例子解释什么是IP地址、端口号、Socket和协议。
IP地址:对应的是我们上班所在的一个大楼。
端口号:对应我们所在大楼里的一个具体房间。
Socket:进行通信的一个工具。
协议:通信要遵循的规则。
例子:
IP地址:外卖员要送餐到的大楼(例如:腾讯大楼)。
端口号:外卖员要到大楼里的具体房间(例如:1001)。
Socket:外卖员通过手机(Socket)与我们通信,告知外卖已到。
协议:我们默认使用中文对话。
访问修饰符
- public:完全公开,任何地方都可以访问。
- private:仅限于本类内部访问。
- protected:本类内部及子类可以访问。
- 默认(无修饰符):包内可见,同包下的其他类可以访问。
| 修饰符 | 当前类 | 同一包内 | 子类(不同包) | 其他包 |
|---|---|---|---|---|
| public | 是 | 是 | 是 | 是 |
| protected | 是 | 是 | 是 | 否 |
| 默认(default) | 是 | 是 | 否 | 否 |
| private | 是 | 否 | 否 | 否 |
适用范围区别
public:类、接口、字段、方法、构造函数。protected:字段、方法、构造函数(没有类)。- 默认(包级别):类、字段、方法、构造函数。
private:字段、方法、构造函数(没有类)。
访问修饰符的选择
public:适用于需要被外部类广泛访问的成员。过多使用public可能导致封装性降低。protected:适用于需要在继承关系中使用的成员。它提供了比public更严格的访问控制,但允许子类访问。- 默认(包级别):适用于仅在同一包内使用的类和成员。适当使用可以隐藏实现细节,减少类之间的耦合。
private:适用于内部实现细节,确保类的内部数据和方法不会被外部直接访问。最严格的访问控制,保护类的封装性。
字节码
字节码是编译器将源代码编译后生成的中间表示形式,位于源代码与 JVM 执行的机器码之间。
字节码由 JVM 解释或即时编译(JIT)为机器码执行。
字节码结构:
- Java 字节码是平台无关的指令集,存储在
.class文件中。每个.class文件包含类的定义信息、字段、方法,以及方法对应的字节码指令。
字节码指令集:
- Java 字节码包含一系列指令,如加载、存储、算术运算、类型转换、对象操作、控制流等。常见的指令包括
aload,iload,astore,iadd,if_icmpgt等。
执行过程:
- JVM 通过解释器逐条执行字节码,或通过 JIT 编译器将热点字节码片段即时编译为机器码,提高执行效率。
反射与动态代理:
- 通过 Java 反射 API,可以在运行时动态生成或修改字节码,从而创建代理对象或实现动态方法调用。
字节码增强与框架:
- 许多 Java 框架(如 Hibernate, Spring AOP)使用字节码增强技术,通过修改类的字节码来实现功能增强。常用工具包括 ASM、Javassist、CGLIB 等。
CGLib代理
CGLib 广泛用于AOP(面向切面编程)、动态代理等场景。CGLib通过继承的方式在运行时动态生成子类,以实现对目标对象的方法拦截和增强。下面是一些使用CGLib的基本步骤和示例代码。
CGLib是一个非常强大的工具,适用于需要在运行时动态生成类和方法的场景。通过以下步骤,可以轻松地在你的项目中使用CGLib来实现方法拦截和增强。
注意事项
- 性能:虽然CGLib在大多数情况下性能较好,但在高并发场景下,仍然需要注意性能开销。
- 最终类和方法:CGLib不能为
final类或final方法生成代理,因为它们不能被继承。 - 私有方法:CGLib也不能拦截私有方法,因为子类无法访问父类的私有方法。
1. 引入依赖
首先,你需要在你的项目中引入CGLib的依赖。如果你使用Maven,可以在pom.xml文件中添加如下依赖:
<dependency>
<groupId>cglib</groupId>
<artifactId>cglib</artifactId>
<version>3.3.0</version>
</dependency>2. 定义目标类
假设我们有一个简单的类,我们希望在它的方法调用前后添加一些额外的逻辑。
public class MyService {
public void doSomething() {
System.out.println("Doing something...");
}
}3. 创建MethodInterceptor
CGLib的核心接口是MethodInterceptor,它允许我们在方法调用时进行拦截。
import net.sf.cglib.proxy.MethodInterceptor;
import net.sf.cglib.proxy.MethodProxy;
import java.lang.reflect.Method;
public class MyMethodInterceptor implements MethodInterceptor {
@Override
public Object intercept(Object obj, Method method, Object[] args, MethodProxy proxy) throws Throwable {
System.out.println("Before method: " + method.getName());
// 调用原始方法
Object result = proxy.invokeSuper(obj, args);
System.out.println("After method: " + method.getName());
return result;
}
}4. 创建代理对象
使用CGLib的Enhancer类来创建目标类的子类,并将MethodInterceptor设置为回调。
import net.sf.cglib.proxy.Enhancer;
public class CglibExample {
public static void main(String[] args) {
// 创建Enhancer对象
Enhancer enhancer = new Enhancer();
// 设置目标类
enhancer.setSuperclass(MyService.class);
// 设置回调方法
enhancer.setCallback(new MyMethodInterceptor());
// 创建代理对象
MyService myService = (MyService) enhancer.create();
// 调用方法
myService.doSomething();
}
}5. 运行结果
运行上述代码后,输出将会是:
Before method: doSomething
Doing something...
After method: doSomethingJDK 代理
注意事项
- 接口限制:JDK 动态代理只能为实现了接口的类生成代理对象,如果类没有实现任何接口,则无法使用 JDK 动态代理。
- 性能:JDK 动态代理的性能相对较高,但在高并发场景下,仍然需要注意性能开销。
- 灵活性:JDK 动态代理基于接口,因此在设计时需要考虑接口的使用。
Java 自带的动态代理机制主要通过 java.lang.reflect.Proxy 类和 java.lang.reflect.InvocationHandler 接口来实现。这种代理方式主要用于接口的代理,即只能为实现了某个接口的类生成代理对象。下面是一个详细的示例,展示如何使用 JDK 自带的动态代理。
JDK 自带的动态代理机制是一种简单且强大的工具,适用于需要在运行时动态生成代理对象的场景。通过以下步骤,可以轻松地在你的项目中使用 JDK 动态代理来实现方法拦截和增强。
1. 定义接口和目标类
首先,定义一个接口,这个接口将由目标类和代理类共同实现。
public interface MyService {
void doSomething();
}实现上述接口的目标类。
public class MyServiceImpl implements MyService {
@Override
public void doSomething() {
System.out.println("Doing something...");
}
}2. 创建InvocationHandler
实现 InvocationHandler 接口,这个接口的 invoke 方法将在代理对象的方法被调用时执行。
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
public class MyInvocationHandler implements InvocationHandler {
private final MyService target;
public MyInvocationHandler(MyService target) {
this.target = target;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println("Before method: " + method.getName());
// 调用目标对象的方法
Object result = method.invoke(target, args);
System.out.println("After method: " + method.getName());
return result;
}
}3. 创建代理对象
使用 Proxy.newProxyInstance 方法创建代理对象。
import java.lang.reflect.Proxy;
public class JdkProxyExample {
public static void main(String[] args) {
// 创建目标对象
MyService target = new MyServiceImpl();
// 创建InvocationHandler
MyInvocationHandler handler = new MyInvocationHandler(target);
// 创建代理对象
MyService proxy = (MyService) Proxy.newProxyInstance(
target.getClass().getClassLoader(), // 类加载器
target.getClass().getInterfaces(), // 目标类实现的接口
handler // InvocationHandler
);
// 调用代理对象的方法
proxy.doSomething();
}
}4. 运行结果
运行上述代码后,输出将会是:
深色版本
Before method: doSomething
Doing something...
After method: doSomething------------------设计模式------------------
为什么要用设计模式?
设计模式是一套被预先定义好的解决方案,用于解决软件设计中常见问题,以提高代码的可重用性、可读性和可维护性。
使用设计模式的原因是为了使软件设计更加规范、模块化,从而提升代码的质量,使得软件更容易理解、维护和扩展。
设计模式分类
23种设计模式通常分为三大类,分别是:
- 创建型模式(Creational Patterns)
- 结构型模式(Structural Patterns)
- 行为型模式(Behavioral Patterns)
创建型模式(Creational Patterns)
创建型模式关注对象的创建机制,将对象的创建与使用分离开来,以便让系统更加灵活地决定创建哪个对象。创建型模式可以将对象创建的责任封装起来,从而使系统更加独立于具体的对象创建、组合和表示。
创建型模式包括但不限于:
- 单例模式(Singleton):确保一个类只有一个实例,并提供一个访问它的全局访问点。
- 工厂方法模式(Factory Method):定义一个创建产品对象的接口,让子类决定实例化哪一个类。
- 抽象工厂模式(Abstract Factory):提供一个创建一系列相关或依赖对象的接口,而无需指定它们具体的类。
- 建造者模式(Builder):将一个复杂对象的构建与其表示相分离,使得同样的构建过程可以创建不同的表示。
- 原型模式(Prototype):用原型实例指定创建对象的种类,并通过复制这些原型创建新的对象。
结构型模式(Structural Patterns)
结构型模式关注如何组合类或对象来形成更大的结构。这些模式可以让你的代码更加灵活地组合对象,以便创建出更加复杂的结构。
结构型模式包括但不限于:
- 适配器模式(Adapter):将一个类的接口转换成客户希望的另外一个接口。
- 装饰器模式(Decorator):动态地给一个对象添加一些额外的职责。
- 代理模式(Proxy):为其他对象提供一种代理以控制对这个对象的访问。
- 外观模式(Facade):为子系统中的一组接口提供一个一致的界面。
- 桥接模式(Bridge):将抽象部分与它的实现部分分离,使它们都可以独立地变化。
- 组合模式(Composite):将对象组合成树形结构以表示“部分-整体”的层次结构。
- 享元模式(Flyweight):运用共享技术有效地支持大量细粒度的对象。
行为型模式(Behavioral Patterns)
行为型模式关注对象之间的通信以及职责分配机制。它们描述了对象之间应该如何相互作用以及如何分配职责。
行为型模式包括但不限于:
- 策略模式(Strategy):定义一系列的算法,把它们一个个封装起来,并且使它们可相互替换。
- 模板方法模式(Template Method):定义一个操作中的算法骨架,而将一些步骤延迟到子类中。
- 观察者模式(Observer):定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。
- 迭代器模式(Iterator):提供一种方法访问一个容器对象中各个元素,而又不需暴露该对象的内部细节。
- 责任链模式(Chain of Responsibility):使多个对象都有机会处理请求,从而避免请求的发送者和接收者之间的耦合关系。
- 命令模式(Command):将一个请求封装为一个对象,从而使你可用不同的请求来参数化客户端。
- 备忘录模式(Memento):在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态。
- 状态模式(State):允许一个对象在其内部状态改变时改变它的行为。
- 访问者模式(Visitor):表示一个作用于某对象结构中的各元素的操作。
- 中介者模式(Mediator):用一个中介对象来封装一系列的对象交互。
- 解释器模式(Interpreter):给定一个语言,定义它的文法的一种表示,并定义一个解释器,这个解释器使用该表示来解释语言中的句子。
单例模式
分类:
- 饿汉式单例模式
- 懒汉式单例模式
- 线程安全的懒汉式单例模式
单例模式(Singleton Pattern) 是最简单的创建型设计模式。它的目的是确保一个类只有一个实例存在,并且提供一个全局访问点。
单例模式最重要的特点 是构造函数私有,从而避免外界直接使用构造函数直接实例化该类的对象。
单例模式的优点:
- 在一个对象需要频繁地销毁、创建,而销毁、创建性能又无法优化时,单例模式的优势尤为明显。
- 在一个对象的产生需要较多资源时,如读取配置、产生其他依赖对象时,则可以通过在启动时直接产生一个单例对象,然后用永久驻留内存的方式来解决。
- 单例模式可以避免对资源的多重占用,因为只有一个实例,避免了对一个共享资源的并发操作。
- 单例模式可以在系统设置全局的访问点,优化和共享资源访问。
单例模式的缺点:
- 单例模式无法创建子类,扩展困难,若要扩展,除了修改代码基本上没有第二种途径可以实现。
- 单例模式对测试不利。在并行开发环境中,如果采用单例模式的类没有完成,是不能进行测试的。
- 单例模式与单一职责原则有冲突。一个类应该只实现一个逻辑,而不关心它是否是单例的,是不是要用单例模式取决于环境。
单例模式在 Java 中通常有两种表现形式:
饿汉式单例模式
- 类加载时就进行对象实例化。
public class Singleton {
private static final Singleton instance = new Singleton();
// 构造方法私有,确保外界不能直接实例化
private Singleton() {
}
// 通过公有的静态方法获取对象实例
public static Singleton getInstance() {
return instance;
}
}懒汉式单例模式(线程安全)
- 第一次引用类时才进行对象实例化。
- 线程安全问题:如果线程 A 和 B 同时调用此方法,会出现执行
if (instance == null)语句时都为真的情况,导致创建两个对象。为解决这一问题,可以使用synchronized关键字对静态方法getInstance()进行同步。
public class Singleton2 {
private static Singleton2 instance = null;
// 私有构造方法,确保外界不能直接实例化。
private Singleton2() {
}
// 通过公有的静态方法获取对象实例
public static (synchronized) Singleton2 getInstance() {
if (instance == null) {
instance = new Singleton2();
}
return instance;
}
}比较:饿汉式单例类的速度和反应时间要优于懒汉式单例类,但资源利用率不如懒汉式单例类。
工厂模式
分类:
- 简单工厂模式
- 工厂方法模式
- 抽象工厂模式
工厂模式(Factory Pattern) 是一种创建型设计模式,其主要目的是封装对象创建的细节,使得创建过程更加灵活。工厂模式可以分为三种类型:简单工厂模式、工厂方法模式和抽象工厂模式。
简单工厂模式 实际上并不是严格意义上的设计模式,而是一种编程习惯。它通过定义一个工厂类来创建不同类型的对象,这些对象通常具有共同的父类或接口。
工厂方法模式 是简单工厂模式的进一步发展。在工厂方法模式中,我们不再提供一个统一的工厂类来创建所有的对象,而是针对不同的对象提供不同的工厂。每个对象都有一个与之对应的工厂,工厂方法模式让一个类的实例化延迟到其子类。
抽象工厂模式 是工厂方法模式的进一步深化。在这个模式中,工厂类不仅可以创建一个对象,而是可以创建一组相关或相互依赖的对象。这是与工厂方法模式最大的不同点。抽象工厂模式提供一个创建一系列相关或相互依赖对象的接口,而无需指定它们具体的类。
简单工厂模式
简单工厂模式并不严格属于设计模式,而更多是一种编程习惯。其特点是定义一个工厂类,根据传入的参数不同返回不同的实例。这些实例通常具有共同的父类或接口。
示例代码:
public interface Shape {
void draw();
}public class CircleShape implements Shape {
public CircleShape() {
System.out.println("CircleShape: created");
}
@Override
public void draw() {
System.out.println("draw: CircleShape");
}
}public class RectShape implements Shape {
public RectShape() {
System.out.println("RectShape: created");
}
@Override
public void draw() {
System.out.println("draw: RectShape");
}
}public class TriangleShape implements Shape {
public TriangleShape() {
System.out.println("TriangleShape: created");
}
@Override
public void draw() {
System.out.println("draw: TriangleShape");
}
}public class ShapeFactory {
public static Shape getShape(String type) {
Shape shape = null;
if ("circle".equalsIgnoreCase(type)) {
shape = new CircleShape();
} else if ("rect".equalsIgnoreCase(type)) {
shape = new RectShape();
} else if ("triangle".equalsIgnoreCase(type)) {
shape = new TriangleShape();
}
return shape;
}
}工厂方法模式
工厂方法模式定义了一个创建产品对象的工厂接口,将实际创建工作推迟到子类中。它具有良好的封装性和扩展性,可以降低模块间的耦合度。
示例代码:
public interface Car {
void brand();
void speed();
void price();
}public interface CarFactory {
Car factory();
}public class Audi implements Car {
@Override
public void brand() {
System.out.println("一台奥迪");
}
@Override
public void speed() {
System.out.println("快");
}
@Override
public void price() {
System.out.println("贵");
}
}public class Auto implements Car {
@Override
public void brand() {
System.out.println("一台奥拓");
}
@Override
public void speed() {
System.out.println("慢");
}
@Override
public void price() {
System.out.println("便宜");
}
}public class AudiFactory implements CarFactory {
@Override
public Car factory() {
return new Audi();
}
}public class AutoFactory implements CarFactory {
@Override
public Car factory() {
return new Auto();
}
}public class ClientDemo {
public static void main(String[] args) {
CarFactory carFactory = new AudiFactory();
Car audi = carFactory.factory();
audi.brand();
audi.speed();
audi.price();
carFactory = new AutoFactory();
Car auto = carFactory.factory();
auto.brand();
auto.speed();
auto.price();
}
}抽象工厂模式
抽象工厂模式为创建一组相关或相互依赖的对象提供一个接口,而无需指定它们的具体类。它适用于需要一组对象共同完成某种功能的场景。
示例代码:
interface OperationController {
void control();
}
interface UIController {
void display();
}
class AndroidOperationController implements OperationController {
@Override
public void control() {
System.out.println("AndroidOperationController");
}
}
class AndroidUIController implements UIController {
@Override
public void display() {
System.out.println("AndroidInterfaceController");
}
}
class IosOperationController implements OperationController {
@Override
public void control() {
System.out.println("IosOperationController");
}
}
class IosUIController implements UIController {
@Override
public void display() {
System.out.println("IosInterfaceController");
}
}
class WpOperationController implements OperationController {
@Override
public void control() {
System.out.println("WpOperationController");
}
}
class WpUIController implements UIController {
@Override
public void display() {
System.out.println("WpInterfaceController");
}
}
interface SystemFactory {
OperationController createOperationController();
UIController createInterfaceController();
}
class AndroidFactory implements SystemFactory {
@Override
public OperationController createOperationController() {
return new AndroidOperationController();
}
@Override
public UIController createInterfaceController() {
return new AndroidUIController();
}
}
class IosFactory implements SystemFactory {
@Override
public OperationController createOperationController() {
return new IosOperationController();
}
@Override
public UIController createInterfaceController() {
return new IosUIController();
}
}
class WpFactory implements SystemFactory {
@Override
public OperationController createOperationController() {
return new WpOperationController();
}
@Override
public UIController createInterfaceController() {
return new WpUIController();
}
}策略模式
策略模式(Strategy Pattern) 是一种行为设计模式,它使你能在运行时改变对象的行为。策略模式定义了一系列算法,并将每一个算法封装起来,使它们可以互相替换。
策略模式允许在运行时改变算法的行为。它定义了包含算法族的接口,并且将算法的责任委托给一个子类。
// 定义策略类型枚举类
public enum PointsSuitScenesEnum {
BOOK_TEST("书籍测试", 1),
LEVEL_FIGHT("阅读闯关", 2);
private final String sceneName;
private final int sceneId;
PointsSuitScenesEnum(String sceneName, int sceneId) {
this.sceneName = sceneName;
this.sceneId = sceneId;
}
public String getSceneName() {
return sceneName;
}
public int getSceneId() {
return sceneId;
}
public void printInfo() {
System.out.println("sceneName: " + sceneName);
System.out.println("sceneId: " + sceneId);
}
}// 定义策略接口
public interface IPointsStrategy {
// 获取积分类型
PointsSuitScenesEnum getPointsSuitScene();
// 积分操作
void operaPoints(String userId, int points);
}// 策略实现类 A
public class BookTestPointsReslove implements IPointsStrategy {
@Override
public PointsSuitScenesEnum getPointsSuitScene() {
return PointsSuitScenesEnum.BOOK_TEST;
}
@Override
public void operaPoints(String userId, int points, int operateType) {
PointsUtils.handlePoints(userId, points, operateType, getPointsSuitScene());
}
}
// 策略实现类 B
public class LevelFightPointsReslove implements IPointsStrategy {
@Override
public PointsSuitScenesEnum getPointsSuitScene() {
return PointsSuitScenesEnum.LEVEL_FIGHT;
}
@Override
public void operaPoints(String userId, int points, int operateType) {
PointsUtils.handlePoints(userId, points, operateType, getPointsSuitScene());
}
}
// 积分工具类
public class PointsUtils {
public static void handlePoints(String userId, int points, int operateType, String operationName) {
if (operateType == 1) {
System.out.println(operationName + "加分:userId=" + userId + " points=" + points);
} else if (operateType == 0) {
System.out.println(operationName + "减分:userId=" + userId + " points=" + points);
}
}
}// 配置类,注入Bean
@Configuration
public class PointsStrategyConfig {
@Bean
public PointsService pointsService() {
return new PointsService();
}
@Bean
public BookTestPointsReslove scene1PointsStrategy() {
return new BookTestPointsReslove();
}
@Bean
public LevelFightPointsReslove scene2PointsStrategy() {
return new LevelFightPointsReslove();
}
}// 业务接口
public interface IPointsService {
void addPoints(Long userId, int points, PointsSuitScenesEnum scene);
void subtractPoints(Long userId, int points, PointsSuitScenesEnum scene);
}
// 业务实现类
@Service
public class PointsService implements IPointsService, ApplicationContextAware {
private final Map<PointsSuitScenesEnum, IPointsStrategy> map = new ConcurrentHashMap<>();
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
Map<String, IPointsStrategy> tempMap = applicationContext.getBeansOfType(IPointsStrategy.class);
tempMap.forEach((k, v) -> {
map.put(v.getPointsSuitScene(), v);
System.out.println(k + " " + v);
});
}
@Override
public void addPoints(Long userId, int points, PointsSuitScenesEnum scene) throws Exception {
IPointsStrategy strategy = map.get(scene);
if (ObjectUtils.isEmpty(strategy)) {
throw new Exception("No strategy found for scene: " + scene);
}
strategy.operaPoints(userId.toString(), points, 1);
}
@Override
public void subtractPoints(Long userId, int points, PointsSuitScenesEnum scene) throws Exception {
IPointsStrategy strategy = map.get(scene);
if (ObjectUtils.isEmpty(strategy)) {
throw new Exception("No strategy found for scene: " + scene);
}
strategy.operaPoints(userId.toString(), points, 0);
}
}// 使用策略模式
public class PointsController {
public static void main(String[] args) throws Exception {
// (实际项目中在SpringBootApplication中就做好了,不需要手动获取Bean)
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(PointsStrategyConfig.class);
PointsService pointsService = context.getBean(PointsService.class);
context.close();
// 虽然调用的接口不同,但是实际上运行的是同一套代码
// 加分
pointsService.addPoints(1L, 100, PointsSuitScenesEnum.BOOK_TEST);
pointsService.addPoints(2L, 200, PointsSuitScenesEnum.LEVEL_FIGHT);
// 减分
pointsService.subtractPoints(1L, 100, PointsSuitScenesEnum.BOOK_TEST);
pointsService.subtractPoints(2L, 200, PointsSuitScenesEnum.LEVEL_FIGHT);
}
}责任链模式
**责任链模式(Chain of Responsibility Pattern)**能够将请求沿着处理者的链进行发送。收到请求后,每个处理者均可对请求进行处理,或将其传递给链上的下一个处理者。
假设我们有一个系统,需要处理不同级别的日志消息(debug、info、warning、error)。
// 抽象处理者类
abstract class LogHandler {
protected LogHandler nextHandler;
public void setNextHandler(LogHandler handler) {
this.nextHandler = handler;
}
public abstract void handleLog(String level, String message);
}
// 具体处理者类
class DebugLogHandler extends LogHandler {
@Override
public void handleLog(String level, String message) {
if ("debug".equals(level)) {
System.out.println("[DEBUG] " + message);
} else if (nextHandler != null) {
nextHandler.handleLog(level, message);
}
}
}
class InfoLogHandler extends LogHandler {
@Override
public void handleLog(String level, String message) {
if ("info".equals(level)) {
System.out.println("[INFO] " + message);
} else if (nextHandler != null) {
nextHandler.handleLog(level, message);
}
}
}
class WarningLogHandler extends LogHandler {
@Override
public void handleLog(String level, String message) {
if ("warning".equals(level)) {
System.out.println("[WARNING] " + message);
} else if (nextHandler != null) {
nextHandler.handleLog(level, message);
}
}
}
class ErrorLogHandler extends LogHandler {
@Override
public void handleLog(String level, String message) {
if ("error".equals(level)) {
System.out.println("[ERROR] " + message);
}
}
}
// 客户端代码
public class Client {
public static void main(String[] args) {
LogHandler debugHandler = new DebugLogHandler();
LogHandler infoHandler = new InfoLogHandler();
LogHandler warningHandler = new WarningLogHandler();
LogHandler errorHandler = new ErrorLogHandler();
debugHandler.setNextHandler(infoHandler);
infoHandler.setNextHandler(warningHandler);
warningHandler.setNextHandler(errorHandler);
debugHandler.handleLog("debug", "This is a debug message.");
debugHandler.handleLog("info", "This is an info message.");
debugHandler.handleLog("warning", "This is a warning message.");
debugHandler.handleLog("error", "This is an error message.");
}
}模板方法模式
模板方法模式(Template Method Pattern)定义了一些基本步骤,并让子类实现某些步骤。它允许子类重写某些步骤而不改变整个算法。
假设我们需要设计一个游戏框架,其中包含一些固定的流程,但每个游戏的具体实现不同。
abstract class Game {
public void playGame() {
makePreparation();
play();
cleanUp();
// 子类可以覆盖此方法以添加额外的步骤
additionalSteps();
}
protected abstract void makePreparation();
protected abstract void play();
protected abstract void cleanUp();
protected void additionalSteps() {
// 默认为空操作
}
}
class Chess extends Game {
@Override
protected void makePreparation() {
System.out.println("Setting up the chess board...");
}
@Override
protected void play() {
System.out.println("Playing the game...");
}
@Override
protected void cleanUp() {
System.out.println("Cleaning up the chess board...");
}
@Override
protected void additionalSteps() {
System.out.println("Saving game state...");
}
}
class Poker extends Game {
@Override
protected void makePreparation() {
System.out.println("Shuffling the cards...");
}
@Override
protected void play() {
System.out.println("Playing poker...");
}
@Override
protected void cleanUp() {
System.out.println("Putting away the cards...");
}
}
// 客户端代码
public class Client {
public static void main(String[] args) {
Game chess = new Chess();
chess.playGame();
System.out.println();
Game poker = new Poker();
poker.playGame();
}
}观察者模式
观察者模式(Observer Pattern)允许对象在状态发生变化时通知多个观察者对象,而无需使对象知道观察者是谁。
假设我们有一个天气预报系统,需要实时更新天气信息,并通知不同的观察者(如用户界面、天气API等)。
interface Observer {
void update(String weatherInfo);
}
interface Subject {
void registerObserver(Observer o);
void removeObserver(Observer o);
void notifyObservers(String weatherInfo);
}
class WeatherStation implements Subject {
private List<Observer> observers = new ArrayList<>();
private String weatherInfo;
@Override
public void registerObserver(Observer o) {
observers.add(o);
}
@Override
public void removeObserver(Observer o) {
observers.remove(o);
}
@Override
public void notifyObservers(String weatherInfo) {
this.weatherInfo = weatherInfo;
for (Observer observer : observers) {
observer.update(weatherInfo);
}
}
public void setWeatherInfo(String info) {
notifyObservers(info);
}
}
class CurrentConditionsDisplay implements Observer {
@Override
public void update(String weatherInfo) {
System.out.println("Current Conditions Display: " + weatherInfo);
}
}
class ForecastDisplay implements Observer {
@Override
public void update(String weatherInfo) {
System.out.println("Forecast Display: " + weatherInfo);
}
}
// 客户端代码
public class Client {
public static void main(String[] args) {
WeatherStation weatherStation = new WeatherStation();
Observer currentConditionsDisplay = new CurrentConditionsDisplay();
Observer forecastDisplay = new ForecastDisplay();
weatherStation.registerObserver(currentConditionsDisplay);
weatherStation.registerObserver(forecastDisplay);
weatherStation.setWeatherInfo("Sunny");
weatherStation.setWeatherInfo("Rainy");
weatherStation.removeObserver(forecastDisplay);
weatherStation.setWeatherInfo("Cloudy");
}
}适配器模式
适配器模式(Adapter Pattern) 是一种结构型设计模式,它能让不兼容的接口协同工作。适配器模式充当了两个不同接口之间的桥梁。
适配器模式让两个没有关联的接口能够一起工作。适配器通过包装一个类的方法来实现所需的目标接口。
// 目标接口
public interface Target {
void request();
}
// 被适配的类
class Adaptee {
public void specificRequest() {
System.out.println("Adaptee's specific request.");
}
}
// 适配器类
class Adapter implements Target {
private Adaptee adaptee;
public Adapter() {
this.adaptee = new Adaptee();
}
@Override
public void request() {
adaptee.specificRequest();
}
}
// 使用适配器模式的客户端代码
public class Client {
public static void main(String[] args) {
Target target = new Adapter();
target.request(); // 输出: Adaptee's specific request.
}
}装饰器模式
装饰器模式(Decorator Pattern) 是一种结构型设计模式,它允许向部分对象添加新的功能,同时不会影响其他对象的功能。装饰器模式可以动态地给一个对象添加一些额外的责任。
装饰器模式允许你给对象动态地添加职责,而无需修改对象本身的结构。它是继承关系的一个替代方案。
// 组件接口
public abstract class Component {
public abstract void operation();
}
// 具体组件
class ConcreteComponent extends Component {
@Override
public void operation() {
System.out.println("ConcreteComponent operation");
}
}
// 装饰器基类
public abstract class Decorator extends Component {
protected Component component;
public Decorator(Component component) {
this.component = component;
}
@Override
public void operation() {
component.operation();
}
}
// 具体装饰器 A
class ConcreteDecoratorA extends Decorator {
public ConcreteDecoratorA(Component component) {
super(component);
}
@Override
public void operation() {
super.operation();
add Responsibilities();
}
private void add Responsibilities() {
System.out.println("ConcreteDecoratorA added responsibilities");
}
}
// 具体装饰器 B
class ConcreteDecoratorB extends Decorator {
public ConcreteDecoratorB(Component component) {
super(component);
}
@Override
public void operation() {
super.operation();
add Responsibilities();
}
private void add Responsibilities() {
System.out.println("ConcreteDecoratorB added responsibilities");
}
}
// 使用装饰器模式的客户端代码
public class Client {
public static void main(String[] args) {
Component component = new ConcreteComponent();
component.operation(); // 输出: ConcreteComponent operation
component = new ConcreteDecoratorA(component);
component.operation(); // 输出: ConcreteComponent operation ConcreteDecoratorA added responsibilities
component = new ConcreteDecoratorB(component);
component.operation(); // 输出: ConcreteComponent operation ConcreteDecoratorA added responsibilities ConcreteDecoratorB added responsibilities
}
}---------------------集合---------------------
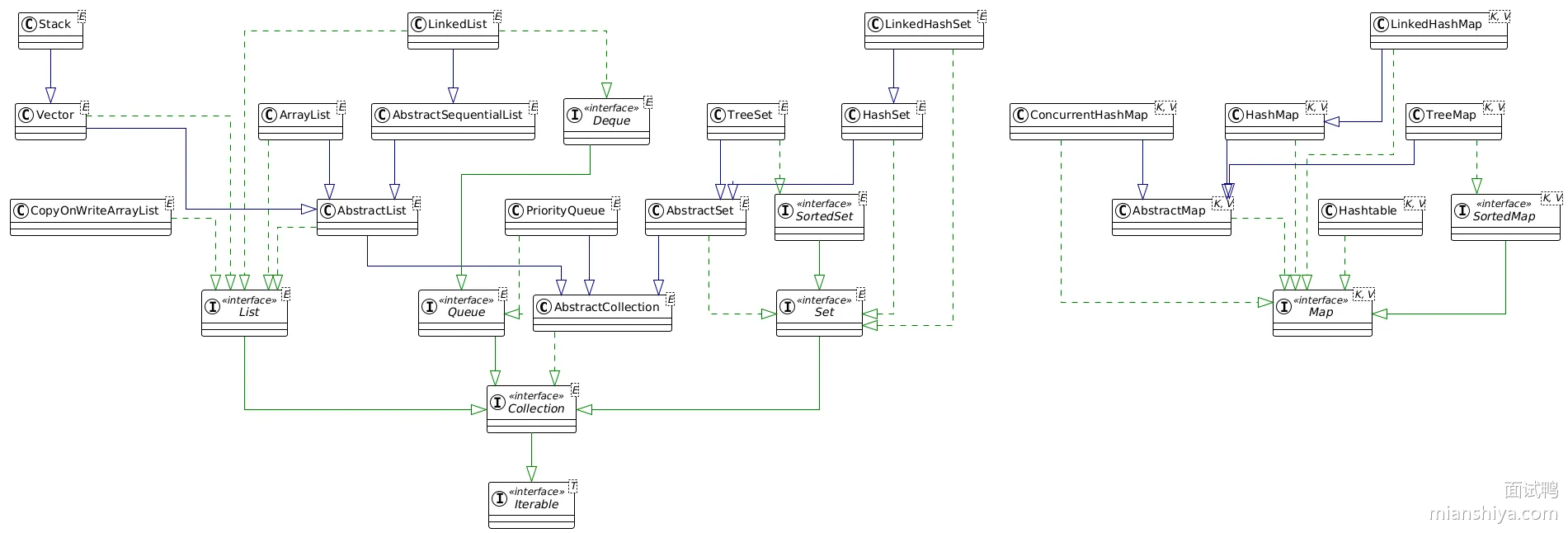
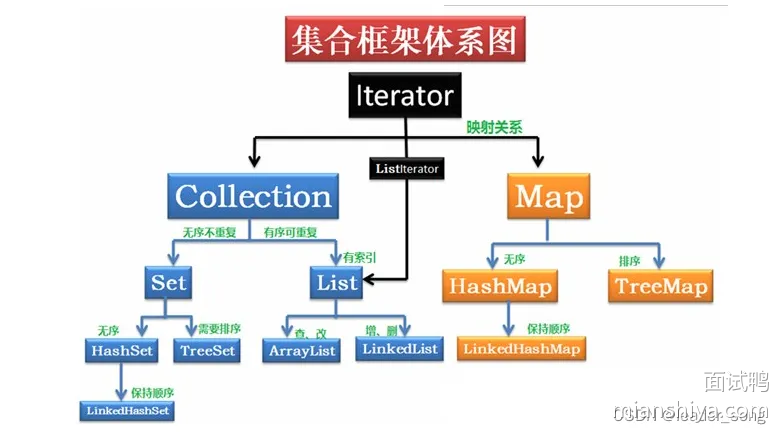
Collection 家族
List 接口
- ArrayList:基于动态数组,查询速度快,插入、删除慢。
- LinkedList:基于双向链表,插入、删除快,查询速度慢。
- Vector:线程安全的动态数组,类似于 ArrayList,但开销较大。
Set 接口
- HashSet:基于哈希表,元素无序,不允许重复。
- LinkedHashSet:基于链表和哈希表,维护插入顺序,不允许重复。
- TreeSet:基于红黑树,元素有序,不允许重复。
Queue 接口
- PriorityQueue:基于优先级堆,元素按照自然顺序或指定比较器排序。
- LinkedList:可以作为队列使用,支持 FIFO(先进先出)操作。
Map 接口
- HashMap:基于哈希表,键值对无序,不允许键重复。
- LinkedHashMap:基于链表和哈希表,维护插入顺序,不允许键重复。
- TreeMap:基于红黑树,键值对有序,不允许键重复。
- Hashtable:线程安全的哈希表,不允许键或值为 null。
- ConcurrentHashMap:线程安全的哈希表,适合高并发环境,不允许键或值为 null。
ArrayList
ArrayList 和 LinkedList
底层数据结构
ArrayList 底层是动态数组,支持下标查询,寻址公式是:
baseAddress+i*dataTypeSize,计算下标的内存地址效率较高LinkedList 底层是双向链表
操作数据效率
- ArrayList支持下标查询, LinkedList不支持下标查询
- 查询: ArrayList下标查询的时间复杂度是O(1),两者顺序查询的时间复杂度都是O(n)
- 写操作:
- ArrayList尾部操作,时间复杂度是O(1);其他部分增删需要挪动数组,时间复杂度是O(n)
- LinkedList头尾操作,时间复杂度是O(1),其他都需要遍历链表,时间复杂度是O(n)
内存空间占用
ArrayList底层是数组,内存连续,节省内存
LinkedList 是双向链表需要存储数据,和两个指针,更占用内存
线程不安全
ArrayList和LinkedList都不是线程安全的
如果需要保证线程安全,有两种方案:
在方法内使用局部变量
使用
Collections.synchronizedListjavaList syncArrayList = Collections.synchronizedList(new ArrayList(); List syncLinkedList = Collections.synchronizedList(new LinkedList());
ArrayList 的扩容原理
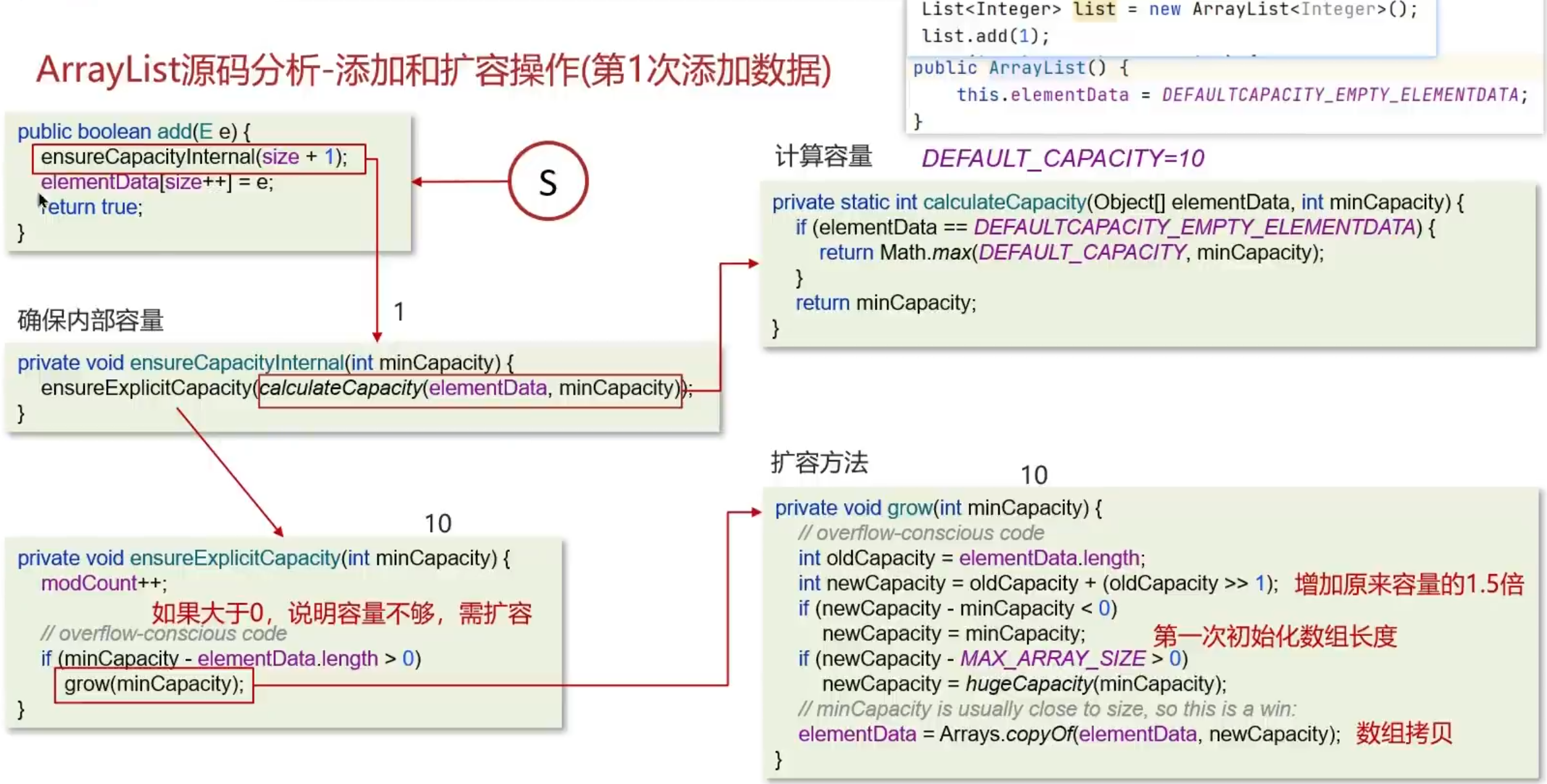

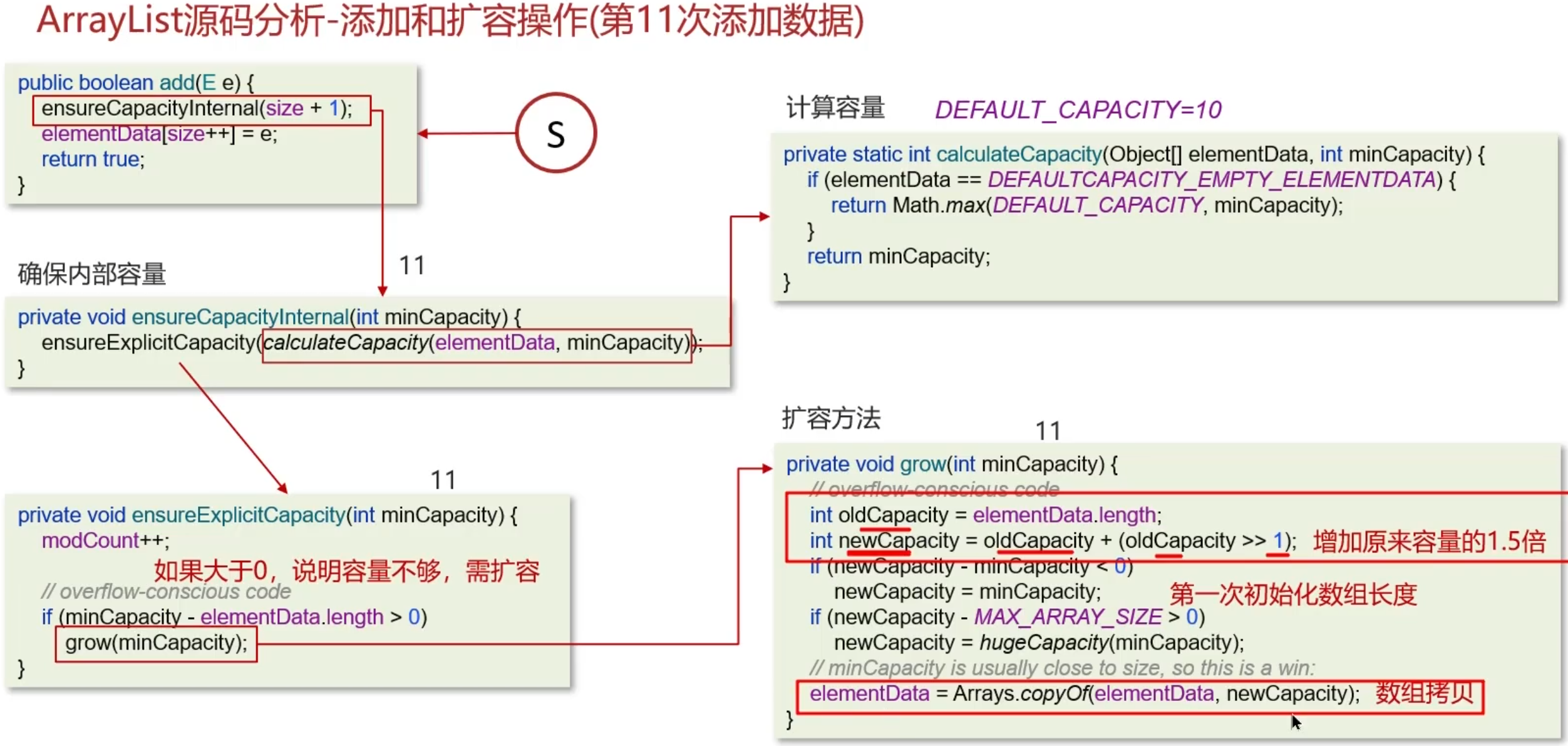
ArrayList 的底层实现原理
ArrayList底层是用动态的数组实现的
ArrayList初始容量为0,当第一次添加数据的时候才会初始化容量为10
ArrayList在进行扩容的时候是原来容量的1.5倍,每次扩容都需要拷贝数组
ArrayList在添加数据的时候
- 确保数组已使用长度(size)加1之后足够存下下一个数据
- 计算数组的容量,如果当前数组已使用长度+1后的大于当前的数组长度,则调用grow方法扩容(原来的1.5倍)
- 确保新增的数据有地方存储之后,则将新元素添加到位于size的位置上
- 返回添加成功布尔值。
Array 和 List 之间的转换
//数组转列表
//Arrays.asList()的数据会受影响
public static void testArray2List(){
String[] strs = {"aaa","bbb","ccc"};
List<String> list = Arrays.asList(strs);
for (String s : list) {
System.out.println(s);
}
}
//列表转数组
//list.toArray()的数据不会受影响
public static void testList2Array(){
List<String> list = new ArrayList<String>();
list.add("aaa");
list.add("bbb");
list.add("ccc");
String[] array = list.toArray(new String[list.size()]);
//String[] array = list.toArray(new String[0]);
for (String s : array) {
System.out.println(s);
}
}HashMap
实现原理
HashMap的数据结构: 底层使用hash表数据结构,即数组和链表或红黑树
当我们往HashMap中put元素时,利用key的hashCode重新hash计算出当前对象的元素在数组中的下标
存储时,如果出现hash值相同的key,此时有两种情况。
a. 如果key相同,则覆盖原始值;
b. 如果key不同(出现冲突),则将当前的key-value放入链表或红黑树中
获取时,直接找到hash值对应的下标,在进一步判断key是否相同,从而找到对应值。
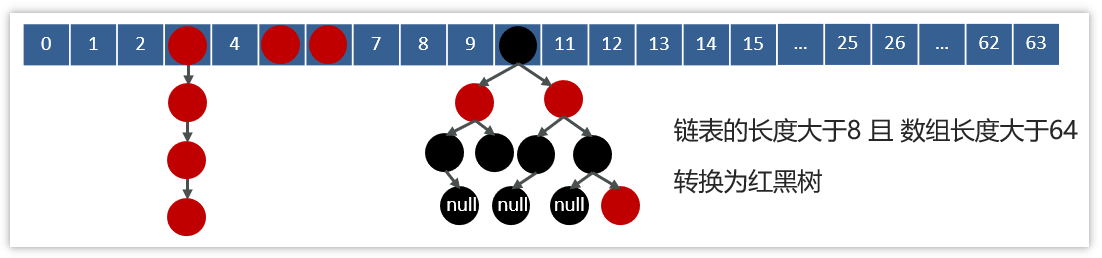
面试官追问:HashMap的jdk1.7和jdk1.8有什么区别
JDK1.8之前采用的是拉链法。拉链法:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
jdk1.8在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8) 时并且数组长度达到64时,将链表转化为红黑树,以减少搜索时间。扩容 resize( ) 时,红黑树拆分成的树的结点数小于等于临界值6个,则退化成链表
添加元素
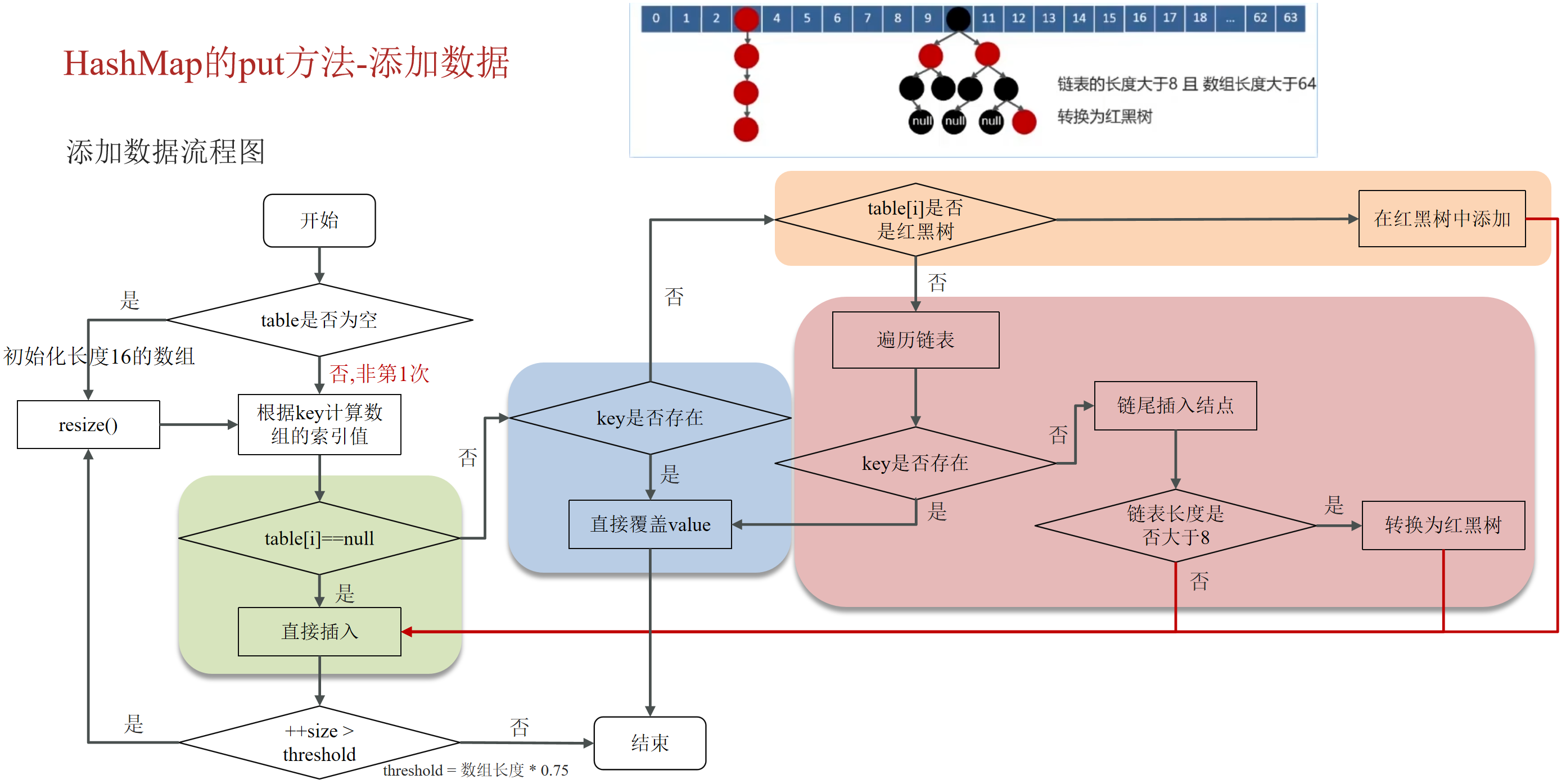
- 判断键值对数组table是否为空或为null,否则执行resize(进行扩容 (初始化)
- 根据键值key计算hash值得到数组索引
- 判断table[i] == null,直接新建节点添加
- 如果table[i] != null,进行判断
- 判断table[i]的首个元素是否和key一样,如果相同直接覆盖value
- 判断table[i] 是否为treeNode,即table[i] 是否是红黑树,如果是红黑树,则直接在树中插入键值对
- 遍历table[i],链表的尾部插入数据,然后判断链表长度是否大于8,大于8的话把链表转换为红黑树,在红黑树中执行插入操作,遍历过程中若发现key已经存在直接覆盖value
- 插入成功后,判断实际存在的键值对数量size是否超多了最大容量threshold(数组长度*0.75),如果超过,进行扩容。
扩容原理
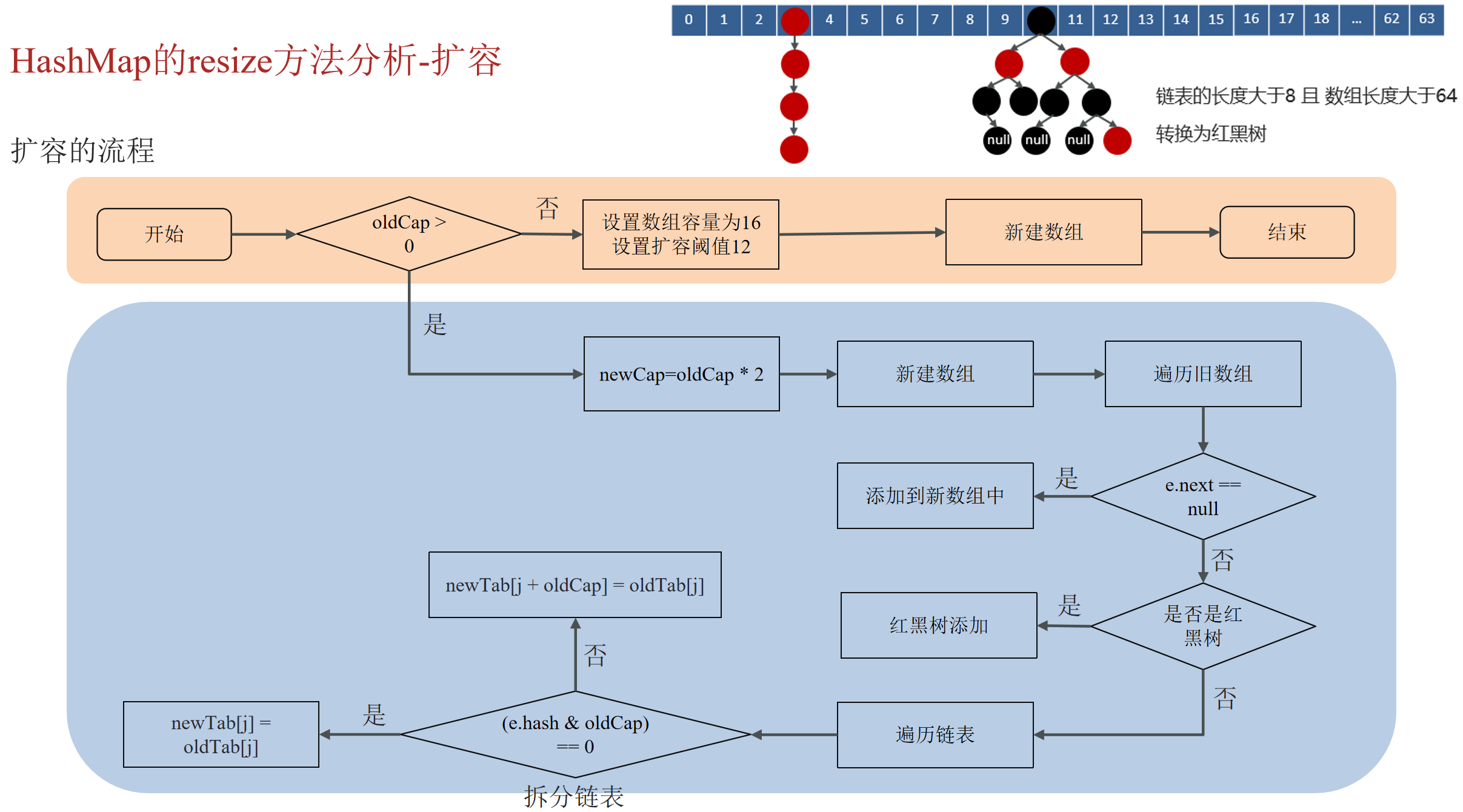
- 在添加元素或初始化的时候需要调用resize方法进行扩容,第一次添加数据初始化数组长度为16,以后每次每次扩容都是达到了扩容阈值 (数组长度*0.75)
- 每次扩容的时候,都是扩容之前容量的2倍
- 扩容之后,会新创建一个数组,需要把老数组中的数据挪动到新的数组中
- 没有hash冲突的节点,则直接使用e.hash &(newCap-1)计算新数组的索引位置
- 如果是红黑树,走红黑树的添加
- 如果是链表,则需要遍历链表,可能需要拆分链表,判断(e.hash & oldCap)是否为0,该元素的位置要么停留在原始位置,要么移动到原始位置+增加的数组大小这个位置上
寻址算法
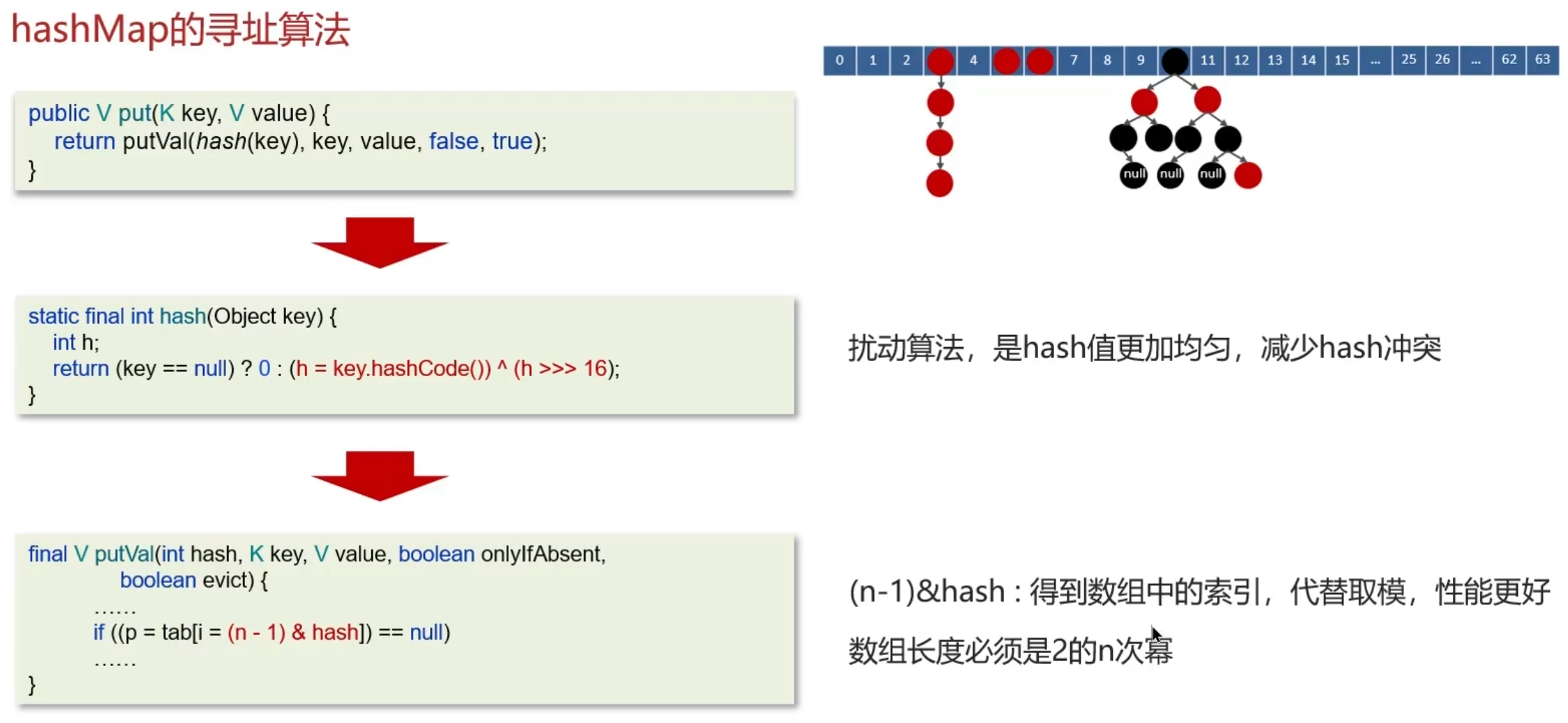
- 计算对象的 hashCode()
- 调用 hash() 方法进行二次哈希, hashcode值右移16位再异或运算,让哈希分布更为均匀
- 最后 (capacity – 1) & hash 得到索引
hashCode() 和 equals() 的重要性
HashMap 的键必须实现 hashCode() 和 equals() 方法。hashCode() 用于计算哈希值,以决定键的存储位置,而 equals() 用于比较两个键是否相同。在 put 操作时,如果两个键的 hashCode() 相同,但 equals() 返回 false,则这两个键会被视为不同的键,存储在同一个桶的不同位置。在 get 操作时,可能会找不到键。
为什么HashMap的长度一定是2的次幂?
- 计算索引时效率更高:位运算的效率高于取模运算(
hash % n),提高了哈希计算的速度。 - 扩容时重新计算索引效率更高: 扩容时只需通过简单的位运算判断是否需要迁移,这减少了重新计算哈希值的开销,提升了 rehash 的效率。(hash & oldCap == 0 的元素留在原来位置 ,否则新位置 = 旧位置 + oldCap)
Java 1.7的多线程死循环问题(简略版)
原因: Java1.7的HashMap中在数组进行扩容的时候,因为链表是头插法,在进行数据迁移的过程中,有可能导致死循环
比如说,现在有两个线程
线程一:读取到当前的hashmap数据,数据中一个链表,在准备扩容时,线程二介入
线程二:也读取hashmap,直接进行扩容。因为是头插法,链表的顺序会进行颠倒过来。比如原来的顺序是AB,扩容后的顺序是BA,线程二执行结束。
线程一:继续执行的时候就会出现死循环的问题。
线程一先将A移入新的链表,再将B插入到链头,由于另外一个线程的原因,B的next指向了A,所以B->A->B,形成循环。
解决办法:Java 1.8 调整了扩容算法,不再将元素加入链表头(而是保持与扩容前一样的顺序),采用尾插法避免了jdk7中死循环的问题。
Hash家族对比
HashMap 和 HashSet 的区别
- HashSet实现了Set接口,仅存储对象;HashMap实现了 Map接口,存储的是键值对。
- HashSet底层其实是用HashMap实现存储的,HashSet封装了一系列HashMap的方法。依靠HashMap来存储元素值,利用hashMap的key键进行存储,而value值默认为Object对象。所以HashSet也不允许出现重复值,判断标准和HashMap判断标准相同,两个元素的hashCode相等并且通过equals()方法返回true。首先根据hashCode方法计算出对象存放的地址位置,然后使用equals方法比较两个对象是否真的相同

HashMap 和 HashTabe 的区别
在实际开中不建议使用HashTable,在多线程环境下可以使用ConcurrentHashMap类
| 区别 | HashTable | HashMap |
|---|---|---|
| 数据结构 | 数组+链表 | 数组+链表+红黑树 |
| 是否可以为null | Key和value都不能为null | 可以为null |
| hash算法 | key的hashCode() | 二次hash |
| 扩容方式 | 当前容量翻倍 + 1 | 当前容量翻倍 |
| 线程安全 | 同步(synchronized)的,线程安全 | 线程不安全 |
ConcurrentHashMap
底层数据结构
JDK1.7采用分段的数组+链表实现
JDK1.8 采用与HashMap 一样的结构,数组+链表/红黑二叉树
线程安全的原因(1.7 和 1.8 之间的区别)
- 1.7——分段锁:JDK1.7采用Segment分段锁,通过将数据分割成多个段,底层使用的是ReentrantLock。当需要修改某个段内的数据时,只需要锁定该段即可,而不需要锁定整个哈希表。
- 1.8——CAS + synchronized:JDK1.8改用
volatile去同步每个桶上的数据。在put操作时,如果桶上的元素数量小于等于 1,那么就直接用CAS 操作来替换旧元素或者增加新元素;如果桶上的元素数量大于 1,则转为使用synchronized锁来保证线程安全。采用synchronized锁定链表或红黑二叉树的头节点,相对Segment分段锁粒度更细,性能更好。 - 非阻塞迭代算法:允许读写并发,
ConcurrentHashMap的迭代器在读取数据时不会持有锁,因此不会影响其他线程的写操作。 - 懒惰扩容:扩容时
ConcurrentHashMap并不会一次性锁定整个表,而是只锁定需要迁移的部分桶,从而减少了锁的竞争。 - 链表转红黑树:Java 8 中的
ConcurrentHashMap还引入了链表树化的机制。当链表长度达到一定阈值时,链表会被转换为红黑树,从而提高查找效率。这种转换是局部的,只针对那些过长的链表。
添加元素
- 加锁,但锁的范围仅精确到 bucket 的头节点,而非整个数据结构。
- 这种细粒度的锁机制确保了高并发环境下插入操作的高效执行。
扩容原理
- 加锁,但仅锁定涉及迁移的头节点。
- 支持多线程并行进行扩容操作,通过CAS操作竞争获取迁移任务,每个线程负责一部分槽位的数据转移。
- 获得任务的线程将原数组中对应链表或红黑树的数据迁移到新数组,进一步提升了扩容时的并发处理能力。
查找元素
- 非阻塞,不加锁,直接访问,保证了快速响应。
- 在扩容期间也不中断查找,若槽未迁移,则直接从旧数组读取;若已迁移完成,通过扩容线程设置的转发节点指引,从新数组中定位数据,确保了查找操作的连续性和高效性。
---------------------并发---------------------

并发概念
并发、并行的区别
- 并发:两个及两个以上的作业在同一 时间段 内执行。
- 并行:两个及两个以上的作业在同一 时刻 执行。
最关键的点是:是否是 同时 执行。
同步、异步的区别
- 同步:发出一个调用之后,在没有得到结果之前, 该调用就不可以返回,一直等待。
- 异步:调用在发出之后,不用等待返回结果,该调用直接返回。
进程、线程、协程
进程是程序的一次执行过程,是系统运行程序的基本单位,因此进程是动态的。
系统运行一个程序即是一个进程从创建,运行到消亡的过程。
线程与进程相似,但线程是一个比进程更小的执行单位。
一个进程在其执行的过程中可以产生多个线程。
多个线程共享进程的堆和方法区资源,但每个线程有自己的程序计数器、虚拟机栈和本地方法栈。
协程(Coroutine)是一种轻量级的线程,它允许在执行中暂停并在之后恢复执行,而无需阻塞线程。
与线程相比,协程是用户态调度,效率更高,因为它不涉及操作系统内核调度。
协程的特点:
- 轻量级:与传统线程不同,协程在用户态切换,不依赖内核态的上下文切换,避免了线程创建、销毁和切换的高昂成本。
- 非抢占式调度:协程的切换由程序员控制,可以通过显式的
yield或await来暂停和恢复执行,避免了线程中断问题。 - 异步化编程:协程可以让异步代码写得像同步代码一样,使代码结构更加简洁清晰。
Java 一开始没有原生支持协程,但在 Java 19 中通过 Project Loom 引入了虚拟线程(Virtual Threads),最终在 Java 21 中确认。它提供了类似协程的功能。虚拟线程可以被认为是 Java 对协程的一种实现,虽然实现原理与传统协程略有不同,但它实现了高效并发。
示例代码:
1)创建虚拟线程
public class VirtualThreadDemo {
public static void main(String[] args) throws InterruptedException {
Thread virtualThread = Thread.ofVirtual().start(() -> {
System.out.println("This is a virtual thread!");
});
virtualThread.join(); // 等待虚拟线程结束
}
}2)虚拟线程执行并发任务
public class VirtualThreadExecutorDemo {
public static void main(String[] args) {
// 创建一个虚拟线程执行器
try (ExecutorService executor = Executors.newVirtualThreadPerTaskExecutor()) {
for (int i = 0; i < 1000; i++) {
executor.submit(() -> {
System.out.println(Thread.currentThread());
});
}
}
}
}3) 与同步 I/O 的结合
public class VirtualThreadWithIO {
public static void main(String[] args) throws InterruptedException {
Thread vThread = Thread.ofVirtual().start(() -> {
try {
Thread.sleep(1000); // 虚拟线程的阻塞操作不会影响性能
System.out.println("Completed sleep in virtual thread");
} catch (InterruptedException e) {
e.printStackTrace();
}
});
vThread.join();
}
}进程、线程的区别
- 线程是进程划分成的更小的运行单位。
- 各进程是独立的,而各线程则不一定,
- 同一进程中的线程极有可能会相互影响。
- 线程执行开销小,但不利于资源的管理和保护;而进程正相反。
协程、线程的区别
调度方式:
- 线程:由操作系统调度,切换线程时会涉及上下文切换和内核态的开销。
- 协程:由程序调度,在用户态切换,没有上下文切换的开销,性能更高。
阻塞与非阻塞:
- 线程:通常采用阻塞模型(例如,I/O 操作会阻塞当前线程)。
- 协程:是非阻塞的,I/O 等操作会挂起协程,而不是整个线程,因此不会阻塞其他协程的执行。
资源占用:
- 线程:每个线程需要分配栈空间,且栈大小固定,导致线程资源消耗较大。
- 协程:协程的栈空间可以动态增长,内存开销远小于线程。
协程的应用场景
- 高并发服务:协程特别适合处理大量并发请求的服务,例如 Web 服务、微服务架构等。
- 异步 I/O 操作:协程能够有效处理异步 I/O 操作而不阻塞主线程,提高 I/O 密集型应用的性能。
- 游戏开发:协程常用于游戏开发中的脚本和动画控制,因为协程提供了暂停和恢复执行的能力,能够实现复杂的游戏逻辑。
乐观锁、悲观锁
乐观锁:总是假设最好的情况,认为共享资源每次被访问的时候不会出现问题,线程可以不停地执行,无需加锁也无需等待,只是在提交修改的时候去验证对应的资源(也就是数据)是否被其它线程修改了(版本号机制或 CAS 算法)。
悲观锁:悲观锁总是假设最坏的情况,认为共享资源每次被访问的时候就会出现问题(比如共享数据被修改),所以每次在获取资源操作的时候都会上锁,这样其他线程想拿到这个资源就会阻塞直到锁被上一个持有者释放。也就是说,共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程。
像 Java 中 synchronized 和 ReentrantLock 等独占锁就是悲观锁思想的实现。
如何实现乐观锁
- 版本号机制
一般是在数据表中加上一个数据版本号 version 字段,表示数据被修改的次数。当数据被修改时,version 值会加一。当线程 A 要更新数据值时,在读取数据的同时也会读取 version 值,在提交更新时,若刚才读取到的 version 值为当前数据库中的 version 值相等时才更新,否则重试更新操作,直到更新成功。
- CAS 算法
CAS:Compare And Swap(比较与交换) ,用于实现乐观锁,保证在无锁情况下保证线程操作共享数据的原子性,被广泛应用于各大框架中。CAS 的思想是用一个预期值和要更新的变量值进行比较,两值相等才会进行更新。
CAS 是一个原子操作,底层依赖于一条 CPU 的原子指令。
CAS 涉及到三个操作数:
- V:要更新的变量值(Var)
- E:预期值(Expected)
- N:拟写入的新值(New)
当且仅当 V 的值等于 E 时,CAS 通过原子方式用新值 N 来更新 V 的值。如果不等,说明已经有其它线程更新了 V,则当前线程放弃更新。
- 存在的问题:ABA 问题、循环时间长开销大
- 底层:依赖于一个 Unsafe 类来直接调用操作系统底层的 CAS 指令
公平锁、非公平锁
- 公平锁 : 锁被释放之后,先申请的线程先得到锁。性能较差一些,因为公平锁为了保证时间上的绝对顺序,上下文切换更频繁。
- 非公平锁:锁被释放之后,后申请的线程可能会先获取到锁,是随机或者按照其他优先级排序的。性能更好,但可能会导致某些线程永远无法获取到锁。
共享锁、 独占锁
- 共享锁:一把锁可以被多个线程同时获得。
- 独占锁:一把锁只能被一个线程获得。
Java内存模型
什么是 Java 的 happens-before 规则?
happens-before 规则定义了多线程程序中操作的可见性和顺序性。它通过指定一系列操作之间的顺序关系,确保线程间的操作是有序的,避免由于重排序或线程间数据不可见导致的并发问题。
happens-before 规则的主要内容:
1)程序次序规则:在一个线程中,代码的执行顺序是按照程序中的书写顺序执行的,即一个线程内,前面的操作 happens-before 后面的操作。
2)监视器锁规则:一个锁的解锁(unlock)操作 happens-before 后续对这个锁的加锁(lock)操作。也就是说,在释放锁之前的所有修改在加锁后对其他线程可见。
3)volatile 变量规则:对一个 volatile 变量的写操作 happens-before 后续对这个 volatile 变量的读操作。它保证 volatile 变量的可见性,确保一个线程修改 volatile 变量后,其他线程能立即看到最新值。
4) 线程启动规则:线程 A 执行 Thread.start() 操作后,线程 B 中的所有操作 happens-before 线程 A 的 Thread.start() 调用。
5)线程终止规则:线程 A 执行 Thread.join() 操作后,线程 B 中的所有操作 happens-before 线程 A 从 Thread.join() 返回。
6)线程中断规则:对线程的 interrupt() 调用 happens-before 线程检测到中断事件(通过 Thread.interrupted() 或 Thread.isInterrupted())。
7)对象的构造规则:对象的构造完成(即构造函数执行完毕) happens-before 该对象的 finalize() 方法调用。
什么是 Java 中的指令重排?
指令重排是 Java 编译器和处理器为了优化性能,在保证单线程程序语义不变的情况下,对指令执行顺序进行调整的过程。在多线程环境下,指令重排可能导致线程之间的操作出现不同步或不可见的现象,因此 Java 提供了内存模型(JMM)和相关机制(如 volatile 和 synchronized)来限制这种行为,确保并发操作的正确性。
主要原因:
- 编译器优化:编译器会在不影响单线程程序语义的情况下重排序代码,以提升执行效率。
- 处理器优化:现代处理器会进行指令流水线优化,允许多条指令并行执行或重排序。
重排序的影响:
- 单线程情况下不会影响程序执行结果。
- 多线程情况下,指令重排可能导致线程之间的数据不一致问题,影响并发的正确性。
指令重排的三种类型
- 编译器重排:编译器在生成字节码时,根据优化策略调整代码的顺序,前提是不会改变程序的单线程语义。
- CPU 重排:处理器执行指令时,可能会对指令顺序进行调整,以充分利用 CPU 资源,例如指令流水线和多核并行执行。
- 内存系统重排:不同线程访问共享内存时,内存系统可能会对内存操作顺序进行调整。
volatile 的作用
- 保证线程间的可见性:用 volatile 修饰共享变量,能够防止编译器等优化发生,让一个线程对共享变量的修改对另一个线程可见。
- 禁止进行指令重排序:用 volatile 修饰共享变量会在读、写共享变量时加入不同的屏障,阻止其他读写操作越过屏障,从而达到阻止重排序的效果。
如何理解Java中的原子性、可见性、有序性?
原子性(Atomicity)
原子性指的是一个操作或一系列操作要么全部执行成功,要么全部不执行,期间不会被其他线程干扰。
- 原子类与锁:Java 提供了
java.util.concurrent.atomic包中的原子类,如AtomicInteger,AtomicLong,来保证基本类型的操作具有原子性。此外,synchronized关键字和Lock接口也可以用来确保操作的原子性。 - CAS(Compare-And-Swap):Java 的原子类底层依赖于 CAS 操作来实现原子性。CAS 是一种硬件级的指令,它比较内存位置的当前值与给定的旧值,如果相等则将内存位置更新为新值,这一过程是原子的。CAS 可以避免传统锁机制带来的上下文切换开销。
可见性(Visibility)
可见性指的是当一个线程修改了某个共享变量的值,其他线程能够立即看到这个修改。
- volatile:
volatile关键字是 Java 中用来保证可见性的轻量级同步机制。当一个变量被声明为volatile时,所有对该变量的读写操作都会直接从主内存中进行,从而确保变量对所有线程的可见性。 - synchronized:
synchronized关键字不仅可以保证代码块的原子性,还可以保证进入和退出synchronized块的线程能够看到块内变量的最新值。每次线程退出synchronized块时,都会将修改后的变量值刷新到主内存中,进入该块的线程则会从主内存中读取最新的值。 - Java Memory Model(JMM):JMM 规定了共享变量在不同线程间的可见性和有序性规则。它定义了内存屏障的插入规则,确保在多线程环境下的代码执行顺序和内存可见性。
有序性(Ordering)
有序性指的是程序执行的顺序和代码的先后顺序一致。但在多线程环境下,为了优化性能,编译器和处理器可能会对指令进行重排序。
- 指令重排序:为了提高性能,处理器和编译器可能会对指令进行重排序。尽管重排序不会影响单线程中的执行结果,但在多线程环境下可能会导致严重的问题。例如,经典的双重检查锁定(DCL)模式在没有正确同步的情况下,由于指令重排序可能导致对象尚未完全初始化就被另一个线程访问。
- happens-before 原则:JMM 定义了
happens-before规则,用于约束操作之间的有序性。如果一个操作Ahappens-before 操作B,那么A的结果对于B是可见的,且A的执行顺序在B之前。这为开发者提供了在多线程环境中控制操作顺序的手段。 - 内存屏障:
volatile变量的读写操作会在指令流中插入内存屏障,阻止特定的指令重排序。对于volatile变量的写操作,会在写操作前插入一个 StoreStore 屏障,防止写操作与之前的写操作重排序;在读操作之后插入一个 LoadLoad 屏障,防止读操作与之后的读操作重排序。
并发安全
使用多线程可能带来的问题
并发编程的目的就是为了能提高程序的执行效率进而提高程序的运行速度,但是并发编程并不总是能提高程序运行速度的,而且并发编程可能会遇到很多问题,比如:内存泄漏、死锁、线程不安全等等。
线程安全和不安全
线程安全和不安全是在多线程环境下对于同一份数据的访问是否能够保证其正确性和一致性的描述。
- 线程安全:在多线程环境下,对于同一份数据,不管有多少个线程同时访问,都能保证这份数据的正确性和一致性。
- 面试鸭:线程安全是指多个线程访问某一共享资源时,能够保证一致性和正确性,即无论线程如何交替执行,程序都能够产生预期的结果,且不会出现数据竞争或内存冲突。在 Java 中,线程安全的实现通常依赖于同步机制和线程隔离技术。
- 线程不安全:在多线程环境下,对于同一份数据,多个线程同时访问时可能会导致数据混乱、错误或者丢失。
常用的线程安全措施
- 同步锁:通过
synchronized关键字或ReentrantLock实现对共享资源的同步控制。 - 原子操作类:Java 提供的
AtomicInteger、AtomicReference等类确保多线程环境下的原子性操作。 - 线程安全容器:如
ConcurrentHashMap、CopyOnWriteArrayList等,避免手动加锁。 - 局部变量:线程内独立的局部变量天然是线程安全的,因为每个线程都有自己的栈空间(线程隔离)。
- ThreadLocal:类似于局部变量,属于线程本地资源,通过线程隔离保证了线程安全。
- CAS(Compare and Swap)操作:CAS 操作是硬件级别的原子操作,它包含三个操作数:内存位置(V)、预期原值(A)和新值(B)。如果内存位置的值与预期原值相匹配,那么处理器会自动将该位置的值更新为新值。否则,操作失败,处理器不做任何事情。在 Java 中,CAS 操作通过
Unsafe类的compareAndSwapInt方法来实现。Unsafe类提供了对底层内存的直接访问和修改能力,这是一个非公开的类,通常通过反射来获取它的实例。
怎么保证多线程的执行安全?
导致并发程序出现问题的根本原因和解决办法:
原子性synchronized、lock:一个线程在CPU中操作不可暂停,也不可中断,要不执行完成,要不不执行
内存可见性volatile、synchronized、lock:让一个线程对共享变量的修改对另一个线程可见
有序性volatile:处理器为了提高程序运行效率,可能会对输入代码进行优化,它不保证程序中各个语句的执行先后顺序同代码中的顺序一致,但是它会保证程序最终执行结果和代码顺序执行的结果是一致的
如何判断方法内局部变量是否线程安全?
两条原则:
- 如果局部变量没有逃离方法的作用范围,它是线程安全的。
- 如果局部变量引用了对象,并逃离方法的作用范围,它是线程不安全的。
示例代码:
public static void main(String[] args) {
StringBuilder sb1 = new StringBuilder();
sb1.append(1);
sb1.append(2);
//线程安全
new Thread(()->{
StringBuilder sb2 = new StringBuilder();
sb2.append(3);
sb2.append(4);
System.out.println(sb2);
return sb2;
});
//线程不安全
new Runnable() {
@Override
public void run() {
sb1.append(3);
sb1.append(4);
System.out.println(sb1);
}
};
}如何使线程内局部变量线程安全?
- 直接用线程安全的类
- 确保局部变量线程安全
ABA 问题
ABA 问题是指在多线程环境下,某个变量的值在一段时间内经历了从 A 到 B 再到 A 的变化,这种变化可能被线程误认为值没有变化,从而导致错误的判断和操作。ABA 问题常发生在使用 CAS(Compare-And-Swap) 操作的无锁并发编程中。
解决 ABA 问题的方法
1)引入版本号:
最常见的解决 ABA 问题的方法是使用版本号。在每次更新一个变量时,不仅更新变量的值,还更新一个版本号。CAS 操作在比较时,除了比较值是否一致,还比较版本号是否匹配。这样,即使值回到了初始值,版本号的变化也能检测到修改。
Java 中的 AtomicStampedReference 提供了版本号机制来避免 ABA 问题。
2)使用 AtomicMarkableReference:
这是另一种类似的机制,它允许在引用上标记一个布尔值,帮助区分是否发生了特定变化。虽然不直接使用版本号,但标记位可以用来追踪状态的变化。
-------------------并发锁-------------------
锁的种类及使用场景
- 独占锁(Exclusive Lock):如
synchronized和ReentrantLock,同一时间只允许一个线程持有锁,适合写操作较多的场景。 - 读写锁(ReadWriteLock):允许多个线程并发读,但写时需要独占锁,适合读多写少的场景。
- 乐观锁和悲观锁:悲观锁假设会有并发冲突,每次操作都加锁;而乐观锁假设不会有冲突,通过版本号或 CAS 实现冲突检测。
如何优化 Java 中的锁的使用?
主要有以下两种常见的优化方法:
1)减小锁的粒度(使用的时间):
- 尽量缩小加锁的范围,减少锁的持有时间。即在必要的最小代码块内使用锁,避免对整个方法或过多代码块加锁。
- 使用更细粒度的锁,比如将一个大对象锁拆分为多个小对象锁,以提高并行度(参考
HashTable和ConcurrentHashMap的区别)。 - 对于读多写少的场景,可以使用读写锁(
ReentrantReadWriteLock)代替独占锁。
2)减少锁的使用:
- 通过无锁编程、CAS(Compare-And-Swap)操作和原子类(如
AtomicInteger、AtomicReference)来避免使用锁,从而减少锁带来的性能损耗。 - 通过减少共享资源的使用,避免线程对同一个资源的竞争。例如,使用局部变量或线程本地变量(
ThreadLocal)来减少多个线程对同一资源的访问。
读写锁
读写锁允许多个线程同时读取共享资源,而在写操作时确保只有一个线程能够进行写操作(读读操作不互斥,读写互斥、写写互斥)。
读写锁适合读多写少的场景,因为它提高了系统的并发性和性能。
Java 中的 ReadWriteLock 是通过 ReentrantReadWriteLock 实现的,它提供了以下两种锁模式:
- 读锁(共享锁):允许多个线程同时获取读锁,只要没有任何线程持有写锁。适合读操作频繁而写操作较少的场景。
- 写锁(独占锁):写锁是独占的,当有线程持有写锁时,其他线程既不能获取写锁,也不能获取读锁。写锁用于保证写操作的独占性,防止数据不一致。
读写锁的原理
- 共享与独占:读锁是共享锁,多个线程可以同时获取;而写锁是独占锁,在持有写锁期间,其他线程不能获取写锁或读锁。
- 锁降级:
ReentrantReadWriteLock支持锁降级,即持有写锁的线程可以直接获取读锁,从而在写操作完成后不必完全释放锁,但不支持锁升级(即不能从读锁升级为写锁)。 - 公平锁与非公平锁:
ReentrantReadWriteLock提供了公平和非公平模式。在公平模式下,线程将按照请求的顺序获取锁;而在非公平模式下,线程可能会插队,提高吞吐量。 - 读写锁也是基于 AQS 实现的,再具体点的实现就是将 state 分为了两部分,高16bit用于标识读状态、低16bit标识写状态。
synchronized 的锁升级
| 锁形式 | 使用情况 | 性能 | 描述 |
|---|---|---|---|
| 重量级锁 | 多线程竞争锁 | 性能比较低 | 底层使用的Monitor实现,涉及到了用户态和[内核态](#Kernel Mode)的切换、进程的上下文切换,成本较高。 |
| 轻量级锁 | 不同线程交替持有锁 | 相对重量级锁性能提升很多 | 线程加锁的时间是错开的(也就是没有竞争),可以使用轻量级锁来优化。轻量级修改了对象头的锁标志。通过CAS操作保证原子性。 |
| 偏向锁 | 锁只被一个线程持有 | 性能最好 | 线程第一次获得锁时进行一次CAS操作,之后该线程再获取锁,只需要判断自己是否持有锁 |
- 无锁状态(Unlocked):在对象首次被访问时,默认是没有加锁的。此时,多个线程可以并行地访问对象的方法而无需阻塞。
- 偏向锁(Biased Locking):当第一个线程访问该对象的
synchronized方法或代码块时,JVM会将对象头中的Mark Word标记为偏向锁的状态,并记录下当前线程的信息。 - 锁撤销(Revocation):如果持有偏向锁的线程长时间未访问该对象,或者有其他线程试图获取锁,那么JVM会撤销偏向锁,并将对象的状态恢复到无锁状态。此时,任何线程都可以再次竞争锁。
- 轻量级锁(Lightweight Locking):当第二个线程尝试访问该对象的
synchronized方法时,JVM会尝试使用轻量级锁。轻量级锁是由每个线程在其本地栈中维护的一个名为Lock Record的数据结构来实现的。当线程请求锁时,它会在本地栈中创建一个Lock Record,并尝试使用CAS操作将对象头中的Mark Word更新为指向这个Lock Record的指针。如果CAS操作成功,那么该线程获得了锁;否则,如果对象已经被其他线程锁定,那么当前线程就会进入下一个阶段。 - 重量级锁(Heavyweight Locking):如果轻量级锁的CAS操作失败,或者轻量级锁尝试了多次仍然无法获得锁,那么JVM会将轻量级锁升级为重量级锁。重量级锁是通过操作系统提供的互斥锁来实现的,这意味着线程在获取锁之前必须挂起,而在释放锁之后才能恢复执行。这会导致更高的性能开销,因此只有在确实需要的时候才会升级为重量级锁。
synchronized 的实现原理
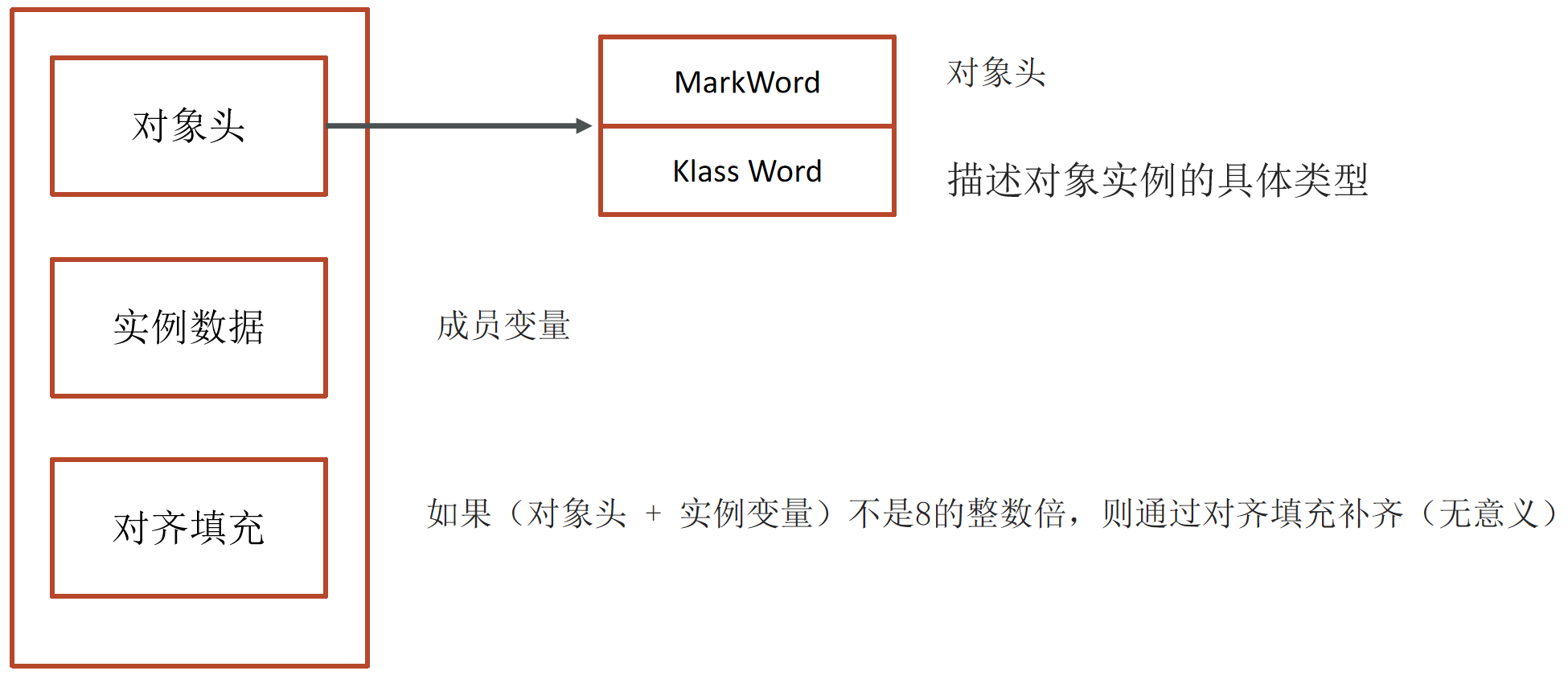
synchronized 实现原理依赖于 JVM 的 Monitor(监视器锁) 和 对象头(Object Header)。
在HotSpot虚拟机中,对象在内存中存储的布局可分为3块区域:对象头(Header)、实例数据(Instance Data)、对齐填充。
当 synchronized 修饰在方法或代码块上时,会对特定的对象或类加锁,从而确保同一时刻只有一个线程能执行加锁的代码块。
- synchronized 修饰方法:方法的常量池会增加一个
ACC_SYNCHRONIZED标志,当某个线程访问这个方法检查是否有ACC_SYNCHRONIZED标志,若有则需要获得监视器锁才可执行方法,此时就保证了方法的同步。 - synchronized 修饰代码块:会在代码块的前后插入
monitorenter和monitorexit字节码指令。可以把monitorenter理解为加锁,monitorexit理解为解锁。
Monitor
Monitor实现的锁属于重量级锁,里面涉及到了用户态和内核态的切换、进程的上下文切换,成本较高,性能比较低。
在JDK 1.6引入了两种新型锁机制:偏向锁和轻量级锁,它们的引入是为了解决在没有多线程竞争或基本没有竞争的场景下因使用传统锁机制带来的性能开销问题。
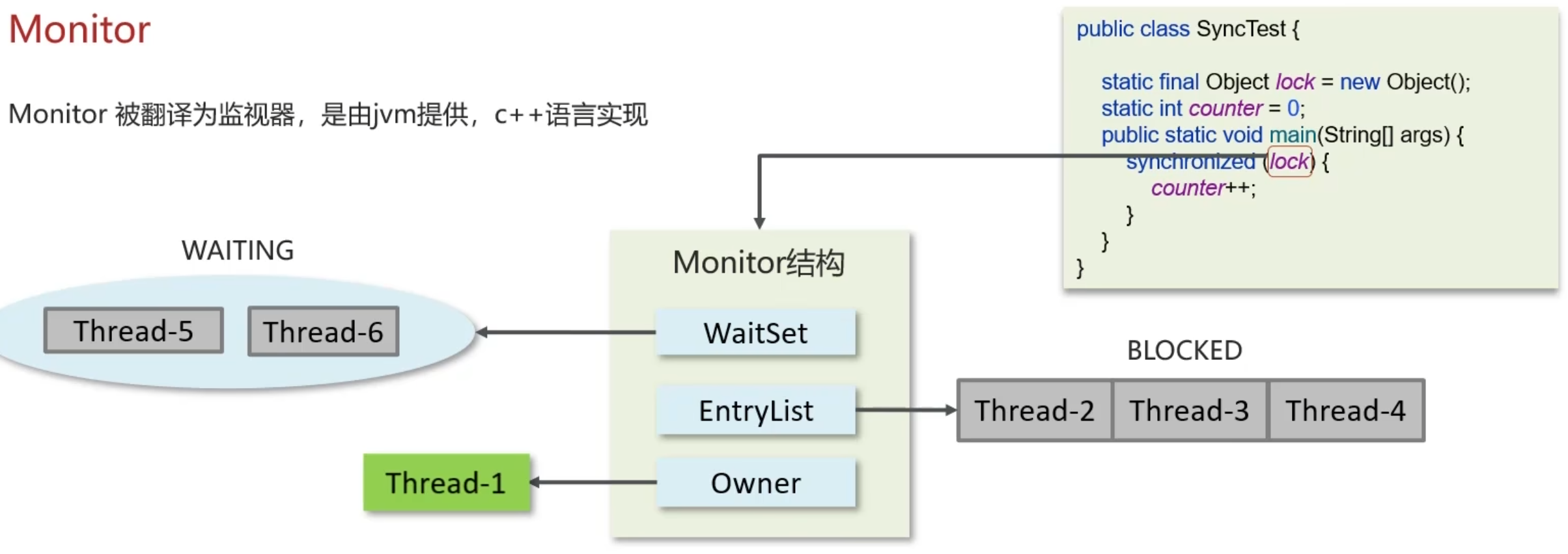
- Owner:存储当前获取锁的线程的,只能有一个线程可以获取
- EntryList:关联没有抢到锁的线程,处于Blocked状态的线程
- WaitSet:关联调用了wait方法的线程,处于Waiting状态的线程
面试:说说AQS吧?
参考回答:
AQS 将一些操作封装起来,比如入队等基本方法,暴露出方法,便于其他相关 JUC 锁的使用。
比如 ReentrantLock、CountDownLatch、Semaphore 等等。
简单来说 AQS 就是起到了一个抽象、封装的作用,将一些排队、入队、加锁、中断等方法提供出来,具体加锁时机、入队时机等都需要实现类自己控制。
然后面试官会引申问你具体 ReentrantLock 的实现原理是怎样的呢?
AQS的工作机制
AQS(Abstract Queued Synchronizer),是Java中的一个抽象类,提供了构建锁和其他同步组件的基础框架,用于同步多线程中的队列,ReentrantLock、Semaphore都是基于AQS实现的。
谈论AQS是公平锁还是非公平锁并不准确,应当说是AQS是一个支持构建公平锁和非公平锁两种模式的同步组件。
工作机制:
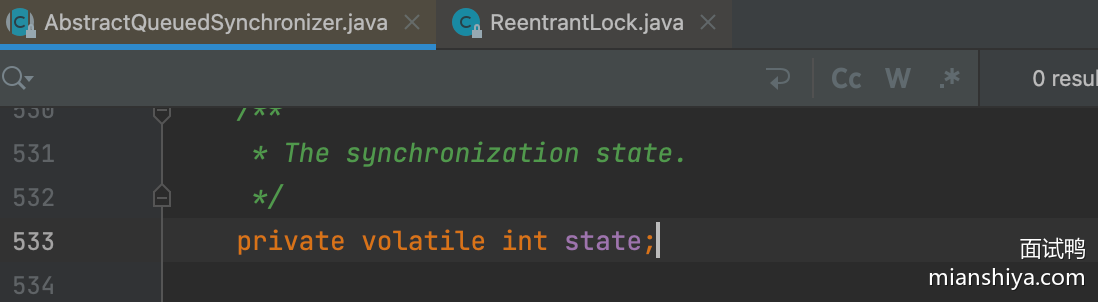
在AQS中维护了一个使用了volatile修饰的state属性来表示资源的状态,0表示无锁,1表示有锁,修改state时使用CAS操作保证原子性,确保只能有一个线程修改成功,修改失败的线程将会进入队列中等待。如果队列中的有一个线程修改成功了state为1,则当前线程就相等于获取了资源。
AQS内部维护了一个 FIFO 的等待队列,类似于 Monitor 的 EntryList,用于管理等待获取同步状态的线程。每个节点(Node)代表一个等待的线程,节点之间通过 next 和 prev 指针链接。
javastatic final class Node { static final Node SHARED = new Node(); static final Node EXCLUSIVE = null; volatile int waitStatus; volatile Node prev; volatile Node next; volatile Thread thread; // 保存等待的线程 Node nextWaiter; ..... }当一个线程获取同步状态失败时,它会被添加到等待队列中,并自旋等待或被阻塞,直到前面的线程释放同步状态。
独占模式和共享模式
- 独占模式:只有一个线程能获取同步状态,例如 ReentrantLock。
- 共享模式:多个线程可以同时获取同步状态,例如 Semaphore 和 ReadWriteLock。
AQS支持实现多种类型的锁,包括公平锁和非公平锁。
- 新的线程与队列中的线程共同来抢资源,是非公平锁
- 新的线程到队列中等待,只让队列中的head线程获取锁,是公平锁
ReentrantLock
ReentrantLock是基于AQS实现的一个互斥锁,它可以被配置为公平锁或非公平锁,通过构造函数的参数来决定。
ReentrantLock相对于synchronized它具备以下特点:
- 可中断
- 可设置超时时间
- 可设置公平锁
- 支持多个条件变量
- 与synchronized一样,都支持重入
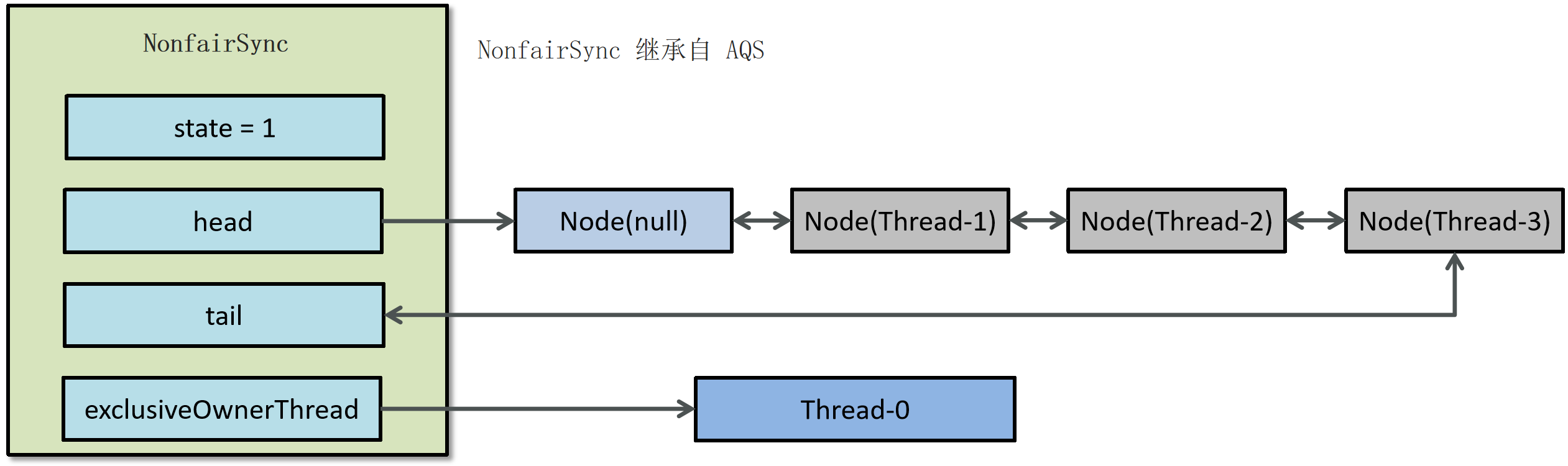
ReentrantLock 的结构
ReentrantLock主要利用CAS+AQS队列来实现。它支持公平锁和非公平锁,两者的实现类似,构造方法接受一个可选的公平参数(默认非公平锁),当设置为true时,表示公平锁,否则为非公平锁。公平锁体现在按照先后顺序获取锁,非公平体现在不在排队的线程也可以抢锁
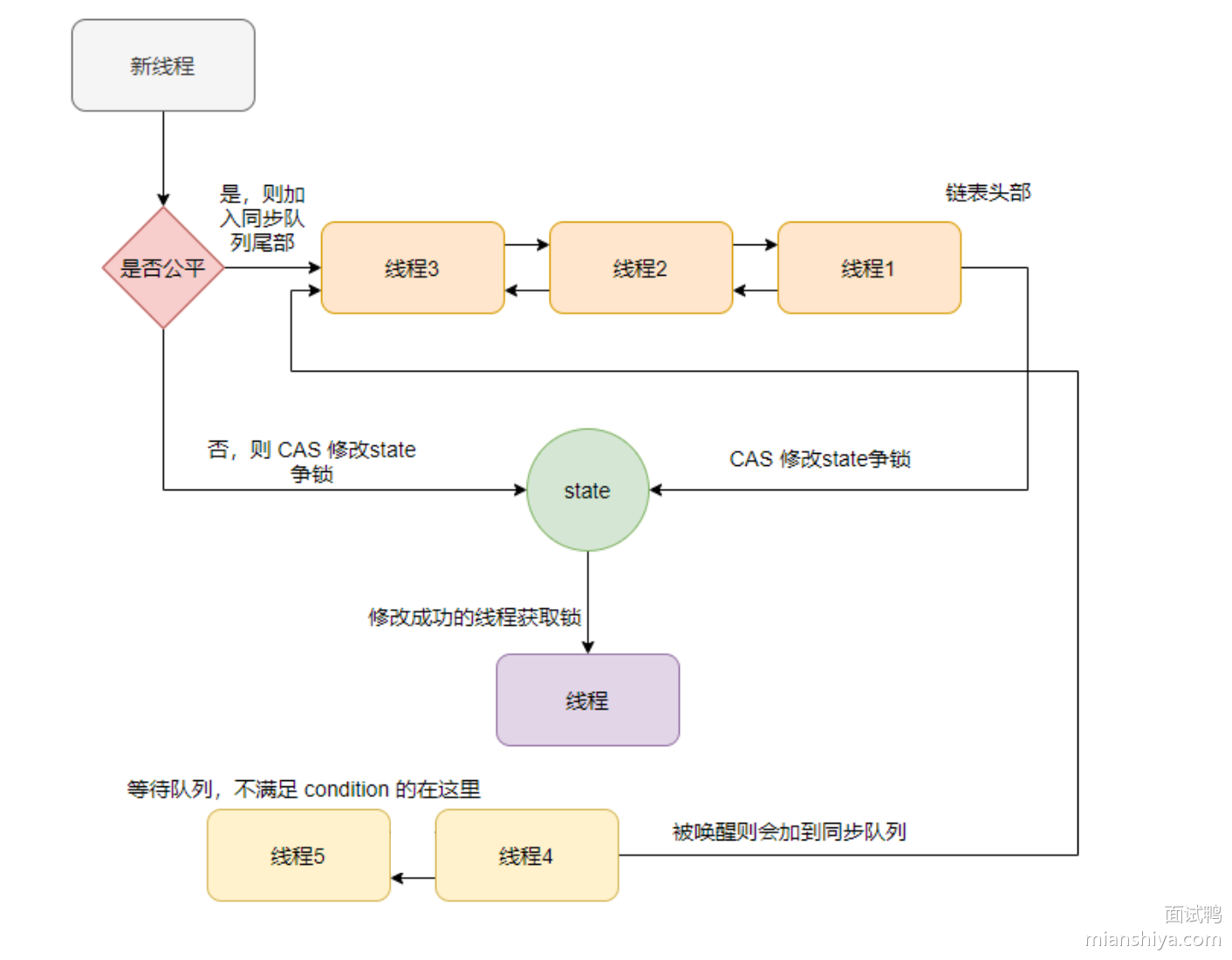
ReentrantLock 的工作原理
- 线程来抢锁后使用CAS操作修改
state状态,修改状态成功为1,则让exclusiveOwnerThread属性指向当前线程,获取锁成功 - 假如修改状态失败,则会进入双向队列中等待,
head指向双向队列头部,tail指向双向队列尾部 - 当
exclusiveOwnerThread为null的时候,则会唤醒在双向队列中等待的线程
synchronized 与 AQS 的区别
| 区别 | AQS | synchronized |
|---|---|---|
| 实现语言 | Java 语言实现 | C++ 语言实现 |
| 类型 | 悲观锁,手动开启和关闭 | 悲观锁,自动释放锁 |
| 性能 | 锁竞争激烈的情况下,提供了多种解决方案 | 锁竞争激烈都是重量级锁,性能差 |
synchronized 与 Lock 有什么区别 ?
| 特点 | synchronized | Lock |
|---|---|---|
| 语法层面 | 关键字,源码在 JVM 中,用 C++ 实现 使用时,退出同步代码块锁会自动释放 | 接口,源码由 JDK 提供,用 Java 语言实现 使用时,需要手动调用 unlock 方法释放锁 |
| 功能层面 | 悲观锁,具备互斥、同步、锁重入功能 | 悲观锁,具备互斥、同步、锁重入功能 提供了更多功能,如获取等待状态、公平锁、可打断、可超时、多条件 Condition变量有适合不同场景的实现,如 ReentrantLock,ReentrantReadWriteLock |
| 性能层面 | 在没有竞争时,做了很多优化,如偏向锁、轻量级锁 | 在竞争激烈时,通常会提供更好的性能 |
synchronized 与 ReentrantLock 有什么区别 ?
| 特性 | synchronized | ReentrantLock |
|---|---|---|
| 类别 | Java关键字 | Java中的一个类 |
| 锁类型 | JVM层面的锁 | Java API层面的锁 |
| 加锁/解锁方式 | 自动加锁与释放锁 | 需要手动加锁与释放锁 |
| 获取当前线程是否上锁 | 不可获取 | 可获取 (isHeldByCurrentThread()) |
| 公平性 | 默认非公平锁 | 公平锁或非公平锁 |
| 中断支持 | 不可中断 | 可中断 (tryLock(), lockInterruptibly()) |
| 锁的对象 | 锁的是对象,锁信息保存在对象头中 | int类型的state标识来标识锁的状态 |
| 锁升级 | 底层有锁升级过程 | 没有锁升级过程 |

----------------并发工具类----------------
AtomicInteger 的实现原理
AtomicInteger 的实现基于 CAS(Compare and Swap)操作,这是一种无锁的同步算法。
实现原理:
AtomicInteger的value字段是一个int变量,通过volatile保证了可见性和有序性。AtomicInteger使用Unsafe类来进行 CAS 操作,以确保对value字段的原子性更新。
CountDownLatch
CountDownLatch 可以用来进行线程同步协作,一个线程(或多个)等待所有线程完成倒计时。
- 其中构造参数用来初始化等待计数值
- await() 用来等待计数归零
- countDown() 用来让计数减一
应用场景:
- 批量导入:使用了线程池+CountDownLatch批量把数据库中的数据导入到了ES中,避免OOM
- 数据汇总:调用多个接口来汇总数据,如果所有接口(或部分接口)的没有依赖关系,就可以使用线程池+future来提升性能
- 异步线程(线程池):为了避免下一级方法影响上一级方法(性能考虑),可使用异步线程调用下一个方法(不需要下一级方法返回值),可以提升方法响应时间
// 计数器为 3,表示需要等待 3 个任务完成
CountDownLatch latch = new CountDownLatch(3);
// 启动 3 个线程来执行任务
for (int i = 1; i <= 3; i++) {
new Thread(() -> {
System.out.println(Thread.currentThread().getName() + " 执行任务");
latch.countDown(); // 每个线程执行完任务后递减计数器
}).start();
}
System.out.println("等待所有任务完成...");
latch.await(); // 主线程等待所有任务完成
System.out.println("所有任务已完成,继续执行主线程");CountDownLatch 的实现原理
CountDownLatch 的内部维护了一个计数器,计数器的递减操作是通过 AbstractQueuedSynchronizer (AQS) 来实现的。
当调用 countDown() 时,内部的 state 值减少,并在 await() 中通过检查 state 是否为 0 来决定是否唤醒等待线程。
注意:CountDownLatch 无法重用,它适合用于一次性的任务完成同步。如果需要重复使用,需要使用 CyclicBarrier 或其他机制。
CyclicBarrier
- 作用: 让一组线程到达一个共同的同步点,然后一起继续执行。常用于分阶段任务执行。
- 用法: 适用于需要所有线程在某个点都完成后再继续的场景。
CyclicBarrier barrier = new CyclicBarrier(3, () -> {
System.out.println("所有线程都到达了屏障点");
});
Runnable task = () -> {
try {
// 执行任务
barrier.await(); // 等待其他线程
} catch (Exception e) {
e.printStackTrace();
}
};
new Thread(task).start();
new Thread(task).start();
new Thread(task).start();CyclicBarrier 的原理
CyclicBarrier 是基于 ReentrantLock 和 Condition 实现的。
CyclicBarrier 内部维护了一个计数器,即达到屏障的线程数量,当线程调用 await 的时候计数器会减一,如果计数器减一不等于 0 的时候,线程会调用 condition.await 进行阻塞等待。
如果计数器减一的值等于 0,说明最后一个线程也到达了屏障,于是如果有 barrierAction 就执行 barrierAction ,然后调用 condition.signalAll 唤醒之前等待的线程,并且重置计数器,然后开启下一代,所以它可以循环使用。

Semaphore 的使用场景
Semaphore 可以用来限制线程的执行数量,达到限流的效果。
当一个线程执行时先通过其方法进行获取许可操作,获取到许可的线程继续执行业务逻辑,当线程执行完成后进行释放许可操作,未获取达到许可的线程进行等待或者直接结束。
Semaphore 两个重要的方法:
acquire(): 请求一个信号量,这时候的信号量个数-1(一旦没有可使用的信号量,也即信号量个数变为负数时,再次请求的时候就会阻塞,直到其他线程释放了信号量)
release():释放一个信号量,此时信号量个数+1
Semaphore semaphore = new Semaphore(5); // 允许最多5个线程同时执行任务
for (int i = 0; i < 10; i++) {
new Thread(() -> {
try {
semaphore.acquire();
// 执行任务
// do something...
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
} finally {
semaphore.release();
}
}).start();
}ThreadLocal
ThreadLocal 是多线程中对于解决线程安全的一个操作类,本质是一个线程内部存储类,让多个线程只操作自己内部的值,从而实现线程数据隔离。
常见应用场景
- 数据库连接管理:每个线程拥有自己的数据库连接,避免了多个线程共享同一个连接导致的线程安全问题。
- 用户上下文管理:在处理用户请求时,每个线程拥有独立的用户上下文(如用户ID、Session信息),在并发环境中确保正确的用户数据。
ThreadLocal 的实现原理
ThreadLocal 通过为每个线程创建一个独立的变量副本来实现线程本地化存储,这个变量副本就是 ThreadLocalMap,而 ThreadLocalMap 是每个线程内部持有的结构。
ThreadLocalMap 的键是 Thread 对象,值是线程独立的变量副本。当线程访问 ThreadLocal.get() 时,它会根据当前线程在自己的 ThreadLocalMap 中找到对应的变量副本。

以下是一个简化的访问流程:
线程A访问
ThreadLocal.get()时,从自己独立的ThreadLocalMap中找到与该ThreadLocal对象对应的值。线程B访问
ThreadLocal.get()时,也从自己独立的ThreadLocalMap中获取的是与其自身相关的值,互不干扰。
ThreadLocal 三个主要方法:
- set(value) 设置值
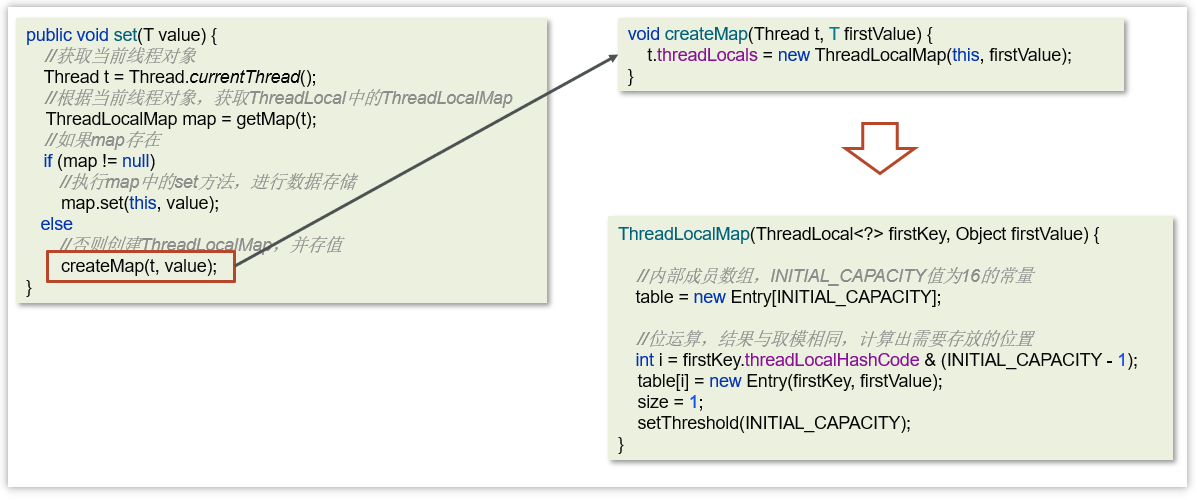
- get() 获取值 / remove() 清除值

ThreadLocal 的内存泄露问题
Java对象中的四种引用类型:强引用、软引用、弱引用、虚引用
强引用:最为普通的引用方式,表示一个对象处于有用且必须的状态,如果一个对象具有强引用,则GC并不会回收它。即便堆中内存不足了,宁可出现OOM,也不会对其进行回收。
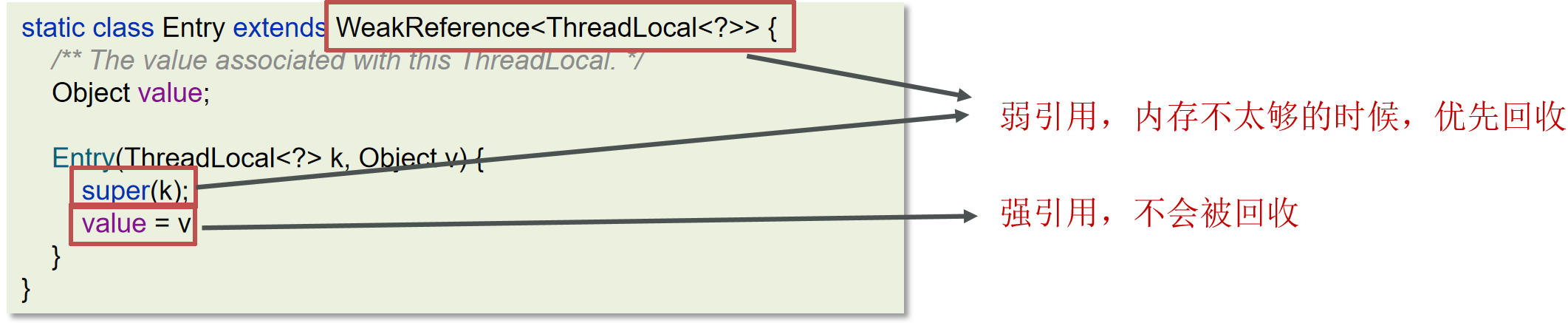
javaUser user = new User();弱引用:表示一个对象处于可能有用且非必须的状态。在GC线程扫描内存区域时,一旦发现弱引用,就会回收到弱引用相关联的对象。对于弱引用的回收,无关内存区域是否足够,一旦发现则会被回收。
javaUser user = new User(); WeakReference weakReference = new WeakReference(user);
每一个Thread维护的ThreadLocalMap中的Entry对象继承了WeakReference,其中key为使用弱引用的ThreadLocal实例,value为线程变量的副本。
ThreadLocalMap 中的 key 是弱引用,值为强引用; key 会被GC 释放内存,关联 value 的内存并不会释放。建议主动 remove 释放 key,value
为什么 ThreadLocal 的 key 是弱引用的?
弱引用的原因
- 避免占用过多内存:ThreadLocal 的
ThreadLocalMap会在垃圾回收时自动清理无效的条目,确保不会占用过多内存。 - 防止内存泄漏:如果 ThreadLocal 的 key 是强引用,那么即使 ThreadLocal 变量被回收,
ThreadLocalMap中的条目仍然会保留,导致内存泄漏。使用弱引用可以避免这种情况,因为当 ThreadLocal 变量被回收时,对应的条目也会被垃圾回收器清理。
如何避免 ThradLocal 的内存泄露?
尽管 ThreadLocal 使用弱引用来存储 key,但仍存在内存泄漏的风险。但通过及时移除 ThreadLocal 变量、使用 try-finally 块、自定义 ThreadLocal 类以及在线程池中进行特殊处理,可以有效避免这些问题。这些措施可以确保 ThreadLocal 变量在不再需要时被及时清除,从而避免内存泄漏。
Timer
Timer是一个用于调度任务的工具类。适用于简单的定时任务,如定时更新、定期发送报告等。
Timer 类一般与 TimerTask 搭配使用,TimerTask 是一个需要执行的任务,它是一个实现了 Runnable 接口的抽象类,必须通过继承并实现其 run() 方法。
基本使用:
- 使用
Timer.schedule(TimerTask task, long delay)在指定的延迟之后执行任务。 - 使用
Timer.scheduleAtFixedRate(TimerTask task, long delay, long period)周期性地执行任务。
Timer timer = new Timer();
TimerTask task = new TimerTask() {
@Override
public void run() {
System.out.println("Task executed!");
}
};
timer.schedule(task, 2000); // 2 秒后执行任务Timer的原理
Timer 可以实现延时任务,也可以实现周期性任务。
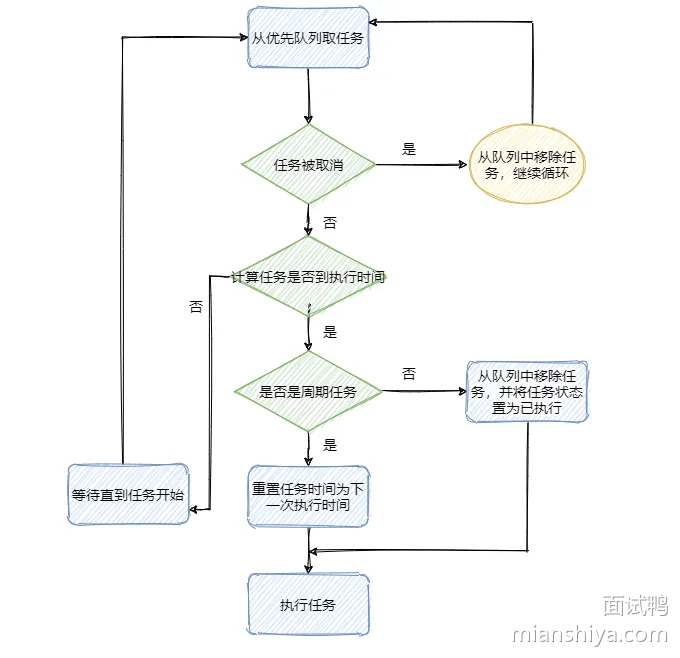
实现原理是:用优先队列维持一个小顶堆,即最快需要执行的任务排在优先队列的第一个,根据堆的特性我们知道插入和删除的时间复杂度都是 O(logn)。
然后有个 TimerThread 线程不断地拿排着的第一个任务的执行时间和当前时间做对比。
如果时间到了先看看这个任务是不是周期性执行的任务,如果是则修改当前任务时间为下次执行的时间,如果不是周期性任务则将任务从优先队列中移除。最后执行任务。如果时间还未到则调用 wait() 等待。
Timer 的弊端和替代方案
优先队列的插入和删除的时间复杂度是O(logn),当数据量大的时候,频繁的入堆出堆性能有待考虑。
并且是单线程执行,那么如果一个任务执行的时间过久则会影响下一个任务的执行时间(当然你任务的run要是异步执行也行)。
并且从它对异常没有做什么处理,所以一个任务出错的时候会导致之后的任务都无法执行。
推荐使用 ScheduledExecutorService 替代 Timer。
ScheduledExecutorService
ScheduledExecutorService 是 Java 5 引入的 Timer 的替代方案,功能更强大。支持多线程并行调度任务,能更好地处理任务调度的复杂场景。
因为使用线程池进行任务调度,所以不会因某个任务的异常终止而导致其他任务停止。并且它提供了更灵活的 API,可以更精细地控制任务的执行周期和策略。
public static void main(String[] args) {
ScheduledExecutorService executor = Executors.newScheduledThreadPool(1);
// 延迟3秒后执行任务
executor.schedule(
() -> System.out.println("Task running... "),
3,
TimeUnit.SECONDS);
// 初始延迟1秒后开始执行任务,之后每2秒执行一次
executor.scheduleAtFixedRate(
() -> System.out.println("Task executed at " + System.currentTimeMillis()), // Runnable
1, // initialDelay
2, // period
TimeUnit.SECONDS);
// 模拟长时间运行,实际应用中应该有一个条件来决定何时关闭线程池
try {
Thread.sleep(10000); // 让主线程等待10秒
// 关闭线程池
executor.shutdown();
} catch (InterruptedException e) {
e.printStackTrace();
}
}例:超时关闭不付款的订单
比如说这样一个场景,一个用户下单商品后一直不付款,那么30分钟就需要关闭这个订单,怎么做?
private static final ScheduledExecutorService executor = Executors.newScheduledThreadPool(1);
private static volatile boolean isPaid = false;
public static void main(String[] args) throws InterruptedException {
// 模拟系统关闭订单
ScheduledFuture<?> closeOrderTask = scheduleTask(12345L, 5, TimeUnit.SECONDS);
// 模拟用户付款
new Thread(() -> {
try {
Thread.sleep(6 * 1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
isPaid = true; // 标记订单为已付款
}).start();
// 用户完成付款,取消关闭订单的任务
if (closeOrderTask.isDone()) {
if (!isPaid) {
cancelCloseOrder(closeOrderTask);
} else {
System.out.println("订单已付款,无需关闭");
}
}
// 关闭线程池
executor.shutdown();
}
/**
* 调度一个任务,在指定时间后关闭订单。
* @param orderId 订单ID
* @param delay 延迟时间
* @param unit 时间单位
* @return ScheduledFuture 对象,用于取消任务
*/
public static ScheduledFuture<?> scheduleTask(Long orderId, long delay, TimeUnit unit) {
return executor.schedule(
() -> {
// 检查用户是否已经付款
if (isPaid) {
System.out.println("Order with ID: " + orderId + " is paid successfully.");
} else {
// 这里可以添加关闭订单的业务逻辑
System.out.println("Order with ID: " + orderId + " is closed due to timeout.");
}
return isPaid;
},
delay,
unit);
}
/**
* 取消关闭订单的任务。
* @param closeOrderTask 要取消的任务
*/
public static void cancelCloseOrder(ScheduledFuture<?> closeOrderTask) {
if (closeOrderTask.cancel(true)) {
System.out.println("Order closing cancelled successfully.");
} else {
System.out.println("Order closing cancelled error.");
}
}BlockingQueue
- 作用: 是一个线程安全的队列,支持阻塞操作,适用于生产者-消费者模式。
- 用法: 生产者线程将元素放入队列,消费者线程从队列中取元素,队列为空时消费者线程阻塞。
BlockingQueue<String> queue = new LinkedBlockingQueue<>();
Runnable producer = () -> {
try {
queue.put("item"); // 放入元素
} catch (InterruptedException e) {
e.printStackTrace();
}
};
Runnable consumer = () -> {
try {
String item = queue.take(); // 取出元素
} catch (InterruptedException e) {
e.printStackTrace();
}
};
new Thread(producer).start();
new Thread(consumer).start();BlockingQueue 的阻塞特性原理
核心机制:
1. 锁(Lock):BlockingQueue 的实现中会使用锁来确保线程安全。当多个线程试图访问队列时,锁可以确保同一时刻只有一个线程能够执行某些操作(如 put 或 take)。
2. 条件变量(Condition):条件变量允许一个或多个线程在一个特定条件得到满足之前等待。在 BlockingQueue 的实现中,条件变量用于等待队列变得非空(对于 take 操作)或非满(对于 put 操作)。
如何实现阻塞:
1. put 操作:当向 BlockingQueue 中添加元素时,如果队列已满,则 put 方法会阻塞当前线程,并调用 Condition 的 await 方法,使得当前线程等待,直到队列空出位置后再添加元素。
2. take 操作:当从 BlockingQueue 中取出元素时,如果队列为空,则 take 方法将阻塞当前线程,调用条件变量的 await 方法,使得当前线程等待,直到队列中有元素为止。
具体代码操作:
public class ArrayBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
private final ReentrantLock lock = new ReentrantLock();
private final Condition notEmpty = lock.newCondition();
private final Condition notFull = lock.newCondition();
// ... 其他成员变量定义 ...
public void put(E e) throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == items.length)
notFull.await(); // 如果队列已满,则等待
insert(e);
notEmpty.signal(); // 通知等待的消费者线程
} finally {
lock.unlock();
}
}
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == 0)
notEmpty.await(); // 如果队列为空,则等待
E x = remove();
notFull.signal(); // 通知等待的生产者线程
return x;
} finally {
lock.unlock();
}
}
// ... 其他方法 ...
}---------------------线程---------------------
如何创建线程?
一般来说,创建线程有很多种方式,例如继承Thread类、实现Runnable接口、实现Callable接口、利用Callable接口和Future接口方式、使用线程池、使用CompletableFuture类等等。
不过,这些方式其实并没有真正创建出线程。准确点来说,这些都属于是在 Java 代码中使用多线程的方法。
严格来说,Java 就只有一种方式可以创建线程,那就是通过new Thread().start()创建。不管是哪种方式,最终还是依赖于new Thread().start()。
| 创建方式 | 优点 | 缺点 |
|---|---|---|
| 继承Thread类 | 编程比较简单,可以直接使用Thread类中的方法 | 不能再继承其他的类扩展性较差 |
| 实现Runnable接口 | 扩展性强,实现该接口的同时还可以继承其他的类 | 编程相对复杂,不能直接使用Thread类中的方法 |
| 实现Callable接口 | 可以获取多线程运行过程中的结果;扩展性强,实现该接口的同时还可以继承其他的类 | 编程相对复杂,不能直接使用Thread类中的方法 |
| 线程池创建 | 易于管理 | 编程复杂,占用更多资源 |
主线程如何知晓创建的子线程是否执行成功?
1)使用 Thread.join():
- 主线程通过调用
join()方法等待子线程执行完毕。子线程正常结束,说明执行成功,若抛出异常则需要捕获处理。
2)使用 Callable 和 Future:
- 通过
Callable创建可返回结果的任务,并通过Future.get()获取子线程的执行结果或捕获异常。Future.get()会阻塞直到任务完成,若任务正常完成,返回结果,否则抛出异常。
3)使用回调机制:
- 可以通过自定义回调机制,主线程传入一个回调函数,子线程完成后调用该函数并传递执行结果。这样可以非阻塞地通知主线程任务完成情况。
4)使用 CountDownLatch或其他 JUC 相关类:
- 主线程通过
CountDownLatch来等待子线程完成。当子线程执行完毕后调用countDown(),主线程通过await()等待子线程完成任务。
线程的生命周期和状态
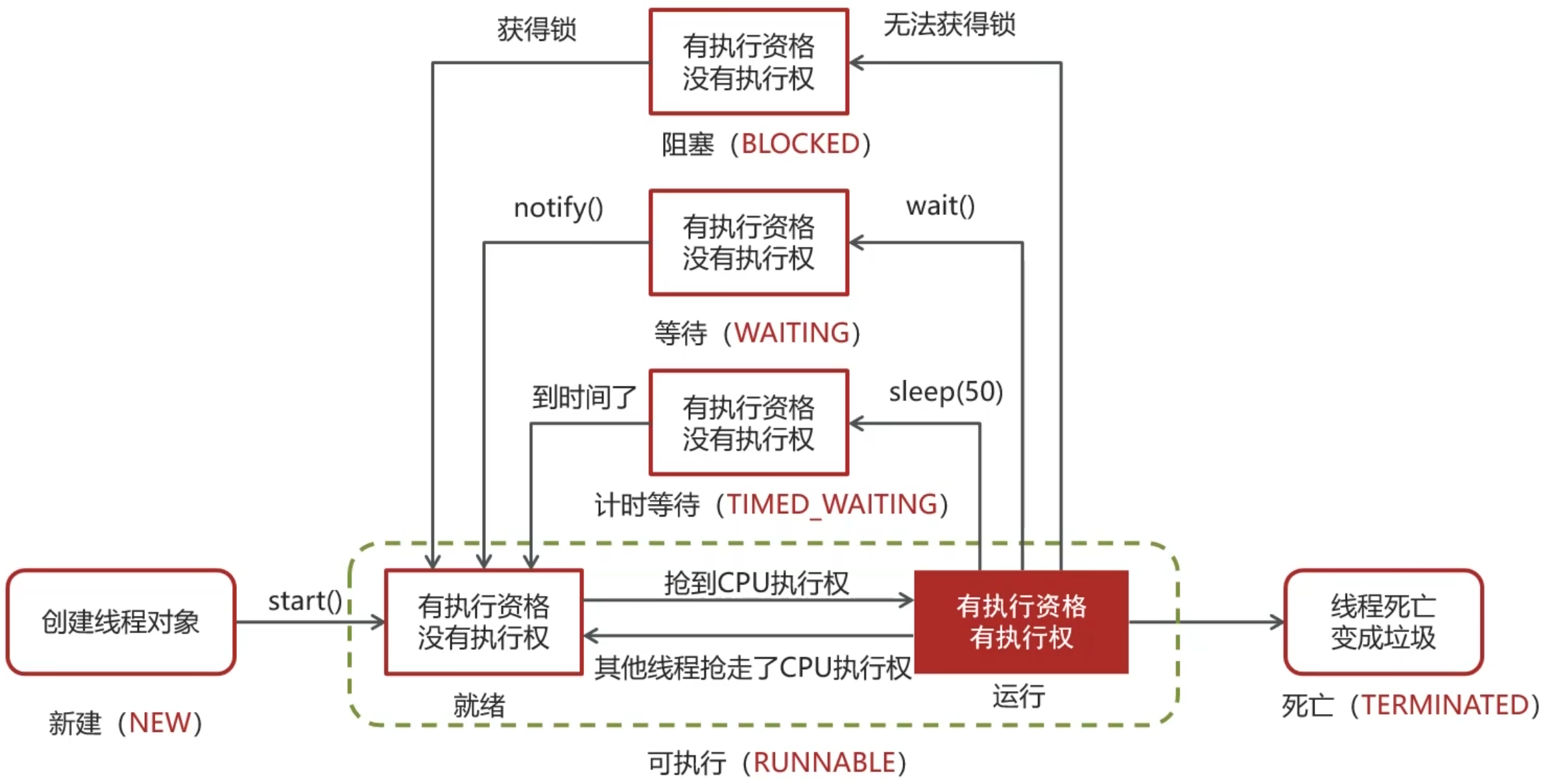
Java 线程在运行的生命周期中的指定时刻只可能处于下面 6 种不同状态的其中一个状态:
| 线程状态 | 具体含义 |
|---|---|
| NEW | 初始状态,线程被创建出来,但没有被调用 start() |
| RUNNABLE | 运行状态,线程被调用了 start()等待运行的状态 |
| BLOCKED | 阻塞状态,需要等待锁释放 |
| WAITING | 等待状态,表示该线程需要等待其他线程做出一些特定动作(通知或中断) |
| TIMED_WAITING | 超时等待状态,造成限时等待状态的原因有三种:Thread.sleep(long)、Object.wait(long)、join(long) |
| TERMINATED | 终止状态,表示该线程已经运行完毕= |
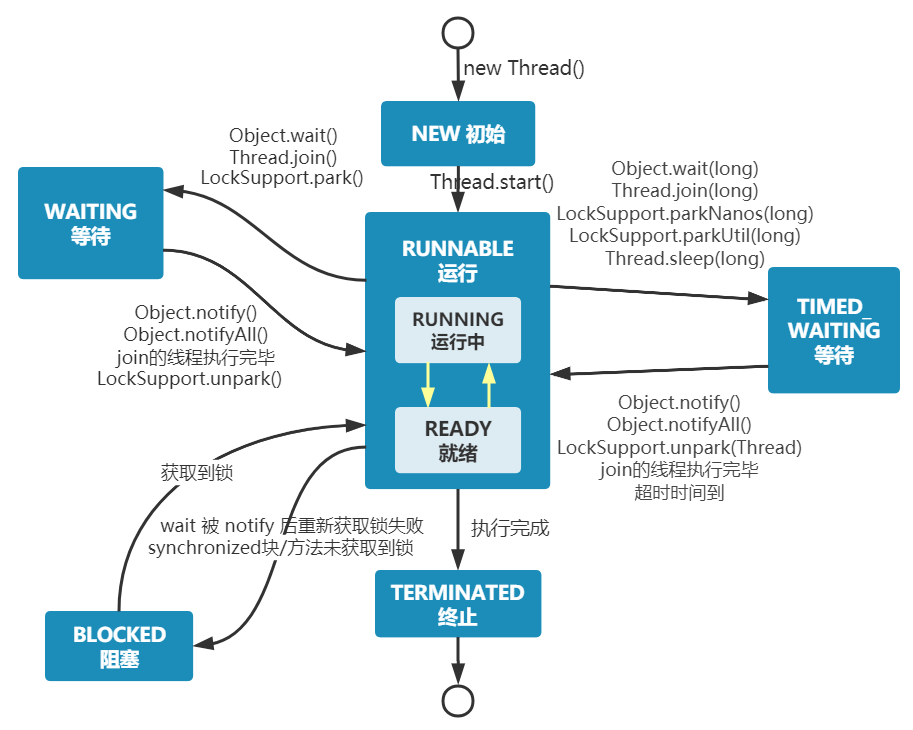
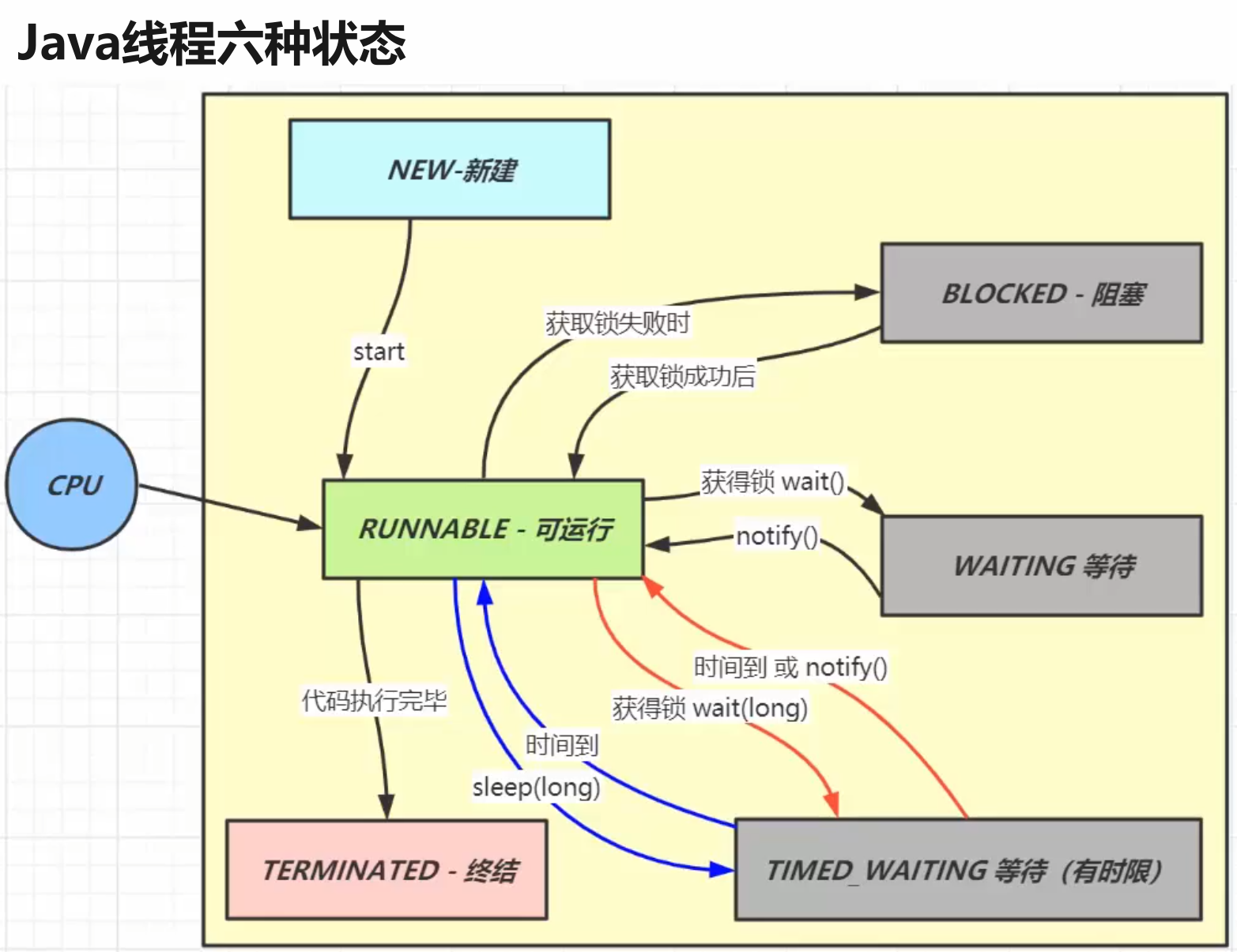
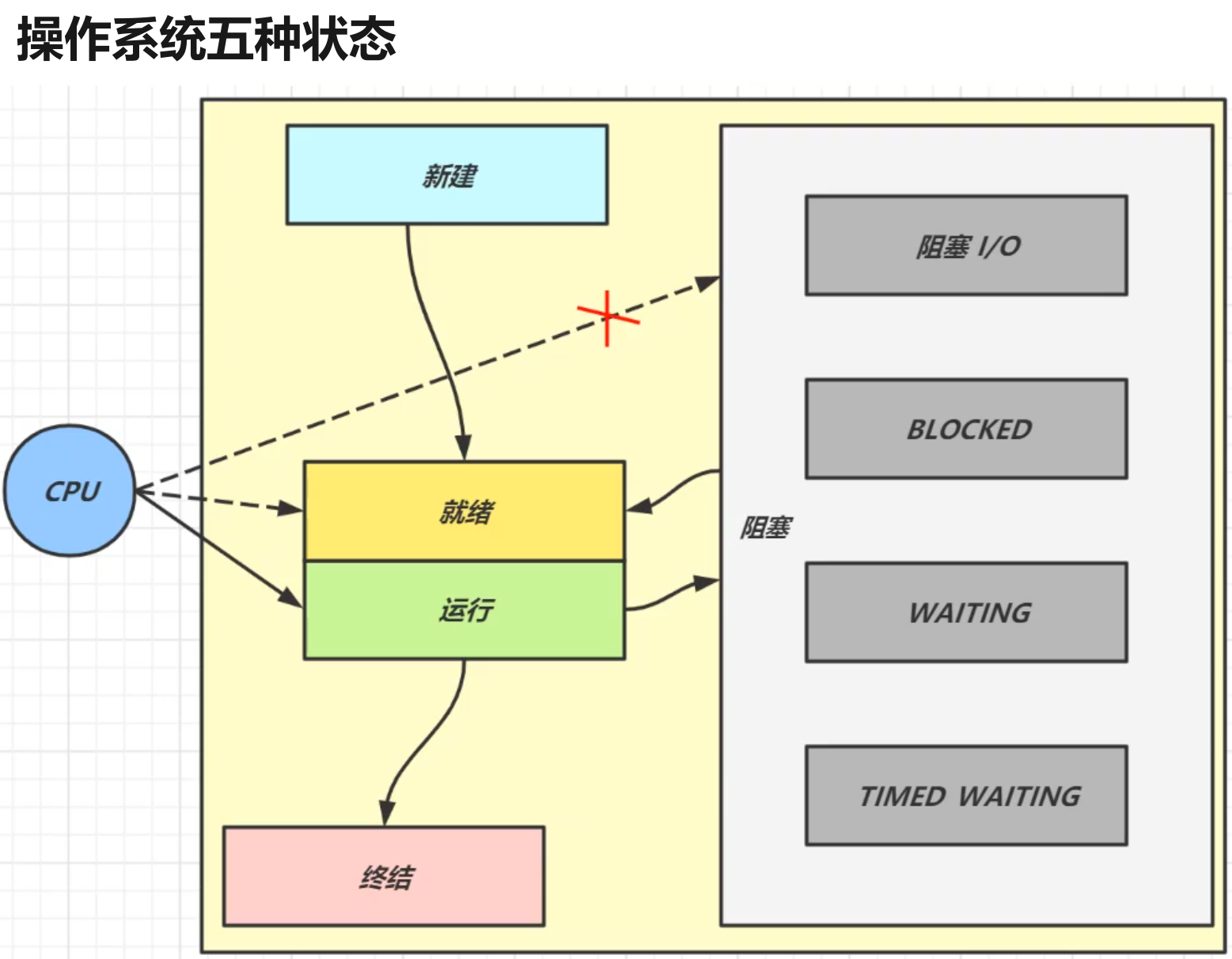
runnable 和 callable 有什么区别?
- Runnable 接口run方法没有返回值
- Callable接口call方法有返回值,是个泛型,和Future、FutureTask配合可以用来获取异步执行的结果
- Callable接口的call()方法允许抛出异常;而Runnable接口的run()方法的异常只能在内部消化,不能继续上抛
run() 和 start() 有什么区别?
start(): 用来启动线程,通过该线程调用run方法执行run方法中所定义的逻辑代码。只能被调用一次。run(): 封装了要被线程执行的代码,可以被调用多次。
notify() 和 notifyAll() 有什么区别?
notifyAll():唤醒所有阻塞状态的线程notify():顺序唤醒一个阻塞状态的线程
wait() 、 sleep() 和 yield() 有什么区别?
共同点:都是让当前线程暂时放弃 CPU 的使用权,进入阻塞状态
不同点:
- 方法归属不同
sleep(long)是 Thread 的静态方法wait()和wait(long)都是 Object 的成员方法
- 醒来时机不同
- 执行
sleep(long)和wait(long)的线程都会在等待相应毫秒后醒 wait(long)和wait()还可以被 notify 唤醒- 它们都可以被打断唤醒
- 执行
- 锁特性不同(重点)
wait()和wait(long)方法的调用必须先获取wait对象的锁,而sleep()则无此限制wait()和wait(long)方法执行后会释放对象锁,允许其它线程获得该对象锁sleep()如果在同步代码块中执行,并不会释放对象锁
总结:
Thread.yield():用于提示当前线程愿意放弃当前的CPU时间片,但不释放锁,也不阻塞当前线程。Thread.sleep():使当前线程进入暂停状态,但不释放锁、会阻塞当前线程。Object.wait():使当前线程进入等待状态,会释放锁,但会阻塞当前线程,直到被其他线程唤醒。
Thread.sleep(0) 的作用是什么?
看起来 Thread.sleep(0) 很奇怪,让线程睡眠 0 毫秒?那不是等于没睡眠吗?
是的,确实没有睡眠,但是调用了 Thread.sleep(0) 当前的线程会暂时出让 CPU ,这使得 CPU 的资源短暂的空闲出来别的线程有机会得到 CPU 资源。
所以,在一些大循环场景,如果害怕这段逻辑一直占用 CPU 资源,则可以调用 Thread.sleep(0) 让别的线程有机会使用 CPU。
实际上 Thread.yield() 这个命令也可以让当前线程主动放弃 CPU 使用权,使得其他线程有机会使用 CPU。
如何中断/停止正在运行的线程?
调用
interrupt()方法: 使用Thread.interrupt()方法中断线程。线程需要在适当的地方检查中断状态(如通过Thread.currentThread().isInterrupted()或捕获InterruptedException)并做出响应。javapublic void run() { try { while (!Thread.currentThread().isInterrupted()) { // 可能需要在适当的地方检查中断,尤其是阻塞操作前 // 执行任务... } } catch (InterruptedException e) { // 线程在等待/睡眠/ join等操作时可能被中断 // 清理工作 } finally { // 清理工作 } } // 在其他地方调用以请求中断 myThread.interrupt();使用volatile布尔标记: 创建一个volatile类型的布尔标记,作为线程是否应该继续运行的指示器。线程在运行过程中定期检查这个标记,如果标记变为
false,则线程自行结束。javaprivate volatile boolean running = true; public void run() { while (running) { // 执行任务... } // 清理工作 } public void stopThread() { running = false; }利用
Future和ExecutorService: 如果使用ExecutorService来管理线程,可以通过取消相关的Future任务来间接停止线程。javaExecutorService executor = Executors.newSingleThreadExecutor(); Future<?> future = executor.submit(() -> { // 执行任务... }); // 请求取消任务 future.cancel(true); // true表示应该中断正在执行的任务 executor.shutdownNow(); // 尝试停止所有活动的执行任务
避免使用已废弃的Thread.stop()、Thread.suspend()和Thread.resume()方法,因为这些方法可能会导致数据不一致性、死锁或其他不可预料的问题。正确的线程结束策略应当确保线程能够清理资源、释放锁并以一种安全的方式终止。
线程间的通信方式
在 Java 中,线程之间的通信是指多个线程协同工作,主要实现方式包括:
1)共享变量:
- 线程可以通过访问共享内存变量来交换信息(需要注意同步问题,防止数据竞争和不一致)。
- 共享的也可以是文件,例如写入同一个文件来进行通信。
2)同步机制:
synchronized:Java 中的同步关键字,用于确保同一时刻只有一个线程可以访问共享资源,利用 Object 类提供的wait()、notify()、notifyAll()实现线程之间的等待/通知机制ReentrantLock:配合 Condition 提供了类似于 wait()、notify() 的等待/通知机制BlockingQueue:通过阻塞队列实现生产者-消费者模式CountDownLatch:可以允许一个或多个线程等待,直到在其他线程中执行的一组操作完成CyclicBarrier:可以让一组线程互相等待,直到到达某个公共屏障点Semaphore:信号量,可以控制对特定资源的访问线程数volatile:Java 中的关键字,确保变量的可见性,防止指令重排AtomicInteger:可以用于实现线程安全的计数器或其他共享变量。
补充 Object 中的方法说明:
- Object 和 synchronized——wait()、notify()、notifyAll():使线程进入等待状态,释放锁。唤醒单个等待线程。唤醒所有等待线程。
- Lock 和 Condition——await()、signal():使持有ReentranLock锁的线程等待。唤醒持有ReentranLock锁的线程。
- BlockingQueue——put()、take():将元素放入阻塞队列。从队列中获取取元素
如果一个线程在被调用两次 start() 方法会发生什么?
会报错!因为在 Java 中,一个线程只能被启动一次!所以尝试第二次调用 start() 方法时,会抛出 IllegalThreadStateException 异常。
这是因为一旦线程已经开始执行,它的状态不能再回到初始状态。线程的生命周期不允许它从终止状态回到可运行状态。
死锁产生的条件是什么?如何避免死锁?如何诊断死锁?
死锁:一个线程需要同时获取多把锁,这时就容易发生死锁
死锁产生的条件:
- 互斥条件:每个资源只能被一个线程占用。
- 占有和等待:线程在持有至少一个资源的同时,等待获取其他资源。
- 不可抢占:线程所获得的资源在未使用完毕之前不能被其他线程抢占。
- 循环等待:多个线程形成一种头尾相接的循环等待资源关系。
避免死锁的方法:
- 按序申请资源:确保所有线程在获取多个锁时,按照相同的顺序获取锁。
- 尽量减少锁的范围:将锁的粒度尽可能缩小,减少持有锁的时间。可以通过拆分锁或使用更细粒度的锁来实现。
- 使用尝试锁机制:使用
ReentrantLock的tryLock方法,尝试在一段时间内获取锁,如果无法获取,则可以选择放弃或采取其他措施,避免死锁。 - 设置超时等待时间:为锁操作设置超时,防止线程无限期地等待锁。
- 避免嵌套锁:尽量避免在一个锁的代码块中再次尝试获取另一个锁。
死锁诊断:
使用jdk自带的工具:jps和 jstack
- 使用
jps查看运行的线程 - 第二:使用
jstack -l <进程ID>查看线程运行的情况
其他解决工具,可视化工具
- jconsole
用于对jvm的内存,线程,类的监控,是一个基于 jmx 的 GUI 性能监控工具
打开方式:java 安装目录 bin目录下 直接启动 jconsole.exe 就行
- VisualVM:故障处理工具
能够监控线程,内存情况,查看方法的CPU时间和内存中的对 象,已被GC的对象,反向查看分配的堆栈
打开方式:java 安装目录 bin目录下 直接启动 jvisualvm.exe就行
如何创建多线程?
常见有以下五种方式创建使用多线程:
1)实现 Runnable 接口:
- 实现
Runnable接口的run()方法,使用Thread类的构造函数传入Runnable对象,调用start()方法启动线程。 - 例子:
Thread thread = new Thread(new MyRunnable()); thread.start();
2)继承 Thread 类:
- 继承
Thread类并重写run()方法,直接创建Thread子类对象并调用start()方法启动线程。 - 例子:
MyThread thread = new MyThread(); thread.start();
3)使用 Callable 和 FutureTask:
- 实现
Callable接口的call()方法,使用FutureTask包装Callable对象,再通过Thread启动。 - 例子:
FutureTask<Integer> task = new FutureTask<>(new MyCallable()); Thread thread = new Thread(task); thread.start();
4)使用线程池(ExecutorService):
- 通过
ExecutorService提交Runnable或Callable任务,不直接创建和管理线程,适合管理大量并发任务。 - 例子:
ExecutorService executor = Executors.newFixedThreadPool(10); executor.submit(new MyRunnable());
5)CompletableFuture(本质也是线程池,默认 forkjoinpool):
- Java 8 引入的功能,非常方便地进行异步任务调用,且通过
thenApply、thenAccept等方法可以轻松处理异步任务之间的依赖关系。 CompletableFuture<Void> future1 = CompletableFuture.runAsync(() -> {});
CompletableFuture 的使用
Future 和 CompletableFuture 对比
- Future:表示异步计算的结果,可以查询结果是否可用,等待结果完成或取消计算。
- CompletableFuture:表示异步计算的一个阶段,可以与其他阶段组合形成复杂的异步流程。
创建任务
- runAsync:异步执行一个不返回结果的任务。
- supplyAsync:异步执行一个返回结果的任务。
// 创建一个不返回结果的异步任务
CompletableFuture<Void> future1 = CompletableFuture.runAsync(() -> {
System.out.println("future1");
});
// 创建一个返回结果的异步任务
CompletableFuture<String> future2 = CompletableFuture.supplyAsync(() -> {
return "future2";
});任务回调
- thenApply:在前一个任务完成后,返回一个新的
CompletableFuture。 - thenAccept:在前一个任务完成后,消费结果,不返回新结果。
- thenRun:在前一个任务完成后,执行一个不返回结果的操作。
CompletableFuture<String> future3 = future2.thenApply(result -> {
return result + " Welcome!";
});
future3.thenAccept(System.out::println); // 输出: future2 Welcome!组合任务
- thenCombine:合并两个 CompletableFuture 的结果。
- thenCompose:将一个 CompletableFuture 的结果作为另一个 CompletableFuture 的输入。
CompletableFuture<String> future1 = CompletableFuture.supplyAsync(() -> "Hello");
CompletableFuture<String> future2 = CompletableFuture.supplyAsync(() -> "World");
CompletableFuture<String> combinedFuture2 = future1.thenCombine(future2, (result1, result2) -> result1 + ", " + result2);
combinedFuture2.thenAccept(System.out::println); // Hello, World
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> "Hello").thenCompose(result -> CompletableFuture.supplyAsync(() -> result + ", World"));
future.thenAccept(System.out::println); // Hello, World (效果和上面一样)并行处理任务
- allOf:等待所有
CompletableFuture完成。 - anyOf:等待任何一个
CompletableFuture完成。
CompletableFuture<String> future4 = CompletableFuture.supplyAsync(() -> {
return "Task 1";
});
CompletableFuture<String> future5 = CompletableFuture.supplyAsync(() -> {
return "Task 2";
});
CompletableFuture<Void> allFutures = CompletableFuture.allOf(future4, future5);
allFutures.thenRun(() -> {
System.out.println("All tasks completed");
});
CompletableFuture<Object> anyFuture = CompletableFuture.anyOf(future4, future5);
anyFuture.thenAccept(result -> {
System.out.println("First completed task: " + result);
});处理异常
- exceptionally:在任务异常时执行一个回调函数。
- handle:无论任务是否异常,都会执行一个回调函数。
CompletableFuture<Object> future6 = CompletableFuture.supplyAsync(() -> {
throw new RuntimeException("Something went wrong");
}).exceptionally(ex -> "Exception occurred: " + ex.getMessage());
future6.thenAccept(System.out::println); // Exception occurred: java.lang.RuntimeException: Something went wrong
CompletableFuture<Object> future7 = CompletableFuture.supplyAsync(() -> {
throw new RuntimeException("Something went wrong");
}).handle((result, ex) -> {
if (ex != null) {
return ex.getMessage();
}
return result;
});
future7.thenAccept(System.out::println); // java.lang.RuntimeException: Something went wrong-------------------线程池-------------------
ForkJoinPool
ForkJoinPool 是Java 7引入的一个专门用于并行执行任务的线程池,它采用“分而治之”(divide and conquer)算法来解决大规模的并行问题。
核心机制:
- Fork(分解):任务被递归分解为更小的子任务,直到达到不可再分的程度。
- Join(合并):子任务执行完毕后,将结果合并,形成最终的解决方案。
工作窃取算法:ForkJoinPool使用了一种称为工作窃取的调度算法。空闲的工作线程会从其他繁忙线程的工作队列中“窃取”未完成的任务以保持资源高效利用。
关键类:
ForkJoinPool:表示Fork/Join框架中的线程池。ForkJoinTask:任务的基础抽象类,子类如RecursiveTask和RecursiveAction分别用于有返回值和无返回值的任务。
ForkJoinPool 与普通线程池的区别
有两方面的区别:
- 任务分解与合并:传统的线程池一般处理相对独立的任务,而ForkJoinPool则擅长处理可以分解的任务,最终将结果合并。
- 线程调度策略:普通的线程池通常由中央队列管理任务,而ForkJoinPool中的每个工作线程都维护着自己的双端队列,并通过工作窃取来平衡任务。
ForkJoinPool 与并行流的关系
ForkJoinPool 是并行流的爹!
Java 8中的并行流(Parallel Streams)底层是基于ForkJoinPool实现的。
Java 8中通过parallelStream()方法,可以轻松地利用ForkJoinPool来实现并行操作,从而提高处理效率。
线程池的原理、任务提交流程
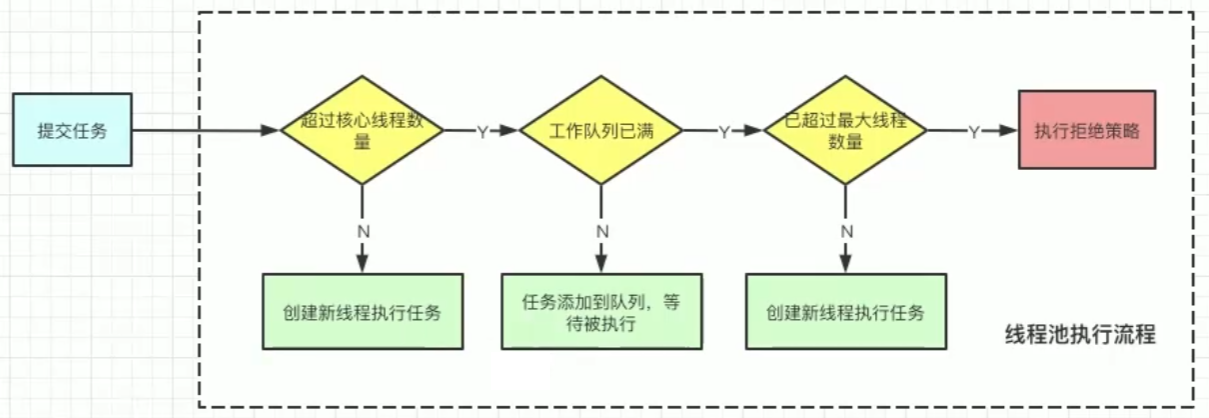
- 默认情况下线程不会预创建,任务提交之后才会创建线程。(不过设置 prestartAllCoreThreads 可以预创建核心线程)
- 如果工作线程少于
corePoolSize,则创建新线程来处理请求 - 如果工作线程等于或多于
corePoolSize,则将任务加入队列 - 如果无法将请求加入队列,则创建新的线程来处理请求
- 如果创建新线程使当前运行的线程超出
maximumPoolSize,则任务将被拒绝
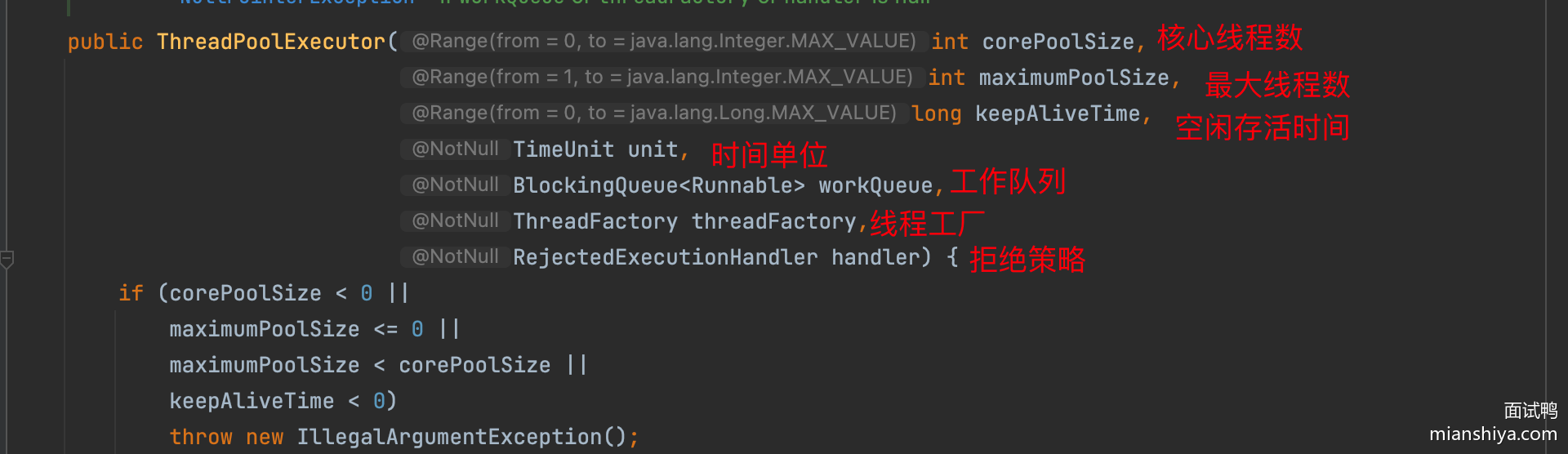
线程池的 7 个核心参数
用 ThreadPoolExecutor 类创建线程:
public class MyThreadPoolDemo3 {
public static void main(String[] args) {
ThreadPoolExecutor pool = new ThreadPoolExecutor(
2, // 参数一:核心线程数量
5, // 参数二:最大线程数
2, // 参数三:空闲线程最大存活时间
TimeUnit.SECONDS, // 参数四:存活时间单位
new ArrayBlockingQueue<>(10), // 参数五:任务队列
Executors.defaultThreadFactory(), // 参数六:线程工厂
//r -> new Thread(r, name:"myThread" + c.getAndIncrement(),
new ThreadPoolExecutor.AbortPolicy() // 参数七:任务的拒绝策略
);
pool.submit(new MyRunnable());
pool.submit(new MyRunnable());
pool.shutdown();
}
}
任务拒绝策略
| 任务拒绝策略 | 说明 |
|---|---|
| ThreadPoolExecutor.AbortPolicy | 丢弃任务并抛出RejectedExecutionException异常(默认) |
| ThreadPoolExecutor.DiscardPolicy | 丢弃任务,但是不抛出异常(不推荐) |
| ThreadPoolExecutor.DiscardoldestPolicy | 丢弃队列最前面的任务,然后重新尝试执行任务 |
| ThreadPoolExecutor.CallerRunsPolicy | 由调用线程处理该任务 |
自定义任务拒绝策略
可以实现 RejectedExecutionHandler 接口来定义自定义的拒绝策略。例如,记录日志或将任务重新排队。
public class CustomRejectedExecutionHandler implements RejectedExecutionHandler {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
System.out.println("mianshiya.com Task " + r.toString() + " rejected");
// 可以在这里实现日志记录或其他逻辑
}
}线程池可选用的阻塞队列
workQueue - 当没有空闲核心线程时,新来任务会加入到此队列排队,队列满会创建救急线程执行任务
比较常见workQueue 的有4个,用的最多是ArrayBlockingQueue和LinkedBlockingQueue
1.ArrayBlockingQueue:数组结构的有界阻塞队列。
2.LinkedBlockingQueue:链表结构的阻塞队列,大小无限。
3.DelayedWorkQueue :带优先级的无界阻塞队列。可以将执行时间最靠前的任务出队。
4.SynchronousQueue:不存储任务,直接将任务提交给线程。
ArrayBlockingQueue 和 LinkedBlockingQueue区别
| ArrayBlockingQueue | LinkedBlockingQueue | |
|---|---|---|
| 长度 | 有界 | 默认无界,支持有界 |
| 底层数据结构 | 数组 | 链表 |
| 创建方式 | 提前初始化 Node 数组,Node 需要是提前创建好的 | 懒性队列,添加数据的时候创建节点,入队会生成新 Node |
| 加锁方式 | 只有一把锁,读和写公用,性能较差 | 头尾两把锁,一把读、一把写,性能较好 |
线程池的 5 种状态
线程池的生命周期通常包括以下几个状态:
RUNNING:接受新的任务并且处理队列中的任务。SHUTDOWN:不再接受新任务,但是会继续处理队列中的任务。(调用shutdown()方法)STOP:不再接受新任务并且不处理队列中的任务,中断正在执行的任务。(调用shutdownNow()方法)TIDYING:所有的任务都已完成,正在执行终止前的清理工作。TERMINATED:线程池已完成清理工作,处于结束状态。
1. 线程池状态说明:
RUNNING:默认状态,可以正常接收任务并执行,处理工作队列的任务。SHUTDOWN:不再接受新任务,但会继续处理等待队列中的任务。STOP:既不接受新任务也不处理等待队列中的任务,中断正在执行的任务。TIDYING:所有任务结束,工作线程数为0,是一种过渡状态。TERMINATED:线程池终止状态,表示terminated()钩子函数调用完毕。
2. 状态之间的转换:
RUNNING -> SHUTDOWN:调用shutdown()方法导致线程池变为SHUTDOWN状态。(RUNNING 或 SHUTDOWN) -> STOP:调用shutdownNow()方法导致线程池变为STOP状态。SHUTDOWN -> TIDYING:当等待队列为空且工作线程数为0时,线程池从SHUTDOWN转为TIDYING状态。STOP -> TIDYING:同上,等待队列为空时,线程池从STOP转为TIDYING状态。TIDYING -> TERMINATED:调用terminated()钩子函数后,线程池从TIDYING转为TERMINATED状态。
Java中的 4 种默认线程池
使用ExecutorService可以创建许多类型的线程池:
FixedThreadPool:固定线程数量的线程池,可控制线程最大并发数,超出的线程会在队列中等待,允许的请求队列长度为Integer.MAX_VALUE,可能会堆积大量的请求,从而导致OOM
SingleThreadExecutor:单线程化的线程池,保证所有任务按照指定顺序执行,允许的请求队列长度为Integer.MAX_VALUE,可能会堆积大量的请求,从而导致OOM
CachedThreadPool:可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程,允许的创建线程数量为Integer.MAX_VALUE,可能会创建大量的线程,从而导致OOM
ScheduledThreadPool:可以执行延迟任务的线程池,支持定时及周期性任务执行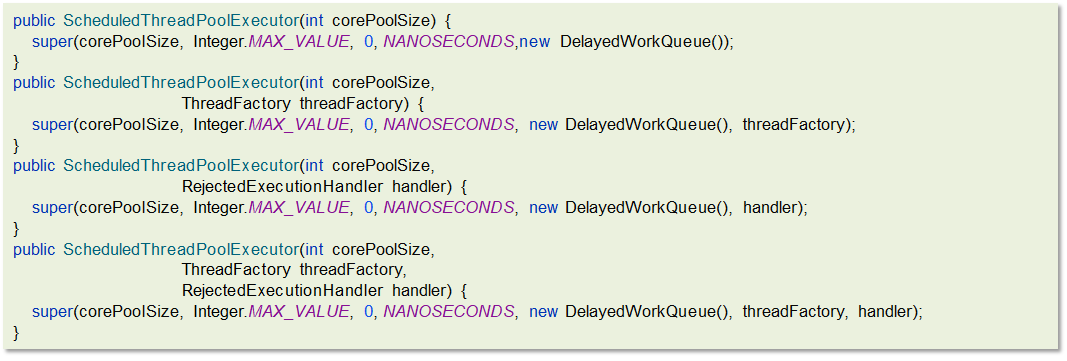
WorkStealingPool:基于任务窃取算法的线程池。线程池中的每个线程维护一个双端队列(deque),线程可以从自己的队列中取任务执行。如果线程的任务队列为空,它可以从其他线程的队列中"窃取"任务来执行,达到负载均衡的效果。适合大量小任务并行执行,特别是递归算法或大任务分解成小任务的场景。
如何确定线程池的线程数?
一般而言:
核心线程数 = CPU核心数
最大线程数 = CPU核心数 * 2
① CPU密集型任务:
- 高并发、任务执行时间短 -->( CPU核数 + 1 ),减少线程上下文的切换
② 资源密集型任务:
IO密集型的任务 --> (CPU核数 * 2)
计算密集型任务 --> ( CPU核数 + 1 )
③ 并发高、业务执行时间长:
- 关键不在于线程池而在于整体架构的设计,而是要通过缓存、服务器进行优化,通过压测来确定最优的线程池参数。
线程池调整原则
- 动态调整线程池大小时,需要确保新的配置不会导致系统资源耗尽。比如,过大的线程池可能会占用过多的 CPU 和内存,反而影响性能。
- 当系统负载发生变化时,可以使用动态调整来优化线程池的资源使用率,例如在系统负载增加时,临时提高核心线程数以应对突发流量,当系统负载下降时,可以减少核心线程数以节省资源。
- 当任务队列长度过长时,可以临时增加核心线程数,以加快任务的处理速度。
线程池监控与调整
- 在实际生产环境中,可以通过监控线程池的状态(如当前活跃线程数、队列长度等)来决定是否动态调整线程池大小。
- 可以使用 JMX(Java Management Extensions)来监控
ThreadPoolExecutor,结合指标来自动调整线程池大小以优化性能。
底层原理:线程池的execute()运行原理
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get(); // 获取线程池的状态和工作线程数量
// 判断当前工作线程数量是否小于核心线程数
if (workerCountOf(c) < corePoolSize) {
// 创建核心线程并执行任务
if (addWorker(command, true))
return; // 创建成功,任务由核心线程处理
c = ctl.get(); // 不成功则重新获取ctl
}
// 核心线程已达预期数量,尝试将任务分配给工作队列
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (!isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
} else if (!addWorker(command, false)) // 工作牌队列已满,分配非核心线程(临时线程)处理
reject(command); // 分配失败或非核心线程创建失败,执行拒绝策略
}底层原理:线程池的动态调整是如何保证线程安全的?
1. 使用 volatile 修饰 核心线程数 和 最大线程数
核心线程数corePoolSize 和最大线程数 maximumPoolSize 都是用 volatile 修饰的,保证了当这些字段被修改时,其他线程能够看到最新的值,而且不会发生指令重排序,确保了多线程环境下的可见性和有序性。
protected volatile int corePoolSize;
protected volatile int maximumPoolSize;2. 使用原子类记录关键信息
使用了 ctl 字段来保存线程池的一些关键状态信息,包括当前活跃线程数、线程池的状态等。这个字段是一个 long 类型,通过位操作来保存不同的状态信息。在修改线程池状态时,ThreadPoolExecutor 使用了 CAS(Compare and Swap)操作来保证原子性。
private volatile long ctl;例如,在创建新线程时,addWorker 方法会使用 compareAndSetWorkerCount 来更新线程池的当前线程数,这个操作是原子的。
protected boolean compareAndSetWorkerCount(int expect, int update) {
return ctl.compareAndSet(ctlOf(expect), ctlOf(update));
}线程池状态ctl
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static final int COUNT_BITS = Integer.SIZE - 3;
private static final int COUNT_MASK = (1 << COUNT_BITS) - 1;
// runState存储在高位
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
// 打包和解包ctl
private static int runStateOf(int c) { return c & ~COUNT_MASK; }
private static int workerCountOf(int c) { return c & COUNT_MASK; }
private static int ctlOf(int rs, int wc) { return rs | wc; }workerCountOf 方法
workerCountOf 方法是从 ctl 字段中提取当前活动线程的数量。ctl 字段是一个 volatile long 类型的变量,包含了线程池的一些状态信息,包括当前活动线程的数量。
ctl 的高几位表示线程池的状态信息,而低几位表示当前活动线程的数量。具体来说,ctl 的低 3 位(0-2)表示当前活动线程的数量。
interruptIdleWorkers 方法
interruptIdleWorkers 方法用来中断那些处于空闲状态的线程。该方法遍历所有工作线程,并中断那些处于空闲状态的线程。如果当前活动线程数仍然大于新的最大线程数,则会再次检查并中断空闲线程。
3. 使用锁
使用锁来保护共享资源的访问。
例如,在 interruptIdleWorkers 方法中,当需要中断空闲线程时,会获取 mainLock 来保护对 workers 集合的操作。
private void interruptIdleWorkers(boolean onlyOne) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// ...
} finally {
mainLock.unlock();
}
}4. 使用并发集合
使用了 ConcurrentHashMap 来管理 Worker 对象,这些对象代表了正在工作的线程。
private final ConcurrentHashMap<Integer, Worker> workers = new ConcurrentHashMap<>();底层原理:核心线程数的动态修改原理
public void setCorePoolSize(int corePoolSize) {
// 对传入的 corePoolSize 进行校验
if (corePoolSize < 0 || maximumPoolSize < corePoolSize)
throw new IllegalArgumentException();
// 更新当前的核心线程数
int delta = corePoolSize - this.corePoolSize;
this.corePoolSize = corePoolSize;
// 如果新的 corePoolSize 小于当前的核心线程数,那么需要中断那些处于空闲状态的线程
if (workerCountOf(ctl.get()) > corePoolSize)
interruptIdleWorkers();
// 如果新的 corePoolSize 大于当前的核心线程数,并且任务队列中有任务等待执行,那么需要预启动一些新的线程来处理这些任务
else if (delta > 0) {
int k = Math.min(delta, workQueue.size());
while (k-- > 0 && addWorker(null, true)) {
if (workQueue.isEmpty())
break;
}
}
}底层原理:最大线程数的动态修改原理
public void setMaximumPoolSize(int maximumPoolSize) {
// 对传入的 maximumPoolSize 进行校验
if (maximumPoolSize <= 0 || maximumPoolSize < corePoolSize)
throw new IllegalArgumentException();
// 更新当前的最大线程数
this.maximumPoolSize = maximumPoolSize;
// 如果新的 maximumPoolSize 小于当前的最大线程数,并且当前活动线程数大于新的 maximumPoolSize,则需要中断那些处于空闲状态的线程
if (workerCountOf(ctl.get()) > maximumPoolSize)
interruptIdleWorkers();
}如何避免线程池的线程被无限占用?
结合 awaitTermination:
无论是 shutdown() 还是 shutdownNow(),可以配合 awaitTermination() 方法等待线程池完全终止。awaitTermination() 会阻塞调用线程,直到线程池终止或超时。
比如以下的使用方式:
threadPool.shutdown();
try {
if (!threadPool.awaitTermination(60, TimeUnit.SECONDS)) {
threadPool.shutdownNow();
}
} catch (InterruptedException e) {
threadPool.shutdownNow();
Thread.currentThread().interrupt();
}这种组合方式常用于确保线程池能够在合理时间内关闭,避免无限等待或资源泄漏。
多次调用 shutdown()、shutdownNow() 会怎样?
再次调用不会有额外效果,只会在第一次调用时有效果。
而且,即使线程池进入 SHUTDOWN 状态,相关资源不会立即释放。必须等待所有线程完成任务,线程池进入 TERMINATED 状态后,资源才会释放。
Java 线程池内部任务出异常后,如何知道是哪个线程出了异常?
在Java中,线程池内部的任务如果抛出未捕获的异常,默认情况下这些异常会被记录到日志中,并且任务会被中断,但不会影响线程池本身继续执行其他任务。
如果你只需要处理个别任务的异常,那么包装任务或者使用Future.get()可能是更好的选择。
1. 使用Future和get()方法
任务到线程池后获取一个Future对象,调用Future.get()方法等待任务完成,并且如果任务执行过程中抛出异常,这个异常会被封装成ExecutionException重新抛出。
ExecutorService executor = Executors.newFixedThreadPool(10);
Future<?> future = executor.submit(() -> {
// 模拟任务
Thread.sleep(1000);
throw new RuntimeException("任务出错!");
});
try {
future.get(); // 等待任务完成
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
} catch (ExecutionException e) {
System.out.println("捕获到异常:" + e.getCause());
}如果你想对所有任务的异常进行统一处理,可以考虑使用自定义ThreadFactory或重写afterExecute方法。
2. 自定义ThreadFactory
可以通过自定义ThreadFactory来创建线程,并设置异常处理器。
ExecutorService executor = Executors.newFixedThreadPool(10, new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
Thread t = new Thread(r);
t.setUncaughtExceptionHandler((thread, throwable) -> {
System.out.println("线程 " + thread.getName() + " 抛出异常:" + throwable.getMessage());
});
return t;
}
});3. 使用ThreadPoolExecutor的afterExecute方法
可以重写ThreadPoolExecutor.afterExecute()方法来捕获任务执行后的异常。
ThreadPoolExecutor executor = new ThreadPoolExecutor(
10, 10, 0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()
);
executor.afterExecute = (r, e) -> {
if (e != null) {
System.out.println("任务抛出异常:" + e.getMessage());
}
};