
----------------分布式理论----------------
CAP定理
CAP 定理指出,在分布式系统中,不可能同时实现以下三个保证:
- 一致性(Consistency):所有节点在同一时刻看到相同的数据。
- 可用性(Availability):每个请求不管当前是否是集群的领导节点,都会收到系统的非错误响应。
- 分区容错性(Partition tolerance):即使存在信息丢失(即网络分区),系统仍然能继续运作。
根据 CAP 定理,一个分布式系统只能实现这三个特性中的两个。例如,可以选择一致性和分区容错性,放弃部分可用性;或者选择可用性和分区容错性,放弃一致性。
BASE理论
BASE 是 Basically Available(基本上可用)、Soft state(软状态)、Eventually consistent(最终一致性)这三个短语的首字母缩写。
BASE 是对 CAP 中 AP 选项的一种延伸,它强调的是即使不能保证强一致性,也可以通过牺牲一些一致性来换取系统的高可用性。
- 基本上可用(Basically Available):系统可以出现延迟增加的情况,但仍然能够处理请求,不会完全停止服务。
- 软状态(Soft state):允许系统内部的状态随着时间变化而变化,而不是始终维持不变。
- 最终一致性(Eventual Consistency):系统在经过一段时间后,会达到一个一致的状态。在这个过程中,系统可能会经历中间状态,这些状态可能不是一致的。
Raft选举算法(Kafka、etcd)
Raft算法于2014年提出,是一种易于理解、分布式强一致性的算法,它旨在简化 Paxos 算法的理解和实现。
Raft算法将节点分为三种状态:跟随者(Follower)、候选人(Candidate)和领导者(Leader)。
Raft 算法的主要步骤:
- 初始化状态:
- 每个节点初始状态都是跟随者(Follower)。
- 超时事件:
- 当跟随者没有在一定时间内接收到任何消息时(随机超时时间),它会变成候选人(Candidate)。
- 选举过程:
- 候选人发起选举,向其他节点发送投票请求(RequestVote RPC)。
- 其他节点接收到投票请求后,如果它们尚未投票给其他候选人,则可以投票给当前候选人。
- 如果候选人获得大多数节点的选票,则成为领导者(Leader)。
- 领导者的心跳机制:
- 领导者定期向所有节点发送心跳消息(AppendEntries RPC),以维持领导者的地位。
- 如果跟随者长时间未收到心跳消息,它会再次变成候选人并重新发起选举。
Paxos算法
略。
----------------分布式组件----------------
总结
| 功能 | 传统 Spring Cloud 组件 | Spring Cloud Alibaba 组件 |
|---|---|---|
| 注册中心 | Eureka | Nacos (同时作为配置中心) |
| 负载均衡 | Ribbon | Ribbon |
| 远程调用 / 服务调用 | Feign | Feign |
| 服务熔断 / 保护 | Hystrix | Sentinel |
| 服务网关 | Zuul | Gateway |
注册中心
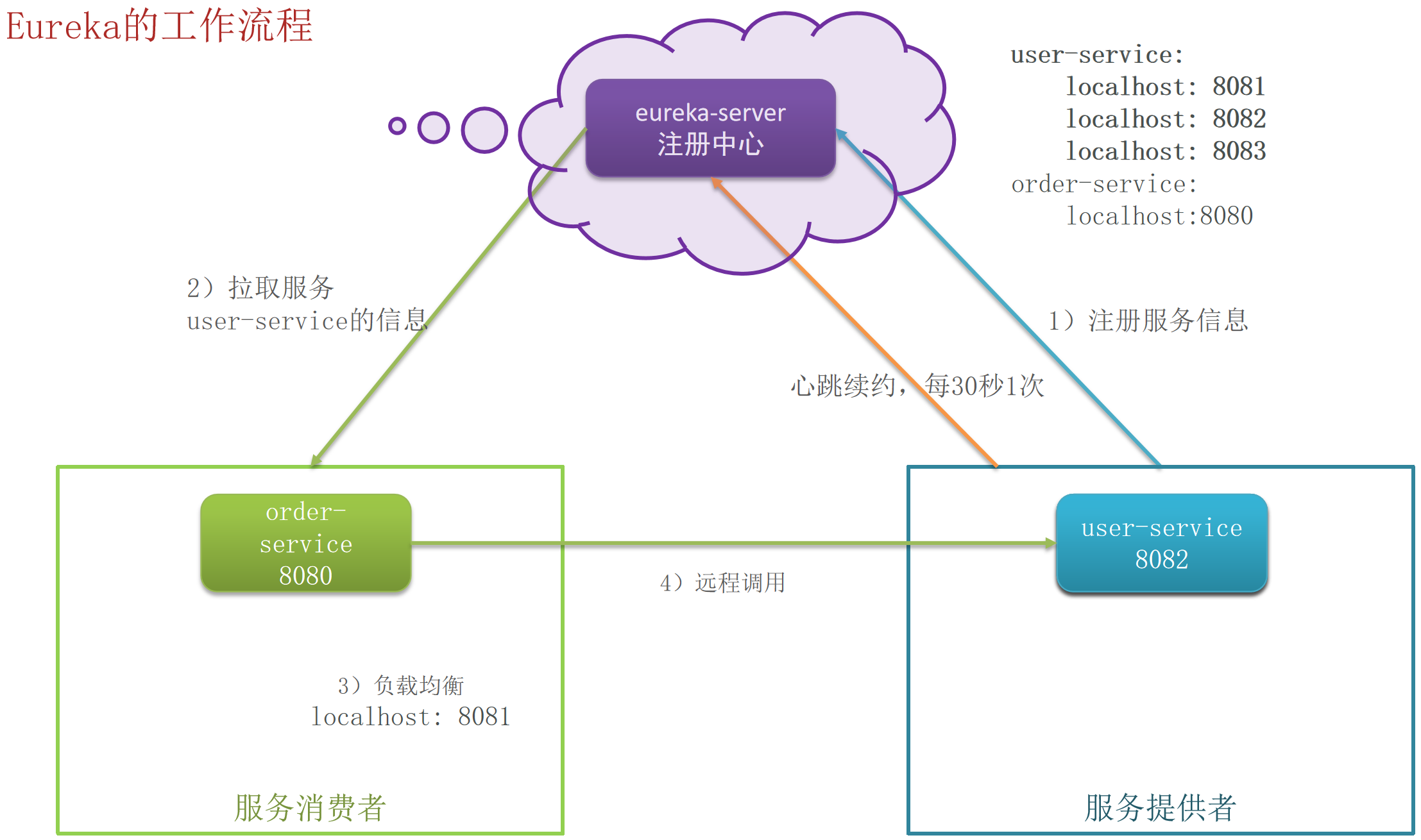
Eureka的工作流程
Nacos的工作流程
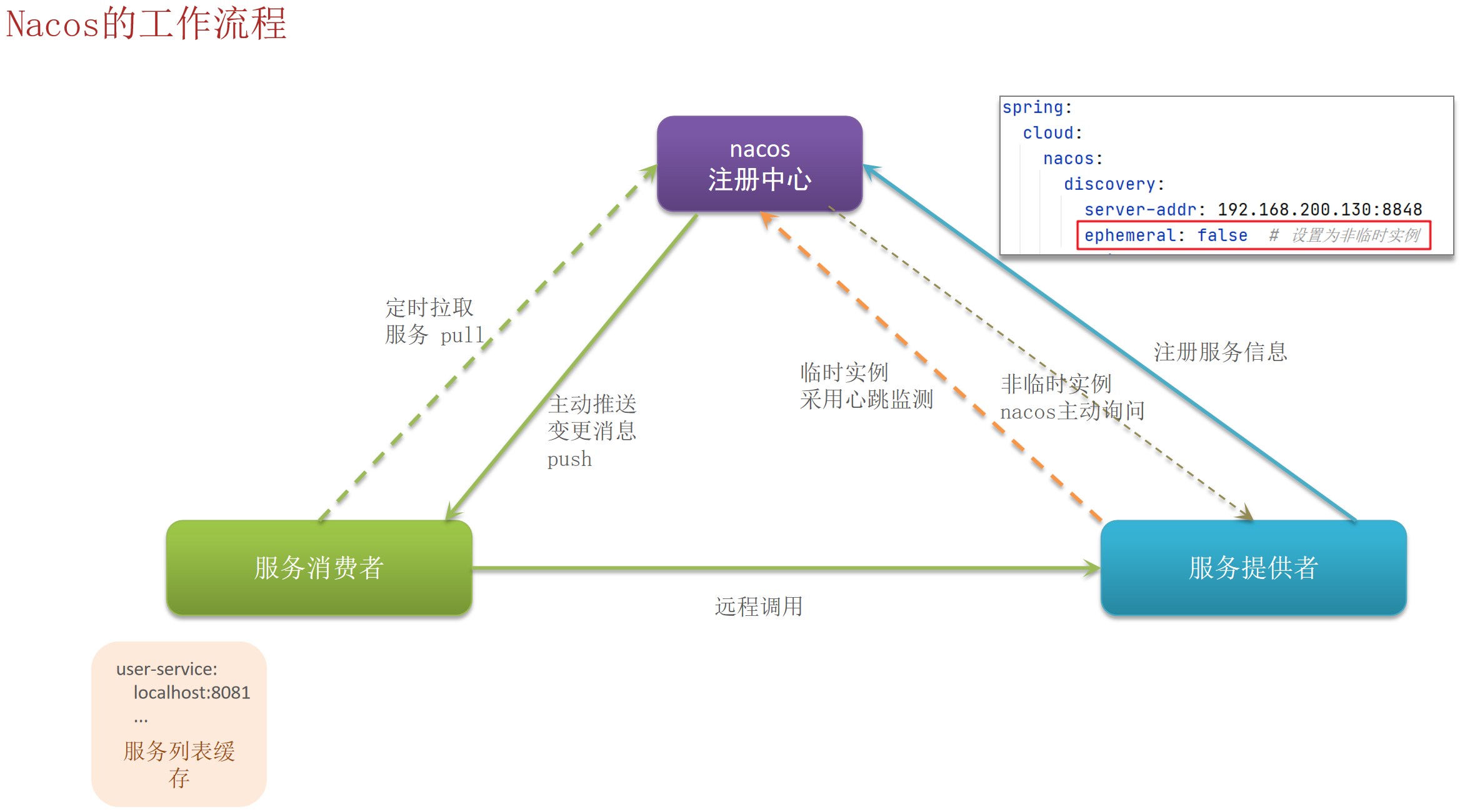
Nacos 与 Eureka 的功能对比
| 功能 | Nacos | Eureka |
|---|---|---|
| 服务注册 | 支持 | 支持 |
| 服务拉取 | 支持 | 支持 |
| 心跳检测 | 支持(临时实例) | 支持 |
| 主动检测 | 支持(非临时实例) | 不支持 |
| 异常实例剔除策略 | 选择性剔除(临时实例会,非临时实例不会) | 自动剔除 |
| 服务变更推送模式 | 支持主动推送,服务列表更新更及时 | 不支持,只能被动询问 |
| 一致性模型 | 默认 AP(高可用),非临时实例时CP(强一致) | 默认 AP(高可用) |
| 配置中心 | 支持 | 不支持 |
负载均衡
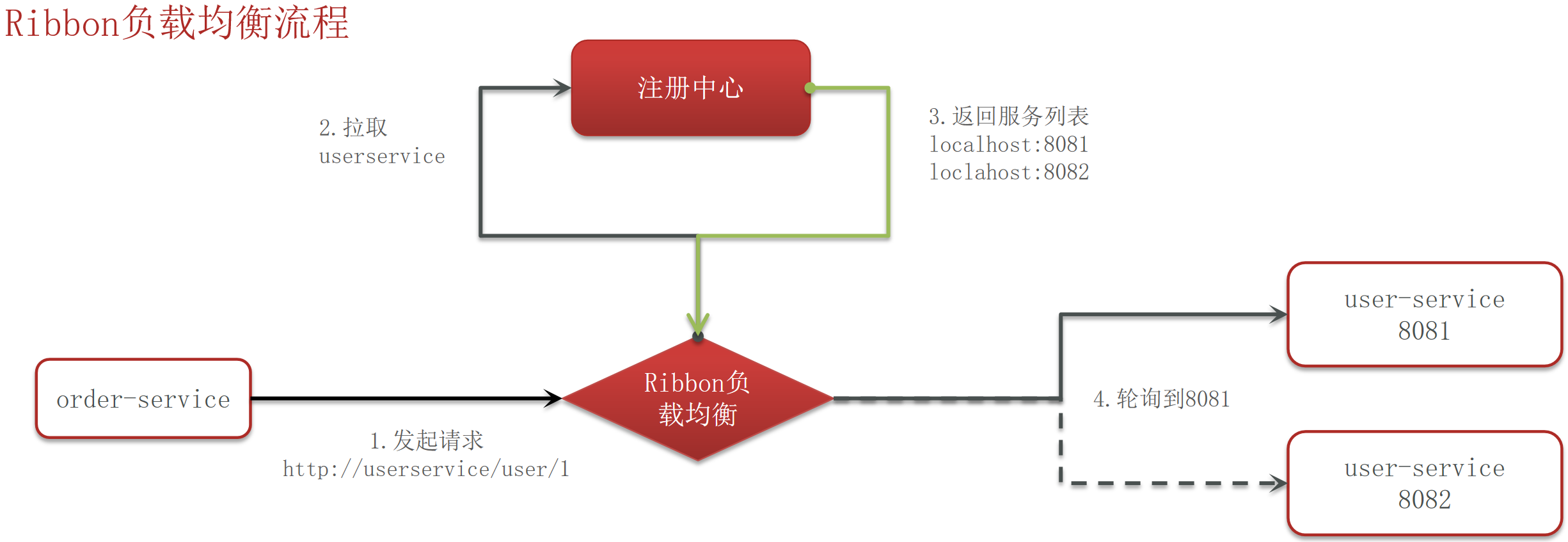
Ribbon的工作流程
Ribbon的负载均衡策略
静态轮询策略:
- RoundRobinRule:简单轮询
- WeightedResponseTimeRule:权重轮询。权重越小,响应时间越长
- RandomRule:随机轮询
- (非Ribbon)Sticky RoundRobin:粘性轮询。相同用户、IP等值的请求会轮询到同一个服务器。
- (非Ribbon)Hash RoundRobin:哈希轮询。根据IP、URL等值计算出一个哈希值来选择相应的服务器。
动态轮询策略:
BestAvailableRule:最少连接数
AvailabilityFilteringRule:先过滤不健康的,再选择最少连接数
(非Ribbon)Least Time:最短延迟。需要消耗额外资源,监控服务器的响应时间和处理能力。
ZoneAvoidanceRule:以区域可用的服务器为基础进行服务器的选择。使用Zone对服务器进行分类,这个Zone可以理解为一个机房、一个机架等。而后再对Zone内的多个服务做轮询
RetryRule:选择自定义的重试逻辑
yaml# application.yml service-name: ribbon: OkToRetryOnAllOperations: true # 是否所有操作都允许重试 MaxAutoRetriesNextServer: 2 # 切换到下一个服务实例的最大重试次数 MaxAutoRetries: 1 # 对同一服务实例的最大重试次数 ConnectTimeout: 1000 # 连接超时时间(毫秒) ReadTimeout: 3000 # 读取超时时间(毫秒)
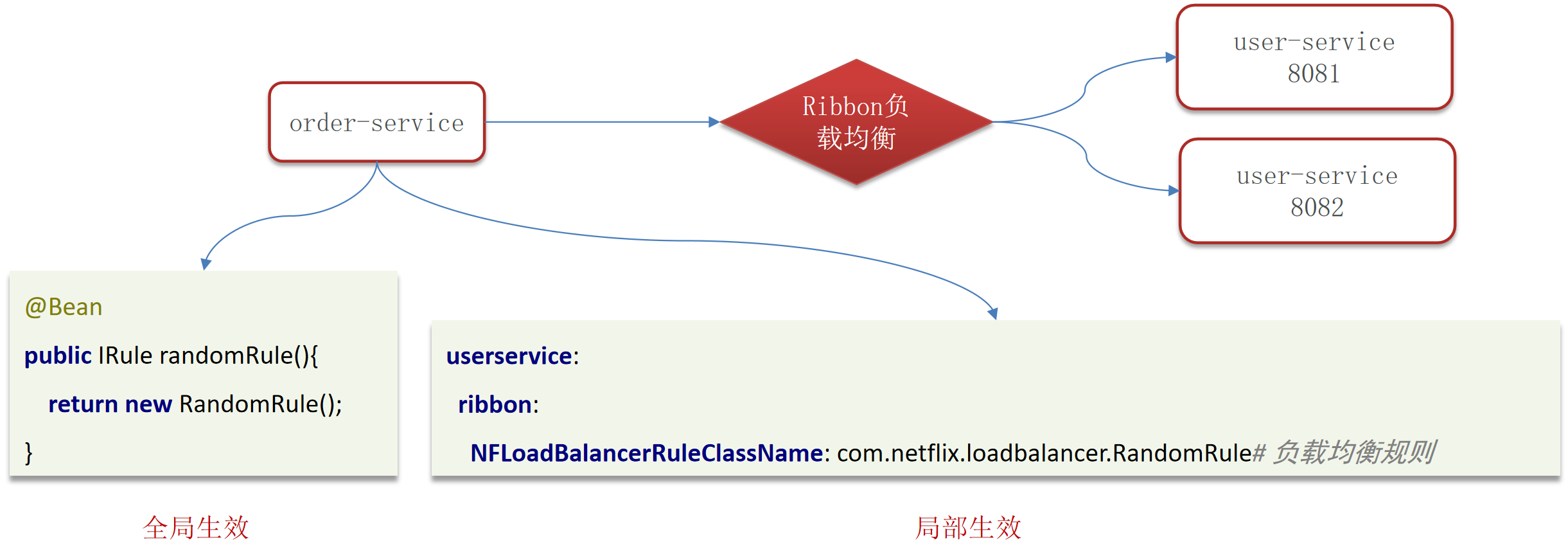
Ribbon实现自定义负载均衡策略
- 全局:实现IRule接口,在实现类中指定负载均衡策略
- 局部:在配置文件中,配置每一个服务调用的负载均衡策略
RPC框架
RPC:Remote Procedure Call ,即远程过程调用
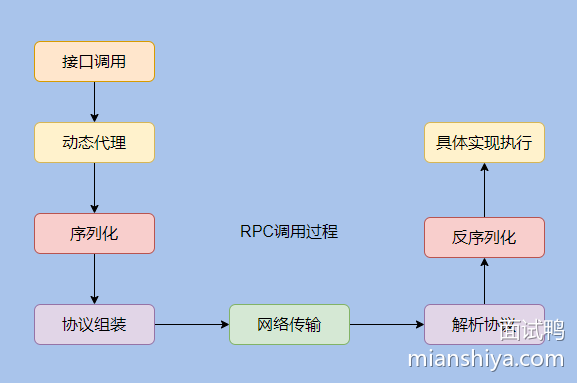
如何设计一个 RPC 框架?
其实就这么几点:
- 动态代理(屏蔽底层调用细节)
- 序列化(网络数据传输需要扁平的数据)
- 协议(规定协议,才能识别数据)
- 网络传输(I/O模型相关内容,一般用 Netty 作为底层通信框架即可)
生产级别的框架还需要注册中心作为服务的发现,且还需提供路由分组、负载均衡、异常重试、限流熔断等其他功能。
说到这就可以停下了,然后等面试官发问,正常情况下他会选一个点进行深入探讨,这时候我们只能见招拆招了。
细节:动态代理 / RPC的实现原理
通过动态代理实现的。
在 Dubbo 中用的是 Javassist,至于为什么用这个其实梁飞大佬已经写了博客说明了。
他当时对比了 JDK 自带的、ASM、CGLIB(基于ASM包装)、Javassist。
经过测试最终选用了 Javassist。
梁飞:最终决定使用JAVAASSIST的字节码生成代理方式。 虽然ASM稍快,但并没有快一个数量级,而Javassist的字节码生成方式比ASM方便,JAVAASSIST只需用字符串拼接出Java源码,便可生成相应字节码,而ASM需要手工写字节码。
RPC 会给接口生成一个代理类,我们调用这个接口实际调用的是动态生成的代理类,由代理类来触发远程调用,这样我们调用远程接口就无感知了。
动态代理中,最常见的技术就是 Spring AOP 了,涉及的有 JDK 动态代理和 cglib。
细节:序列化
**序列化原因:**网络传输的数据是“扁平”的,最终需要转化成“扁平”的二进制数据在网络中传输。
**序列化方案:**有很多序列化选择,一般需要综合考虑通用性、性能、可读性和兼容性。
序列化方案对比:
- 采用二进制的序列化格式数据更加紧凑
- 采用 JSON 等文本型序列化格式可读性更佳。
细节:协议
制定协议的原因:需要定义一个协议,来约定一些规范,制定一些边界使得二进制数据可以被还原。
一般 RPC 协议都是采用协议头+协议体的方式。
协议头:存放元数据,包括:魔法位、协议的版本、消息的类型、序列化方式、整体长度、头长度、扩展位等。
协议体:存放请求的数据。
通过魔法位可以得知这是不是咱们约定的协议,比如魔法位固定叫 233 ,一看我们就知道这是 233 协议。
然后协议的版本是为了之后协议的升级。
从整体长度和头长度我们就能知道这个请求到底有多少位,前面多少位是头,剩下的都是协议体,这样就能识别出来,扩展位就是留着日后扩展备用。
例如Dubbo 协议:

细节:网络传输
一般而言用的都是 IO 多路复用,因为大部分 RPC 调用场景都是高并发调用,IO 复用可以利用较少的线程 hold 住很多请求。
一般 RPC 框架会使用已经造好的轮子来作为底层通信框架。例如: Java 语言的都会用 Netty ,人家已经封装的很好了,也做了很多优化,拿来即用,便捷高效。
网关(Gateway)
如何实现过滤恶意攻击?
Spring Cloud Gateway 可以通过多种方式来实现对恶意攻击的过滤:
- 限流(Rate Limiting):
- 使用 RequestRateLimiterGatewayFilterFactory 过滤器来限制来自特定 IP 地址的请求频率。
- 可以根据 IP 地址或其他标识符限制请求频率,从而防止 DDoS 攻击。
- 黑名单(Blacklisting):
- 可以根据 IP 地址或其他标识符创建黑名单,拒绝来自黑名单中的请求。
- 白名单(Whitelisting):
- 只允许来自白名单中的请求通过,其他请求直接拒绝。
- 安全过滤器(Security Filters):
- 可以添加自定义的安全过滤器来检测和阻止恶意请求,如 SQL 注入、XSS 攻击等。
如何验证用户身份?
Spring Cloud Gateway 可以通过多种方式来实现用户身份验证:
- OAuth2 / OpenID Connect:
- 使用 OAuth2 或 OpenID Connect 来验证用户的令牌。
- 可以与 Keycloak、Auth0 等认证服务器集成,实现统一的身份验证。
- JWT(JSON Web Token):
- 使用 JWT 令牌来进行身份验证。
- 可以在请求头中携带 JWT 令牌,并在网关层解析和验证令牌的有效性。
- API 密钥(API Key):
- 使用 API 密钥进行身份验证。
- 可以在请求头或查询参数中传递 API 密钥,并在网关层验证密钥的有效性。
- 自定义认证逻辑:
- 可以添加自定义的过滤器来实现复杂的认证逻辑。
- 可以通过数据库查询用户的凭据,验证用户身份。
熔断 / 保护(Sentinel)
服务熔断和保护机制是微服务架构中常用的技术,用于提高系统的稳定性和可靠性。
Sentinel 是一个专门用于实现服务熔断、流量控制和系统保护等功能流行的开源项目。
Sentinel 是一个流量控制和熔断降级框架,可以在分布式系统中快速实现流量控制、熔断降级、系统自适应保护等功能。
Sentinel 提供了多种流量控制策略和熔断规则,能够有效防止雪崩效应,保障系统的稳定性和可用性。
Sentinel 的使用
1. 引入sentinel依赖的使用
<!-- Sentinel 依赖 -->
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-core</artifactId>
<version>1.8.3</version>
</dependency>
<!-- Sentinel 控制台客户端 -->
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-dashboard</artifactId>
<version>1.8.3</version>
</dependency>
<!-- Sentinel Spring Cloud 集成 -->
<dependency>
<groupId>com.alibaba.csp.sentinel</groupId>
<artifactId>sentinel-spring-cloud-gateway-adapter</artifactId>
<version>1.8.3</version>
</dependency>2. 配置 Sentinel
spring:
cloud:
sentinel:
transport:
dashboard: localhost:8080 # Sentinel 控制台地址3. 创建限流规则
@RestController
public class FlowController {
@PostConstruct
public void initFlowRules() {
List<FlowRule> rules = new ArrayList<>();
FlowRule rule = new FlowRule();
rule.setResource("hello");
rule.setGrade(RuleConstant.FLOW_GRADE_QPS);
rule.setCount(1); // 每秒最多处理 1 个请求(QPS)
rules.add(rule);
FlowRuleManager.loadRules(rules);
}
@GetMapping("/hello")
@SentinelResource("hello")
public String hello() {
return "Hello, World!";
}
}4. 创建熔断规则
@RestController
public class DegradeController {
@PostConstruct
public void initDegradeRules() {
List<DegradeRule> rules = new ArrayList<>();
DegradeRule rule = new DegradeRule();
rule.setResource("degrade");
rule.setGrade(DegradeRule.GRADE_EXCEPTION_COUNT); // 异常数熔断
rule.setCount(1); // 每分钟异常数超过 1 次时熔断
rule.setTimeWindow(10); // 熔断持续时间 10 秒
rules.add(rule);
DegradeRuleManager.loadRules(rules);
}
@GetMapping("/degrade")
@SentinelResource("degrade")
public String degrade() {
throw new RuntimeException("Degraded!");
}
}Sentinel 控制台
Sentinel 提供了一个图形化的控制台,可以实时监控和管理流量控制、熔断降级等规则。通过控制台,可以动态调整规则,而不需要重启应用。
启动控制台
下载 Sentinel 控制台:
shellgit clone https://github.com/alibaba/Sentinel.git cd Sentinel cd sentinel-dashboard构建并启动控制台:
shellmvn clean package -Dmaven.test.skip=true java -Dserver.port=8080 -Dcsp.sentinel.dashboard.server=localhost:8080 -Dproject.name=sentinel-dashboard -jar target/sentinel-dashboard.jar访问控制台: 访问
http://localhost:8080,使用默认用户名和密码sentinel登录。
------------------服务治理------------------
服务雪崩(Service Cascading)
服务雪崩:一个服务失败导致整条链路的服务都失败的情形。
解决:
- 服务熔断(Hystrix ):默认关闭,需要手动在引导类上添加注解
@EnableCircuitBreaker。如果检测到 10 秒内请求的失败率超过 50%,就触发熔断机制。之后每隔 5 秒重新尝试请求微服务,如果微服务不能响应,继续走熔断机制。如果微服务可达,则关闭熔断机制,恢复正常请求
- 服务降级(Feign):服务自我保护的一种方式,或者保护下游服务的一种方式,用于确保服务不会受请求突增影响变得不可用,确保服务不崩溃,一般在实际开发中与feign接口整合,编写降级逻辑
@FeignClient(value = "leadnews-article", fallback = IArticleClientFallback.class)
public interface IArticleClient {
@PostMapping("/api/v1/article/save")
public ResponseResult saveArticle(@RequestBody ArticleDto dto);
}@Component
public class IArticleClientFallback implements IArticleClient {
@Overridepublic ResponseResult saveArticle(ArticleDto dto) {
return ResponseResult.errorResult(AppHttpCodeEnum.SERVER_ERROR,"获取数据失败");
}
}如何监控微服务?有哪些检测工具?
常见APM工具:
Springboot-admin
Prometheus、Grafana
zipkin
Skywalking
Skywalking的监控流程:
- 用skywalking监控接口、服务、物理实例的一些状态。特别是在压测的时候了解哪些服务和接口比较慢,可以针对性的分析和优化。
- 在skywalking设置告警规则,如果报错可以给相关负责人发短信和发邮件,第一时间知道项目的bug情况,第一时间修复。
服务熔断(Circuit Breaker)
Sentinel的实现见上
服务熔断是一种保护机制,当一个服务出现故障或响应超时时,暂时停止对该服务的请求,直到其恢复正常。这样可以防止因单个服务的问题而导致整个系统崩溃。
实现服务熔断的方法包括:
- Hystrix:Netflix开源的容错库,支持服务熔断、超时和降级等功能。
- Resilience4j:轻量级的Java库,提供服务熔断等容错机制。
- Spring Cloud CircuitBreaker:基于Spring Boot的API,简化了服务熔断的集成。
- Envoy:边车代理可以集成服务熔断功能。
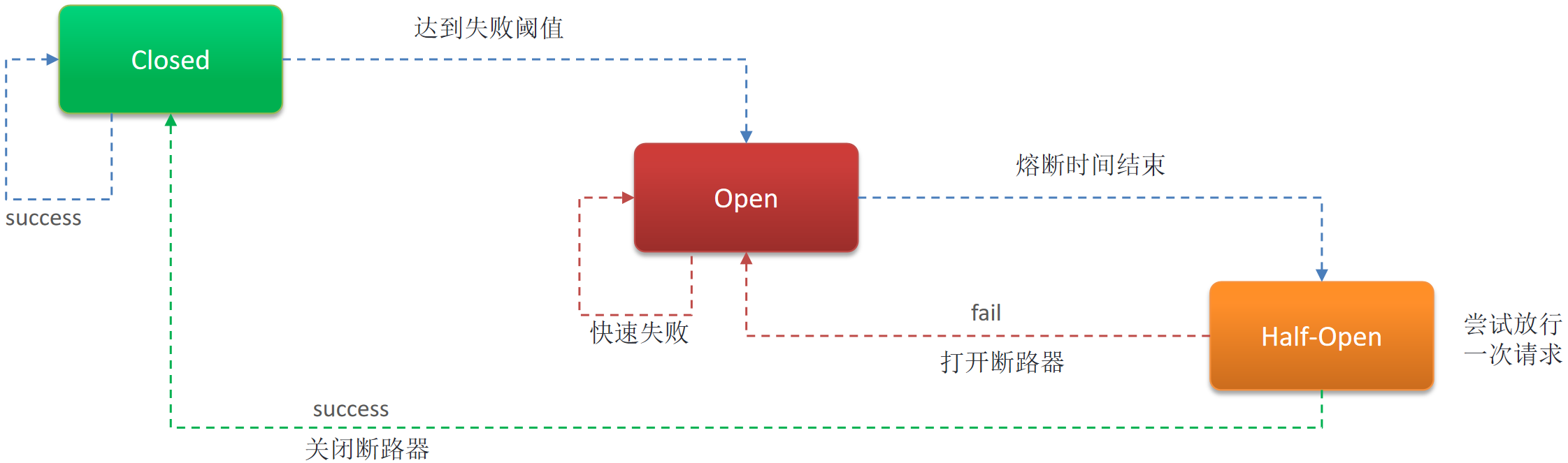
如何实现服务熔断:
- 监控请求:监控对积分模块的请求情况,包括成功率、响应时间等。
- 设置阈值:定义触发熔断的条件,如请求成功率低于一定比例、响应时间超过设定阈值等。
- 打开断路器:当达到阈值时,断路器打开,暂时阻止请求。
- 重试机制:设置重试间隔和次数,尝试重新建立连接。
- 半开放状态:在一定时间后,进入半开放状态,允许少量请求通过,以检查服务是否恢复正常。
- 关闭断路器:如果服务恢复正常,断路器关闭,恢复请求。
服务降级(Degradation)
服务降级是在系统面临过载时,主动降低服务质量,以保证核心功能的正常运作。
例如:可以暂时关闭积分模块中的非关键功能,以释放资源。
服务降级策略
- 预设降级策略:定义在何种情况下启动降级机制,如CPU使用率过高、内存不足等。
- 实现降级逻辑:在代码中实现降级逻辑,如返回默认值、简化处理流程等。
- 动态配置:根据实际情况动态调整降级策略,如通过配置中心实时更新。
- 记录降级事件:记录降级发生的次数和原因,便于后续分析和改进。
服务限流(Rate Limiting)
限制单位时间内请求的数量,防止服务被过多请求压垮。
服务限流算法及实现
总结
- 令牌桶算法:平滑处理突发流量,适用于需要灵活调整限流策略的场景。
- 漏桶算法:平滑处理突发流量,适用于简单的限流需求。
- 计数器算法:简单易用,适用于简单的限流需求。
- 滑动窗口算法:细粒度控制,适用于需要更精确限流的场景。
令牌桶算法(Token Bucket)
原理:
- 预先分配一定数量的令牌,每次请求消耗一个令牌,当令牌用尽时,拒绝请求。通过一个固定的令牌桶来控制请求的速率。令牌以恒定的速率生成并放入桶中,请求到来时需要消耗一个令牌。如果桶中没有令牌,则拒绝请求。
优点:
- 平滑处理突发流量,避免短时间内的请求激增。灵活性高,可以调整令牌生成速率和桶的容量。
缺点:
- 实现相对复杂,需要管理令牌的生成和消费。
实现:
- 初始化一个令牌桶,设置桶的容量和令牌生成速率。
- 每隔固定时间生成一个令牌,放入桶中。
- 每次请求到来时,检查桶中是否有令牌,如果有则消耗一个令牌,否则拒绝请求。
public class TokenBucketLimiter {
private final AtomicInteger tokenBucket;
private final int capacity;
private final int refillRate; // 每秒生成的令牌数
private final ScheduledExecutorService scheduler;
public TokenBucketLimiter(int capacity, int refillRate) {
this.capacity = capacity;
this.refillRate = refillRate;
this.tokenBucket = new AtomicInteger(capacity);
this.scheduler = Executors.newSingleThreadScheduledExecutor();
startRefill();
}
private void startRefill() {
scheduler.scheduleAtFixedRate(() -> {
int currentTokens = tokenBucket.get();
if (currentTokens < capacity) {
tokenBucket.incrementAndGet();
}
}, 1, 1, TimeUnit.SECONDS);
}
public boolean tryAcquire() {
while (true) {
int currentTokens = tokenBucket.get();
if (currentTokens == 0) {
return false;
}
if (tokenBucket.compareAndSet(currentTokens, currentTokens - 1)) {
return true;
}
}
}
}漏桶算法(Leaky Bucket)
原理:请求进入一个固定容量的桶中,以恒定的速度流出,当桶满时,拒绝新的请求。通过一个固定的漏桶来控制请求的速率。请求进入漏桶后,以恒定的速率流出。如果漏桶已满,则拒绝新的请求。
优点:平滑处理突发流量,避免短时间内的请求激增。实现相对(令牌桶)简单。
缺点:对突发流量的处理能力有限,可能会导致部分请求被拒绝。
实现:
- 初始化一个漏桶,设置桶的容量和流出速率。
- 每次请求到来时,检查桶中是否有空间,如果有则放入桶中,否则拒绝请求。
- 每隔固定时间从桶中移出一个请求。
public class LeakyBucketLimiter {
private final Queue<Long> bucket;
private final int capacity;
private final int leakRate; // 每秒流出的请求数
private final ScheduledExecutorService scheduler;
public LeakyBucketLimiter(int capacity, int leakRate) {
this.capacity = capacity;
this.leakRate = leakRate;
this.bucket = new LinkedList<>();
this.scheduler = Executors.newSingleThreadScheduledExecutor();
startLeaking();
}
private void startLeaking() {
scheduler.scheduleAtFixedRate(() -> {
for (int i = 0; i < leakRate && !bucket.isEmpty(); i++) {
bucket.poll();
}
}, 1, 1, TimeUnit.SECONDS);
}
public boolean tryAcquire() {
if (bucket.size() < capacity) {
bucket.offer(System.currentTimeMillis());
return true;
} else {
return false;
}
}
}计数器算法(Counter)
原理:
- 基于时间窗口的请求数统计,设置最大连接数。在一个固定的时间窗口内统计请求的数量,如果超过了设定的阈值,则拒绝后续的请求。
优点:
- 简单,容易理解。成本低,性能开销小。
缺点:
- 时间窗口边缘的问题:如果在时间窗口的最后几秒钟有大量的请求,而在下一个时间窗口的开始几秒钟也有大量的请求,可能会导致短时间内超过阈值的情况。
实现:
- 初始化一个计数器和一个时间窗口。
- 每次请求到来时,增加计数器的值。
- 如果计数器的值超过设定的阈值,则拒绝请求。
- 当时间窗口结束时,重置计数器。
public class CounterLimiter {
private final AtomicInteger counter = new AtomicInteger(0);
private final int threshold;
private final long windowTime; // 时间窗口,单位:毫秒
private long startTime;
public CounterLimiter(int threshold, long windowTime) {
this.threshold = threshold;
this.windowTime = windowTime;
this.startTime = System.currentTimeMillis();
}
public boolean tryAcquire() {
long currentTime = System.currentTimeMillis();
if (currentTime - startTime >= windowTime) {
counter.set(0);
startTime = currentTime;
}
if (counter.get() < threshold) {
counter.incrementAndGet();
return true;
} else {
return false;
}
}
}滑动窗口算法(Sliding Window)
原理:
- 将计数器细分成多个更小的时间窗口。通过将时间窗口划分为多个小的时间段(桶),每个时间段记录请求的数量。当新的请求到来时,根据当前时间所在的桶来统计请求数量,从而实现更细粒度的限流。
优点:
- 细粒度控制,避免了固定时间窗口的边缘问题。
- 更精确地反映最近一段时间内的请求情况。
缺点:
- 实现相对复杂,需要管理多个时间段的计数。
实现:
- 初始化一个数组或环形缓冲区,每个元素代表一个小的时间段。
- 每次请求到来时,找到当前时间所在的小时间段,增加该时间段的计数。
- 如果总请求数量超过设定的阈值,则拒绝请求。
- 定期清除过期的时间段。
public class SlidingWindowLimiter {
private final AtomicIntegerArray buckets;
private final int bucketSize;
private final int threshold;
private final long windowTime; // 时间窗口,单位:毫秒
private final long bucketTime; // 每个桶的时间,单位:毫秒
private long startTime;
public SlidingWindowLimiter(int threshold, long windowTime, int bucketSize) {
this.threshold = threshold;
this.windowTime = windowTime;
this.bucketSize = bucketSize;
this.buckets = new AtomicIntegerArray(bucketSize);
this.bucketTime = windowTime / bucketSize;
this.startTime = System.currentTimeMillis();
}
public boolean tryAcquire() {
long currentTime = System.currentTimeMillis();
int currentIndex = (int) ((currentTime - startTime) / bucketTime) % bucketSize;
// 清除过期的桶
for (int i = 0; i < bucketSize; i++) {
if ((currentTime - startTime) / bucketTime - i > bucketSize) {
buckets.set(i, 0);
}
}
int totalRequests = 0;
for (int i = 0; i < bucketSize; i++) {
totalRequests += buckets.get(i);
}
if (totalRequests < threshold) {
buckets.incrementAndGet(currentIndex);
return true;
} else {
return false;
}
}
}----------------分布式事务----------------
分布式事务是指跨越多个数据库或分布式系统的事务。
分布式事务 与 传统事务 的区别
相同点:
- ACID特性:分布式事务和传统事务都遵循ACID(原子性、一致性、隔离性、持久性)特性,保证事务的正确性和完整性。
- 保证数据一致性:无论是分布式事务还是传统事务,都致力于确保事务操作在执行完毕后数据的一致性。
- 提供事务管理:分布式事务和传统事务都提供了事务管理机制,可以控制事务的提交、回滚和隔离级别。
不同点:
- 分布式环境:分布式事务通常在多个独立的节点或系统之间进行操作,而传统事务通常在单个数据库或系统中进行操作。
- 事务管理协议:传统事务通常使用本地事务管理机制(如JDBC事务、Spring事务管理),而分布式事务需要使用分布式事务管理协议(如XA协议、TCC协议)来实现跨多个系统的事务一致性。
- 性能开销:由于涉及多个系统的通信和协调,分布式事务通常比传统事务具有更高的性能开销和复杂度。
- 故障处理:在分布式环境下,出现故障或网络问题可能会导致事务的不确定状态,需要额外的机制来保证事务的正确性。
- 可伸缩性:传统事务在面对大规模的并发请求时可能会成为性能瓶颈,而分布式事务可以通过拆分事务、分布式锁等措施来提高可伸缩性。
常见的分布式事务解决方案
为了确保分布式事务的ACID,有以下常见的分布式事务解决方案:
1. 两阶段提交(Two-Phase Commit, 2PC)【XA 协议、Atomikos、Bitronix】
最传统的分布式事务协议之一。包括准备阶段和提交阶段,其中协调者与参与者进行交互以决定是否提交或回滚事务。
- 准备阶段:协调者询问所有参与者是否准备好提交事务。
- 提交阶段:如果所有参与者都同意,则协调者命令所有参与者提交;如果任何一个参与者不同意,则协调者命令所有参与者回滚。
2. 三阶段提交(Three-Phase Commit, 3PC)【SAGA、TCC(Try-Confirm-Cancel)、最终一致性】
3PC是在2PC的基础上增加了预表决阶段,以减少阻塞情况的发生。
- 预表决阶段:协调者向参与者发送预表决请求。
- 准备阶段:参与者回复预表决结果。
- 提交阶段:根据参与者回复的结果,协调者发送提交或回滚指令。
3. 单边提交(One-Sided Commit)【AP系统、DDD架构】
在这种方案中,参与者独立决定是否提交事务,而不需要等待协调者的指示。
这减少了事务处理时间,但增加了协调复杂度。
常用的分布式服务四种接口幂等性方案
幂等性:两次操作的结果一致。
- 业务属性保障幂等:利用主键生成器或者唯一性约束确保数据库的数据唯一;
- 额外的状态字段与业务逻辑控制:根据状态判断工作流程
- 申请预置令牌:
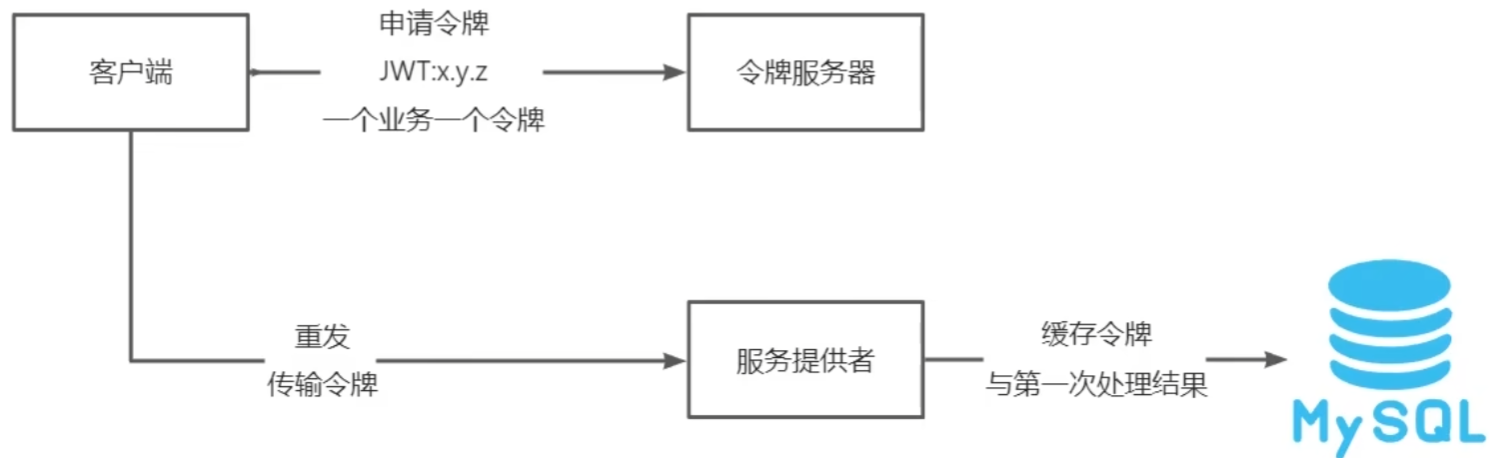
- 本地消息事件表:

Xxl-Job 路由策略?任务执行失败了怎么解决?
Xxl-Job 是一款轻量级分布式的任务调度框架,主要用于解决定时任务的分布式调度问题。它支持多种路由策略,也提供了任务执行失败后的处理机制。
Xxl-Job 的路由策略
Xxl-Job 支持多种任务分配策略,可以根据业务需求选择合适的策略来分配任务到不同的执行器。以下是几种常见的路由策略:
- FIRST:第一个执行器执行。
- ROUND:轮询分发,按照顺序依次分发给不同的执行器。
- HASH:根据指定的参数进行 hash 后取模分发。
- CONSISTENT_HASH:一致性哈希算法分发。
- RANDOM:随机分发。
- BUCKET4:四分桶分发,将执行器分为四个桶,根据任务触发时间分配到不同的桶中执行。
- BUCKET8:八分桶分发,类似于四分桶,但是分成八个桶。
Xxl-Job 任务执行失败的解决方法
当 Xxl-Job 的任务执行失败时,可以采取以下措施来解决问题:
- 查看日志
首先查看任务执行的日志,了解具体的错误原因。Xxl-Job 提供了任务执行日志功能,可以在界面上查看历史执行记录及其输出日志。
- 调整任务执行超时时间
如果是因为任务执行时间过长而导致超时失败,可以适当调整任务的执行超时时间。
- 重试机制 Xxl-Job 支持配置任务的重试次数。如果任务执行失败,可以配置重试机制来自动重新执行任务。
- 失败回调 配置失败回调机制,当任务执行失败时,可以触发回调函数进行额外的处理逻辑,比如记录失败信息、通知相关人员等。
- 监控与报警 设置监控报警机制,当任务执行失败时及时收到报警通知,以便及时介入处理。
- 执行器故障排查 如果任务执行失败是由于执行器本身的问题,比如执行器所在的服务器资源不足、程序异常等,需要排查执行器的问题。
- 调整任务执行策略 如果是由于任务执行策略不合理导致的任务失败,可以考虑调整任务的触发策略、执行器的分配策略等。
- 代码调试 如果是任务逻辑本身的问题,可以通过调试代码来找到并修复问题所在。
总之,解决 Xxl-Job 任务执行失败的方法主要是通过排查日志、调整配置、优化任务逻辑等方式来解决。具体的方法需要根据实际情况灵活选择。
怎么解决大数据量的任务并发执行?
处理大数据量的任务同时执行时,面临的挑战主要集中在资源消耗、数据处理速度、并发控制等方面。以下是一些常见的解决方案和技术手段:
分批处理(Batch Processing) 将大数据量分割成小批量数据,然后逐批处理。这种方法可以降低单次处理的数据量,从而减少内存占用和提高处理效率。
异步处理(Asynchronous Processing) 使用消息队列(如 RabbitMQ、Kafka 等)来异步处理数据。这样可以将大量数据放入队列中,然后由多个消费者并发处理,提高处理速度。
多线程或多进程(Multithreading/Multiprocessing) 利用多线程或多进程技术来并发处理数据。这种方式可以充分利用多核 CPU 的能力,提高处理速度。
分布式处理(Distributed Processing) 采用分布式计算框架(如 Hadoop MapReduce、Apache Spark、Flink 等)来分散数据处理任务。这些框架可以将数据切片并行处理,并自动处理数据分发、容错等问题。
水平扩展(Horizontal Scaling) 通过增加更多的服务器来分散负载。水平扩展意味着增加更多的实例来处理更多的请求,而不是在单一节点上增加更多的资源。
缓存机制(Caching) 使用缓存来减轻数据库的压力。对于频繁读取的数据,可以将其缓存起来,减少对数据库的访问频率。
限流(Rate Limiting) 为了避免瞬间大量请求导致系统崩溃,可以设置限流机制来控制请求速率。
优先级队列(Priority Queue) 使用优先级队列来处理不同重要级别的任务。这样可以确保重要任务优先得到处理。
动态调度(Dynamic Scheduling) 根据实时负载动态调整资源分配,确保资源的有效利用。
实施建议
- 评估需求:首先明确任务的具体需求,包括数据量大小、处理时间限制、可用资源等。
- 性能测试:在实施任何方案之前,进行性能测试以确定最佳方案。
- 逐步实施:从小规模开始实施,逐步扩大规模,确保方案的可行性和稳定性。
- 持续优化:随着业务的发展,不断调整和优化方案,确保系统的高效运行。
通过上述方法和技术手段,可以有效地应对大数据量任务的同时执行带来的挑战。
-----------------架构设计-----------------
例:讲一下分布式 ID 发号器的原理
设计目标
- 全局唯一性:生成的 ID 必须在分布式系统中全局唯一。
- 高性能:生成 ID 的操作应该是高效的,不会成为系统瓶颈。
- 可扩展性:随着系统的扩展,ID 发号器也应能够轻松扩展。
- 容错性:即使部分节点失效,系统也应该能够继续正常工作。
- 无中心依赖:减少对单一中心服务的依赖,以提高系统的可用性。
实现原理:Snowflake 算法
Snowflake 算法生成的 ID 是一个 64 位的整数,格式如下:
| 0(1 bit) | 时间戳(41 bit) | 工作机器 ID(10 bit) | 序列号(12 bit) |
|---|---|---|---|
| 0 | 123456789012345678901234567890123456789012345678901234567890 | 00000000000 | 000000000000 |
- 标记位:1 位,占位符。
- 时间戳:41 位的时间戳,可以使用大约 69 年。
- 工作机器 ID:5 位,可以标识不同的机器。
- 序列号:12 位,可以支持同一毫秒内生成的多个 ID。
优点: 生成的 ID 是有序的、高性能、适合高并发场景、实现简单。
缺点: 需要时间同步、如果机器 ID 分配不当,可能会导致冲突。
例:讲一下扫码登陆的原理
在验证码登录场景中,服务器生成 token 并与 PC 端通信的流程通常是通过以下步骤完成的:
1. PC 端请求二维码
- PC 端向服务器请求生成一个二维码(通常是一个唯一的
sessionId或uuid)。 - 服务器生成一个唯一的
sessionId,并将这个sessionId绑定到当前 PC 端的会话。 - 服务器将这个
sessionId编码成二维码图片,发送给 PC 端展示。
2. 手机扫描二维码
- 用户通过手机扫描 PC 端的二维码。
- 手机端读取二维码中的
sessionId并向服务器发送一个请求,表示要确认登录。此请求通常包含用户的登录凭证(例如验证码、短信验证码等)和从二维码中提取的sessionId。
3. 服务器验证并生成 Token
- 服务器接收到手机端的请求后,首先验证手机端提供的登录凭证是否合法。
- 如果验证通过,服务器为该用户生成一个唯一的登录 Token(例如 JWT 或 Session Token),表示用户已成功登录。
- 服务器会将生成的 Token 和手机端扫描二维码时传入的
sessionId进行绑定。
4. 通知 PC 端
- PC 端在二维码展示期间,会不断向服务器发送请求进行轮询(或使用 WebSocket 建立长连接),以查询该
sessionId的状态是否已被确认登录。 - 一旦服务器确认手机端登录成功,服务器会在轮询或 WebSocket 通信中通知 PC 端该
sessionId已绑定 Token。 - 服务器将生成的 Token 发送给 PC 端,PC 端收到 Token 后可以将其存储在 Cookie 或 LocalStorage 中,并以此作为用户身份进行后续操作。
5. PC 端登录成功
- PC 端收到服务器发送的 Token 后,即可认为用户已登录成功。
- 随后 PC 端可以使用这个 Token 访问服务器的受保护资源,例如个人主页或其他服务。
关键流程总结:
- 二维码生成:PC 端获取一个唯一的
sessionId,并展示对应二维码。 - 手机扫描确认:手机端扫描二维码后,将
sessionId和登录凭证提交给服务器。 - 服务器生成 Token:服务器验证通过后,生成用户的登录 Token 并将其与
sessionId绑定。 - PC 端获取 Token:PC 端通过轮询或 WebSocket 等方式,接收服务器发来的 Token,从而完成登录。
通信方式:
- 轮询(Polling):PC 端通过短时间间隔向服务器轮询请求,检查
sessionId的登录状态。 - WebSocket:PC 端和服务器通过 WebSocket 建立长连接,服务器在 Token 生成后通过 WebSocket 将 Token 直接推送给 PC 端。
通过这种方式,服务器知道要将 Token 发送给哪个 PC 端,因为 sessionId(二维码)在 PC 端和服务器之间建立了唯一的关联。
例:购物商城应对大流量、大并发的三类策略
这其实是个缓存预热的问题,具体我已经写在了My Java Guide - 缓存中了,这里不多说了!
友情链接:缓存预热和大流量冲击的应对策略
分流
主要是将流量分散到不同的系统和服务上,以减轻单个服务的压力。常见的方法有水平扩展、业务分区、分片和动静分离。
- 水平扩展:通过增加服务器数量来提高访问量和读写能力,如商品读库和商品写库。
- 业务分区:根据业务领域划分成不同的子系统,如商品库和交易库。
- 分片:根据不同业务类型进行分片,如秒杀系统从交易系统中分离;非核心业务分离。
- 动静分离:将动态页面降级为静态页面,整体降级到其他页面,以及部分页面内容降级。
降级
当系统压力过大时,采取一些措施降低服务质量,以保障关键功能的正常运行。
- 页面降级:对页面进行降级处理,如整体降级到其他页面,或者只保留部分内容。
- 业务功能降级:放弃一些非关键业务,如购物车库存状态。
- 应用系统降级:对下游系统进行降级处理,如一次拆分暂停。
- 数据降级:远程服务降级到本地缓存,如运费。
限流
限制请求的数量,以保护系统资源和稳定性。
- Nginx前端限流:京东研发的业务路由,规则包括账户、IP、系统调用逻辑等。
- 应用系统限流:客户端限流和服务端限流。
- 数据库限流:红线区,力保数据库。
例:如何设计一个秒杀功能?
1. 系统架构设计
前端:
页面静态化
- 使用静态页面来减少对服务器的压力,仅在秒杀开始时发送请求。
秒杀按钮控制
使用 JavaScript 控制秒杀按钮的状态,确保只有在秒杀开始时才能点击。
增加防刷机制,如限制短时间内请求频率、验证码等。
后端:处理秒杀逻辑,包括库存扣减、订单生成等。
- 读多写少场景
- 缓存:使用 Redis 等缓存技术存储商品信息和库存,减少对数据库的直接访问。
- 异步处理:使用消息队列(如 RabbitMQ、Kafka)处理秒杀请求,异步生成订单。
- 库存处理
- 预扣库存:秒杀开始前提前扣减库存,避免高并发时库存不足。
- 回滚机制:用户在规定时间内未支付订单,则释放库存。
- 限流
- 令牌桶:使用令牌桶算法限制请求速率。
- 漏桶:使用漏桶算法平滑请求。
负载均衡:使用负载均衡器(如 Nginx、HAProxy)分散请求压力。
微服务架构:将秒杀功能拆分为独立的服务,便于扩展和维护。
2. 数据存储设计
数据库设计
读写分离
- 主从复制:数据库采用主从复制,减轻单一数据库的压力。
事务处理
乐观锁:使用乐观锁机制防止库存超卖,如使用版本号或 CAS(Compare and Swap)操作。
悲观锁:在极端情况下使用悲观锁,但需注意性能影响。
缓存设计
缓存穿透
使用布隆过滤器预先过滤不存在的商品 ID。
缓存空值,减少对数据库的无效请求。
缓存击穿
预热缓存:秒杀开始前将所有商品信息加载到缓存中。
使用分布式锁或 TTL(Time To Live)策略防止缓存击穿。
分布式锁
- 使用 Redis 的 SETNX 或 Redlock 算法实现分布式锁,防止并发操作导致的数据不一致。
3. 安全性(防作弊)
- 限制 IP 地址的访问频率。
- 检测异常请求模式。
- 使用 CAPTCHA 或 reCAPTCHA 验证码。
4. 测试
- 性能测试:使用 JMeter 或 LoadRunner 进行压力测试。
- 功能测试:确保系统在各种边界条件下表现正常。
- 兼容性测试:测试不同浏览器和设备上的表现。
5. 监控与日志
- 性能监控:使用 Prometheus、Grafana 等工具实时监控系统性能。
- 错误日志:记录系统运行时的错误信息,便于问题排查。
6. 秒杀接口示例(Java Spring Boot)
@RestController
public class SeckillController {
@Resource
StringRedisTemplate redisTemplate;
@GetMapping("/seckill/{productId}")
@Transactional
public String seckillProduct(@PathVariable("productId") String productId) {
// 检查库存
String stockKey = "product_stock_" + productId;
String stockValue = redisTemplate.opsForValue().get(stockKey);
if (stockValue == null || Integer.parseInt(stockValue) <= 0) {
return "库存不足";
}
// 扣减库存
redisTemplate.opsForValue().decrement(stockKey);
// 生成订单
// ...
return "秒杀成功";
}
}例:订单超时自动取消的功能
- 数据库层:增加订单状态和过期时间字段,配合定时任务清理。
- 全局定时批量处理(存在延后取消问题)
- 服务层:
- 基于消息队列延时特性(如RabbitMQ的TTL队列)。在订单创建后,向TTL队列投放定时任务,任务超时前付款就取消任务,任务超时后未付款就将该任务投放到死信队列,死信消费者来处理订单状态。
- 使用分布式锁配合ScheduledExecutorService。在订单创建时,启动一个定时任务,该任务会在预设的时间后尝试关闭订单。为了防止多个实例同时处理同一个订单,需要使用分布式锁来保证操作的原子性。
*例:统计某家店铺销量 top 50 的商品?
1. 数据收集与存储
首先,通过一个可靠的数据收集和存储系统来记录每次销售的商品信息。这些消息包括但不限于:
商品ID、销售数量、销售时间、其他相关属性(如价格、类别等)2. 数据汇总
对于销售数据,你需要定期或者实时地汇总销售情况。这可以通过以下几种方式实现:
批处理(Batch Processing):使用批处理框架(如 Apache Hadoop、Apache Spark)来定期(如每天)汇总销售数据,并计算出每个商品的总销量。然后将结果存储在一个易于查询的地方,如另一个数据库表或文件系统。
实时处理(Real-time Processing):使用流处理框架(如 Apache Kafka + Apache Flink 或 Apache Spark Streaming)来实时处理销售数据。这种方法可以更快地得到最新的销售排名信息。
3. 排序与展示
SQL 查询
SELECT product_id, product_name, SUM(quantity) AS total_quantity
FROM sales
WHERE shop_id = ?
GROUP BY product_id
ORDER BY total_quantity DESC
LIMIT 50;API 接口
GET /shops/{shopId}/top-products?limit=50返回的 JSON 格式数据示例如下:
[
{"product_id": 114514, "product_name": “商品A”, "total_quantity": 1000},
{"product_id": 1919810, "product_name": “商品B”, "total_quantity": 950},
...
]4. 缓存策略
为了加快响应速度,使用缓存技术(如 Redis)来存储最近的查询结果。
当有新的销售数据到来时,可以更新缓存中的数据,而不是每次都重新计算。
5. 前端展示
前端应用可以使用现代 JavaScript 框架(如 React、Vue.js 或 Angular)来展示销售排名。可以使用图表库(如 ECharts、Chart.js)来可视化展示数据。
6. 安全与权限管理
使用认证和授权机制,确保只有授权的商家才能访问自己店铺的销售数据。
7. 性能优化
- 索引优化:确保在
sales销售表上有适当的索引来加速查询。 - 分页处理:如果数据量非常大,可以考虑使用分页来减少单次请求的数据量。
*例:如何设计一个点赞功能?
1. 前端交互逻辑
点赞/取消点赞操作:当用户点击点赞按钮时,前端向后端发送一个请求,包含点赞用户的 ID 和被点赞的朋友圈动态的 ID。
2. 后端设计
数据库设计
- 朋友圈动态表:记录每条动态的信息,包含动态的 ID、作者、内容、图片等。
- 点赞表:记录点赞的关系,可以使用关联表的方式来存储点赞数据。表中至少包含点赞用户的 ID 和被点赞的朋友圈动态的 ID。
-- 动态表
CREATE TABLE posts (
id INT AUTO_INCREMENT PRIMARY KEY,
user_id INT NOT NULL,
category_type INT NOT NULL DEFAULT 0,
topic_id INT NOT NULL DEFAULT 0,
content TEXT NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
modified_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
is_deleted INT NOT NULL DEFAULT 0,
);
-- 点赞表
CREATE TABLE likes (
id INT AUTO_INCREMENT PRIMARY KEY,
post_id INT NOT NULL,
user_id INT NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
modified_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
is_deleted INT NOT NULL DEFAULT 0,
FOREIGN KEY (post_id) REFERENCES posts(id),
FOREIGN KEY (user_id) REFERENCES users(id),
UNIQUE KEY unique_like (post_id, user_id)
);API 接口
@PostMapping("/posts/{postId}/likes")
public Result<String> likePost(@PathVariable Integer postId, @RequestParam Integer userId) {
// 检查点赞是否已存在
if (likeService.existsLikeForUser(postId, userId)) {
// 如果存在则删除点赞
likeService.removeLike(postId, userId);
return Result.ok("取消点赞成功");
} else {
// 创建新的点赞
Like like = new Like();
like.setPostId(postId);
like.setUserId(userId);
likeService.addLike(like);
return Result.ok("点赞成功");
}
}前后端实时通信
可以在前端实现实时点赞数的更新。当有新的点赞或取消点赞事件发生时,后端可以推送更新到前端,前端接收到更新后立即刷新页面。
设置 WebSocket 服务器
@Configuration
@EnableWebSocket
public class WebSocketConfig implements WebSocketConfigurer {
private final WebSocketHandler webSocketHandler;
public WebSocketConfig(WebSocketHandler webSocketHandler) {
this.webSocketHandler = webSocketHandler;
}
@Override
public void registerWebSocketHandlers(WebSocketHandlerRegistry registry) {
registry.addHandler(webSocketHandler, "/websocket").setAllowedOrigins("*");
}
}public class WebSocketHandler extends TextWebSocketHandler {
private static final Set<WebSocketSession> sessions = Collections.synchronizedSet(new HashSet<>());
@Override
public void afterConnectionEstablished(WebSocketSession session) throws Exception {
sessions.add(session);
}
@Override
public void afterConnectionClosed(WebSocketSession session, CloseStatus status) throws Exception {
sessions.remove(session);
}
public void broadcast(String message) {
synchronized (sessions) {
for (WebSocketSession session : sessions) {
try {
session.sendMessage(new TextMessage(message));
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
@Override
protected void handleTextMessage(WebSocketSession session, TextMessage message) throws Exception {
// Handle incoming messages if needed
}
}处理点赞事件:每当有新的点赞或取消点赞事件发生时,后端需要将这些事件广播给所有连接的客户端。
public void handleLikeEvent(LikeEvent event) {
// 更新数据库中的点赞数等
updateDatabase(event);
// 构造消息
String message = "{\"type\": \"LIKE\", \"postId\": " + event.getPostId() + ", \"newCount\": " + event.getNewCount() + "}";
// 广播消息
webSocketHandler.broadcast(message);
}3. 数据统计
- 点赞统计:可以定期汇总点赞数据,生成报告或图表,帮助分析用户行为。
- 热门动态推荐:根据点赞数排序,推荐热门动态给用户。
4. 安全性
- 认证与授权:确保只有登录用户才能进行点赞操作,并且只能点赞自己的朋友发布的动态。
- 防刷票:采取措施防止恶意刷票,如限制点赞频率、验证用户身份等。
5. 性能优化
- 缓存:使用缓存(如 Redis)来存储热点数据,减少数据库访问频率。
- 异步处理:点赞操作可以异步处理,提高用户体验。
*例:如何防止用户重复提交?
出现场景:
- 前端按钮
- 卡顿刷新
- 恶意操作
会带来的问题:
- 数据重复错乱
- 增加服务器压力
解决方案:
1. 按钮置灰:点击一次后按钮置灰。
实现方式:
- 在页面中添加监听按钮的点击事件。
- 当点击事件触发时,在执行请求之前,先禁用该按钮。
- 请求完成后(无论成功还是失败),定时重启按钮。
2. 唯一索引:在数据库层面建议一个数据的唯一id。
实现方式:
- 在数据库表中设置一个字段作为唯一标识符,例如订单号、事务ID等。
- 当插入新记录时,检查这个字段是否已经存在。
- 如果冲突,则返回错误给前端告知无法重复提交。
3. 自定义注解 / 拦截器:通过 userId + URL + 类名+ 方法名 是否重复提交
实现方式:
开发一个注解,放在触发器的方法上,用于检查特定的方法上的重复提交。
或:开发一个自定义的拦截器或过滤器,用于检查每次请求。(记得将自定义拦截器注册到WebMVC组件中哦)
给注解设置一个key,如
userId + URL + 类名 + 方法名。使用Redis存储这些防重复提交锁,并设置过期时间。
在接收到请求时,检查这些信息是否已存在于存储中,如果存在则认为是重复请求,可以拒绝处理。
拦截器的代码实现:
@Component
@Slf4j
public class RepeatSubmitInterceptor implements HandlerInterceptor {
@Autowired
private JwtProperties jwtProperties;
@Autowired
private JwtUtil jwtUtil;
@Autowired
private StringRedisTemplate redisTemplate;
public RepeatSubmitInterceptor(StringRedisTemplate redisTemplate) {
this.redisTemplate = redisTemplate;
}
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) {
String token = request.getHeader(jwtProperties.getUserTokenName());
Claims claims = jwtUtil.parseJWT(jwtProperties.getUserSecretKey(), token);
Long userId = Long.valueOf(claims.get(JwtClaimsConstant.USER_ID).toString());
String key = userId + request.getRequestURI() + request.getClass() + request.getMethod() + request.getParameterMap();
if (Boolean.TRUE.equals(redisTemplate.opsForValue().setIfAbsent(key, "1", 5, TimeUnit.SECONDS))) {
return true; // 允许请求继续
} else {
// 拒绝重复请求
response.setStatus(HttpStatus.TOO_MANY_REQUESTS.value());
return false;
}
}
}@Configuration
@Slf4j
public class WebMvcConfiguration extends WebMvcConfigurationSupport {
@Autowired
private RepeatSubmitInterceptor repeatSubmitInterceptor;
//注册自定义拦截器
protected void addInterceptors(InterceptorRegistry registry) {
log.info("开始注册自定义拦截器...");
registry.addInterceptor(repeatSubmitInterceptor)
.addPathPatterns("/hello/**");
}
...
}*例:设计一个简单的JWT令牌身份检验功能
配置文件
hzx:
jwt:
admin-secret-key: hzx_admin # 设置jwt签名加密时使用的秘钥
admin-ttl: 7200000 # 设置jwt过期时间
admin-token-name: token # 设置前端传递过来的令牌名称
user-secret-key: hzx_user
user-ttl: 7200000
user-token-name: authenticationJWT配置文件类
@Component
@ConfigurationProperties(prefix = "hzx.jwt")
@Data
public class JwtProperties {
/**
* 管理端员工生成jwt令牌相关配置
*/
private String adminSecretKey;
private long adminTtl;
private String adminTokenName;
/**
* 用户端用户生成jwt令牌相关配置
*/
private String userSecretKey;
private long userTtl;
private String userTokenName;
}JWT工具类
@Component
public class JwtUtil {
@Autowired
private JwtProperties jwtProperties;
/**
* 生成jwt
* 使用Hs256算法, 私匙使用固定秘钥
* @param userId 用户id
* @return jwt令牌
*/
public String createJWT_user(Integer userId) {
// 指定签名的时候使用的签名算法,也就是header那部分
SignatureAlgorithm signatureAlgorithm = SignatureAlgorithm.HS256;
// 生成JWT的过期时间
long expMillis = System.currentTimeMillis() + jwtProperties.getUserTtl();
Date expData = new Date(expMillis);
//为用户生成jwt令牌
HashMap<String, Object> claims = new HashMap<>();
claims.put(JwtClaimsConstant.USER_ID, userId);
// 设置jwt的body
JwtBuilder builder = Jwts.builder()
// 设置签名使用的签名算法和签名使用的秘钥
.signWith(signatureAlgorithm, jwtProperties.getUserSecretKey().getBytes(StandardCharsets.UTF_8))
// 设置过期时间
.setExpiration(expData)
// 如果有私有声明,一定要先设置这个自己创建的私有的声明,这个是给builder的claim赋值,一旦写在标准的声明赋值之后,就是覆盖了那些标准的声明的
.setClaims(claims);
return builder.compact();
}
/**
* Token解密
* @param secretKey jwt秘钥 秘钥保留好在服务端, 不能暴露出去, 否则sign就可以被伪造, 如果对接多个客户端建议改造成多个
* @param token 加密后的token
* @return
*/
public Claims parseJWT(String secretKey, String token) {
// 得到DefaultJwtParser
Claims claims = Jwts.parser()
// 设置签名的秘钥
.setSigningKey(secretKey.getBytes(StandardCharsets.UTF_8))
// 设置需要解析的jwt
.parseClaimsJws(token)
.getBody();
return claims;
}
}自定义拦截器
管理员端
@Component
@Slf4j
@Order(1)
public class JwtTokenAdminInterceptor implements HandlerInterceptor {
@Autowired
private JwtProperties jwtProperties;
@Autowired
private JwtUtil jwtUtil;
/**
* 校验jwt
* @param request
* @param response
* @param handler
* @return
* @throws Exception
*/
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) {
System.out.println("1当前线程的id:" + Thread.currentThread().getId());
//判断当前拦截到的是Controller的方法还是其他资源
if (!(handler instanceof HandlerMethod)) {
//当前拦截到的不是动态方法,直接放行
return true;
}
//1、从请求头中获取令牌
String token = request.getHeader(jwtProperties.getAdminTokenName());
log.info("当前线程的id:{},jwt校验:{}", Thread.currentThread().getId(), token);
//2、校验令牌
if (token != null) {
try {
//解密jwt令牌,获得claims里的数据
Claims claims = jwtUtil.parseJWT(jwtProperties.getAdminSecretKey(), token);
Long adminId = Long.valueOf(claims.get(JwtClaimsConstant.ADMIN_ID).toString());
//将操作当前线程的用户id存入到请求域中
BaseContext.setCurrentId(adminId);
log.info("当前管理员id:{},jwt校验:{}", adminId, token);
//3、通过,放行
return true;
} catch (Exception ex) {
//4、不通过,响应401状态码
response.setStatus(401);
return false;
}
}else{
//5、令牌为空,响应401状态码
response.setStatus(401);
return false;
}
}
}用户端
@Component
@Slf4j
public class JwtTokenUserInterceptor implements HandlerInterceptor {
@Autowired
private JwtProperties jwtProperties;
@Autowired
private JwtUtil jwtUtil;
/**
* 校验jwt
* @param request
* @param response
* @param handler
* @return
* @throws Exception
*/
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
//判断当前拦截到的是Controller的方法还是其他资源
if (!(handler instanceof HandlerMethod)) {
//当前拦截到的不是动态方法,直接放行
return true;
}
//1、从请求头中获取令牌
String token = request.getHeader(jwtProperties.getUserTokenName());
log.info("当前线程的id:{},jwt校验:{}", Thread.currentThread().getId(), token);
//2、校验令牌
if (token != null) {
try {
//解密jwt令牌,获得claims里的数据
Claims claims = jwtUtil.parseJWT(jwtProperties.getUserSecretKey(), token);
Long userId = Long.valueOf(claims.get(JwtClaimsConstant.USER_ID).toString());
//将操作当前线程的用户id存入到请求域中
BaseContext.setCurrentId(userId);
log.info("当前用户id:{},jwt校验:{}", userId, token);
//3、通过,放行
return true;
} catch (Exception ex) {
//4、不通过,响应401状态码
response.setStatus(401);
return false;
}
}else{
//5、令牌为空,响应401状态码
response.setStatus(401);
return false;
}
}
}注册拦截器
@Configuration
@Slf4j
public class WebMvcConfiguration extends WebMvcConfigurationSupport {
@Autowired
private JwtTokenAdminInterceptor jwtTokenAdminInterceptor;
@Autowired
private JwtTokenUserInterceptor jwtTokenUserInterceptor;
/**
* 注册自定义拦截器
* @param registry
*/
protected void addInterceptors(InterceptorRegistry registry) {
log.info("开始注册自定义拦截器...");
registry.addInterceptor(jwtTokenAdminInterceptor)
.addPathPatterns("/admin/**")
.excludePathPatterns("/admin/employee/login");
registry.addInterceptor(jwtTokenUserInterceptor)
.addPathPatterns("/hello/**")
.addPathPatterns("/user/**")
.excludePathPatterns("/user/login/**")
.excludePathPatterns("/user/auth/**");
}
...
}------------------消息队列------------------
AMQP协议
AMQP(Advanced Message Queuing Protocol)是一种开放的标准协议,用于消息传递中间件。它提供了一种标准化的方法来实现消息传递系统之间的互操作性。AMQP 协议最初由金融行业提出,目的是为了实现跨组织的消息传递,但现在已被广泛应用于多种场景。
特点
- 开放标准:AMQP 是一个公开的标准协议。
- 跨平台和语言:AMQP 设计为跨平台和跨语言的协议,支持多种编程语言和操作系统。
- 安全性:AMQP 支持安全的消息传递,包括认证、授权和加密。
- 可靠性:AMQP 支持消息确认机制,确保消息的可靠传输。
- 灵活性:AMQP 允许不同的消息传递模式,包括点对点(P2P)和发布/订阅(Pub/Sub)。
基本概念
AMQP 协议定义了几个基本的概念,这些概念构成了消息传递的基础:
- 连接(Connection):客户端与消息传递中间件之间的网络连接。
- 通道(Channel):在连接之上建立的虚拟连接。每个通道都是一个独立的会话,可以在一个连接中同时使用多个通道。
- 交换机(Exchange):用于接收来自生产者的消息,并根据绑定规则将消息路由到一个或多个队列。
- 队列(Queue):用于暂存消息,直到消费者准备好接收它们。
- 绑定(Binding):用于定义交换机和队列之间的关系,以及消息如何从交换机路由到队列。
AMQP消息模型
消息格式
AMQP 消息通常包含以下几个部分:
- 头部(Header):包含消息的元数据,如优先级、TTL 等。
- 属性(Properties):包含消息的属性,如消息的唯一标识符、内容类型、内容编码等。
- 体(Body):包含消息的实际内容。
消息传递流程
以下是 AMQP 消息传递的基本流程:
- 建立连接:客户端与消息传递中间件建立 TCP/IP 连接。
- 打开通道:客户端在连接上打开一个或多个通道。
- 声明交换机和队列:客户端声明交换机和队列,并定义它们之间的绑定关系。
- 发送消息:生产者通过交换机发送消息。
- 接收消息:消费者从队列中接收消息。
- 关闭通道和连接:完成消息传递后,关闭通道和连接。
消息传递模型
点对点(P2P)模型:
- 在这种模型中,消息发送到队列,消费者从队列中拉取消息。一旦消息被一个消费者消费,它就会从队列中移除。
- 这种模型适用于消息必须被处理一次且只处理一次的情况。
发布/订阅(Pub/Sub)模型:
- 在这种模型中,消息发送到一个主题,所有订阅该主题的消费者都会接收到消息。
- 这种模型适用于消息需要被多个消费者接收的情况。
推模式 vs 拉模式
推消息(Push)模式的优势与局限

消息队列主动将消息发送给消费者。
在推送模型中,数据流是由生产者主动向代理发送数据,随后代理根据预先设定的规则或策略,将数据推送给注册的消费者。这种模型的优点包括较低的延迟和实时性更强的数据传递。然而,推送模型也有明显的局限性。首先,它对网络带宽的要求较高,特别是在高并发场景下,大量的小数据包频繁传输会导致网络拥塞。其次,由于数据传输速率由代理控制,不同消费者之间的处理能力差异可能导致部分消费者无法及时处理接收到的数据,从而造成资源浪费或系统过载。特别是当消费者的处理速度低于生产者的生成速度时,消费者可能会遭受类似拒绝服务攻击的情况,即被过多的数据淹没而无法正常工作。
在消息队列的推送模式中,**代理(Broker)需要记录和维护每个消费者的消费进度,以便准确地将未消费的消息推送给相应的消费者。**这是因为推送模式下,代理负责控制消息的发送时间和数量,确保每个消费者都能接收到它们尚未处理的消息。这种方式对代理的管理和协调能力要求较高,尤其是在消费者数量众多且处理能力不一的情况下,容易导致系统复杂度增加和性能瓶颈。
优点:
- 实时性强:消息可以立即传递给消费者,减少延迟。
- 减少轮询:消费者无需频繁地检查是否有新消息到达,从而减少了网络负载和资源消耗。
缺点:
- 连接管理复杂:需要保持长连接,并且需要处理连接断开的情况。
- 处理失败:如果消费者未能及时处理消息,可能导致消息积压或丢失。
- 资源消耗:持续保持连接可能会占用较多的资源,尤其是在高并发环境下。
拉消息(Pull)模式的优势与局限
消费者主动从消息队列中获取消息。
相比之下,拉取模型则采取了一种更为保守和灵活的方式。在这种模型中,数据由生产者发送到代理,但消费者需要主动发起请求以获取数据。这样做的好处:消费者可以根据自身的处理能力和当前的工作负载情况,自主决定何时以及多少数据进行拉取。即使在消费速度下降的情况下,消费者也只会暂时落后,而不会像在推送模型中那样被压垮。此外,拉取模型还支持更有效的数据批处理。消费者可以一次性拉取大量数据,从而减少网络交互次数,提高传输效率,同时保持较低的延迟。

拉取模式下,消费者自己决定何时以及多少消息进行消费。消费者会主动向代理请求消息,代理只需提供消息存储和查询的功能即可。这种方式减少了代理的负担,使其不必追踪每个消费者的消费进度,同时也赋予了消费者更大的灵活性,可以根据自身处理能力和当前负载情况自主调整消费速率。这种方式简化了系统设计,提高了系统的可扩展性和鲁棒性。 然而,拉取模型并非没有挑战。最明显的问题是,如果代理中没有新的数据可供拉取,消费者可能会频繁地发起空查询,导致CPU利用率升高,形成所谓的“忙等(Bush-Waiting)”状态。为了解决这一问题,Kafka引l入了“长轮询”机制,允许消费者在发出拉取请求后,如果没有新的数据可拉取,该请求会在代理端等待一段时间,直到有新数据产生或达到预设的超时时间。这样既避免了频繁的空查询,又保证了数据的及时传递。
优点:
- 控制灵活性:消费者可以根据自己的处理能力和需求来决定何时拉取消息。
- 连接简单:通常只需要短连接,降低了服务器的压力。
- 容易重试:如果处理过程中出现问题,可以更容易地重新尝试获取消息。
缺点:
- 增加网络负载:频繁的轮询会导致额外的网络流量。
- 延迟增加:由于需要消费者主动请求,所以消息传递可能不如推模式实时。
Kafka的选择与实践
基于上述推拉模式的分析,Kafka选择了拉取模型作为其核心数据传输机制。这一选择不仅符合大多数消息系统的传统设计,还特别适合于需要处理大量异构消费者的应用场景。通过实现长轮询功能,**Kafka有效地平衡了数据传输的即时性和系统的稳定性,使得即使在网络条件不稳定或消费者处理能力有限的情况下,也能保持高效的数据交换。**此外,Kafka还通过优化数据批处理和调整拉取请求的参数,进一步提高了系统的整体性能。 Kafka的拉取模型更适合数据处理场景,因为它允许消费者根据自身处理能力自主控制数据拉取的频率和数量,有效避免了消费者过载和资源浪费。而在业务场景中,实时性和低延迟要求更高,推送模型能更好地满足这些需求。
推拉结合(Push-Pull)模式
推拉结合使用,可以结合两者的优点,提高消息传递的效率和可靠性。
例如,消息队列可以先推送给消费者,然后消费者再拉取这些消息以确认处理状态。
RabbitMQ名词解释
Exchange(交换器):
- 定义:交换器是RabbitMQ中的消息路由中心。它接收来自生产者的消息,并根据一定的规则将消息发送到一个或多个队列中。
- 类型:主要有四种类型:Direct(直接)、Fanout(广播)、Topic(主题)和System(系统)。
- Direct:根据路由键(routing key)匹配队列。
- Fanout:无路由键概念,将消息发送给所有绑定到该交换器的队列。
- Topic:根据通配符模式匹配路由键。
- System:较少使用,根据消息头属性进行路由。
Queue(队列):
- 定义:队列是消息的实际存储位置,是消息的最终目的地。
- 特性:可以设置持久化、独占、自动删除等属性。
Routing Key(路由键):
- 定义:生产者发送消息时使用的键,用于将消息路由到特定的队列。
- 用途:在Direct和Topic类型的交换器中,根据路由键来确定消息的去向。
Binding(绑定):
- 定义:队列与交换器之间的关联关系,决定了消息如何从交换器到达队列。
- 用途:通过绑定关系,交换器可以将消息发送到一个或多个队列。
Message(消息):
- 定义:由生产者创建并发送给交换器的信息单元。
- 组成:通常包括消息体(body)和消息属性(properties),如消息的优先级、TTL等。
Virtual Host(虚拟主机):
- 定义:类似于隔离的RabbitMQ实例,可以实现不同的应用使用不同的虚拟主机。
- 用途:提供命名空间和安全隔离机制。
Connection(连接):
- 定义:客户端与RabbitMQ服务器建立的TCP连接。
- 用途:用于发送命令、接收响应等。
Channel(通道):
- 定义:建立在连接之上的轻量级逻辑连接,可以复用TCP连接。
延迟队列:
延迟队列:进入队列的消息会被延迟消费的队列。
应用场景:超时订单、限时优惠、定时发布
延迟队列 = 死信交换机 + TTL(生存时间)
死信队列
死信队列:当一个队列中的消息满足下列情况之一时,可以成为死信:
消费者使用
basic.reject或basic.nack声明消费失败,并且消息的 requeue 参数设置为 false消息过期了,超时无人消费
要投递的队列消息堆积满了,最早的消息可能成为死信
死信交换机
死信交换机:配置了dead-letter-exchange属性的队列所指定的交换机。
java@Bean public Queue ttlQueue(){ return QueueBuilder.durable("simple.queue") // 指定队列名称, 并持久化 .tt1(10000) // 设置队列的超时时间,10秒 .deadLetterExchange("dl.direct") // 指定死信交换机 .build(); }
Kafka名词解释
- Topic(主题):
- 定义:消息的分类容器,相当于RabbitMQ中的Exchange和Queue的组合体。
- 特性:每个主题可以有多个分区,用于支持并行处理。
- Partition(分区):
- 定义:主题下的子集,用于提高并行处理能力。
- 特性:每个分区都是有序且不可变的消息序列,可以跨多个Broker分布。
- Broker(代理):
- 定义:Kafka集群中的一个节点,负责存储和转发消息。
- 用途:处理客户端请求,如消息的发布和订阅。
- Producer(生产者):
- 定义:向Kafka主题发送消息的应用程序。
- 特性:可以指定消息的分区和键(Key)。
- Consumer(消费者):
- 定义:从Kafka主题中读取消息的应用程序。
- 特性:通常以组的形式存在,同一组内的消费者可以实现负载均衡。
- Consumer Group(消费者组):
- 定义:一组消费者,通常用于实现负载均衡。
- 特性:组内的消费者可以共享消息,一个分区在同一时刻只能被组内的一个消费者消费。
- Offset(偏移量):
- 定义:记录消费者在主题中的消费进度。
- 用途:用于恢复消费状态,确保消息不会被重复消费。
- Leader(领导者):
- 定义:负责处理客户端读写请求的Broker。
- 用途:确保数据的一致性和高可用性。
- Replica(副本):
- 定义:分区的备份,用于提高系统的可靠性和可用性。
- 用途:当Leader失效时,可以切换到其他Replica继续提供服务。
高可用设计
RabbitMQ 高可用设计
- 镜像队列(Mirrored Queues):
- 在RabbitMQ中,可以通过配置镜像队列来提高系统的可用性和可靠性。当一个队列被配置为镜像队列后,该队列中的所有消息不仅会存储在主节点上,还会复制到指定数量的从节点上。这样即使主节点发生故障,从节点也可以接管消息处理工作,保证服务的连续性。
- 高效ACK机制:
- RabbitMQ支持消息确认机制,即消费者处理完一条消息后向RabbitMQ发送ACK确认信号,只有收到ACK后,RabbitMQ才会将该消息从队列中删除。这种机制可以有效避免因消费者故障导致的消息丢失问题。同时,为了提高性能,RabbitMQ还支持批量确认和预取计数等优化手段。
- 集群模式:
- 通过构建RabbitMQ集群,可以进一步增强系统的高可用性和伸缩性。集群中的每个节点都可以接收客户端连接,并且队列可以在多个节点之间分布,以实现负载均衡。
Kafka 高可用设计
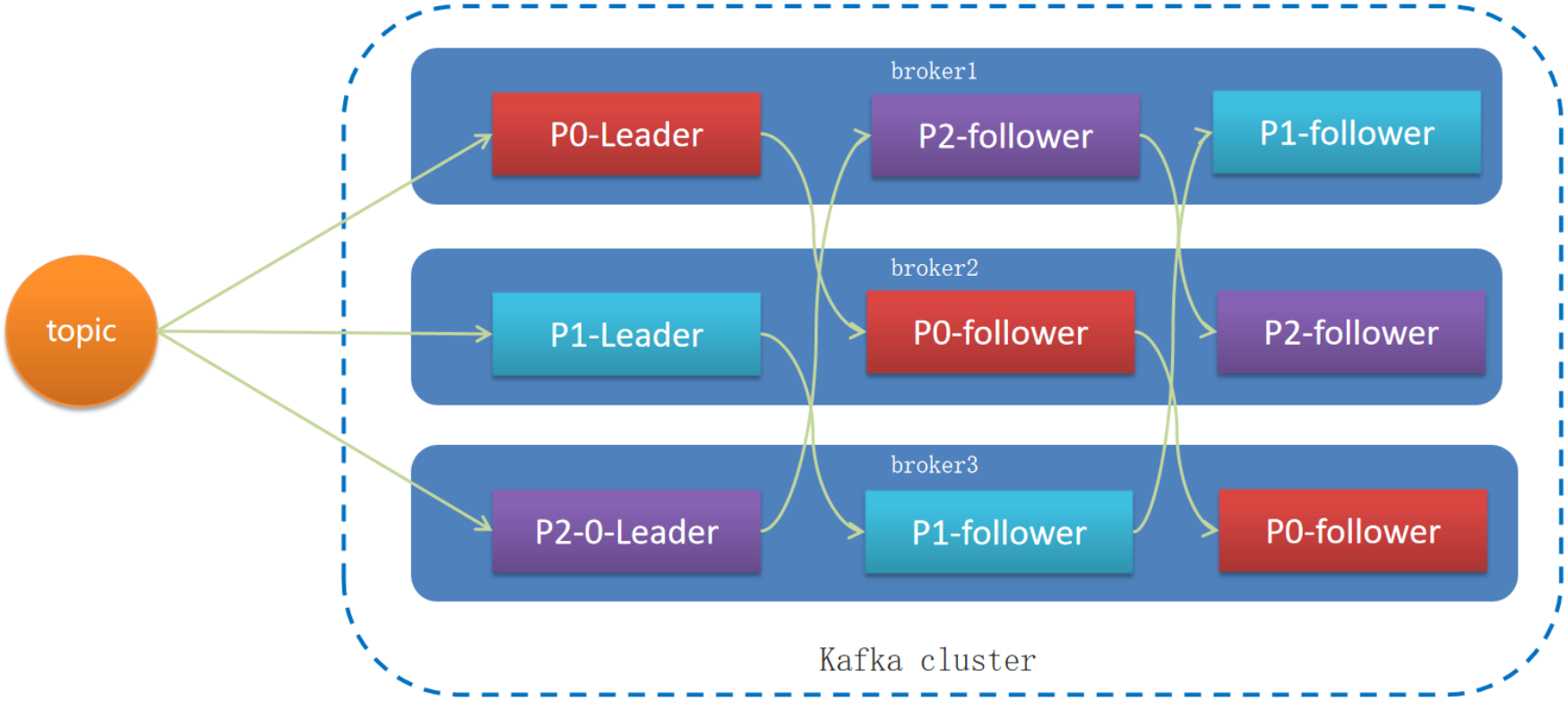
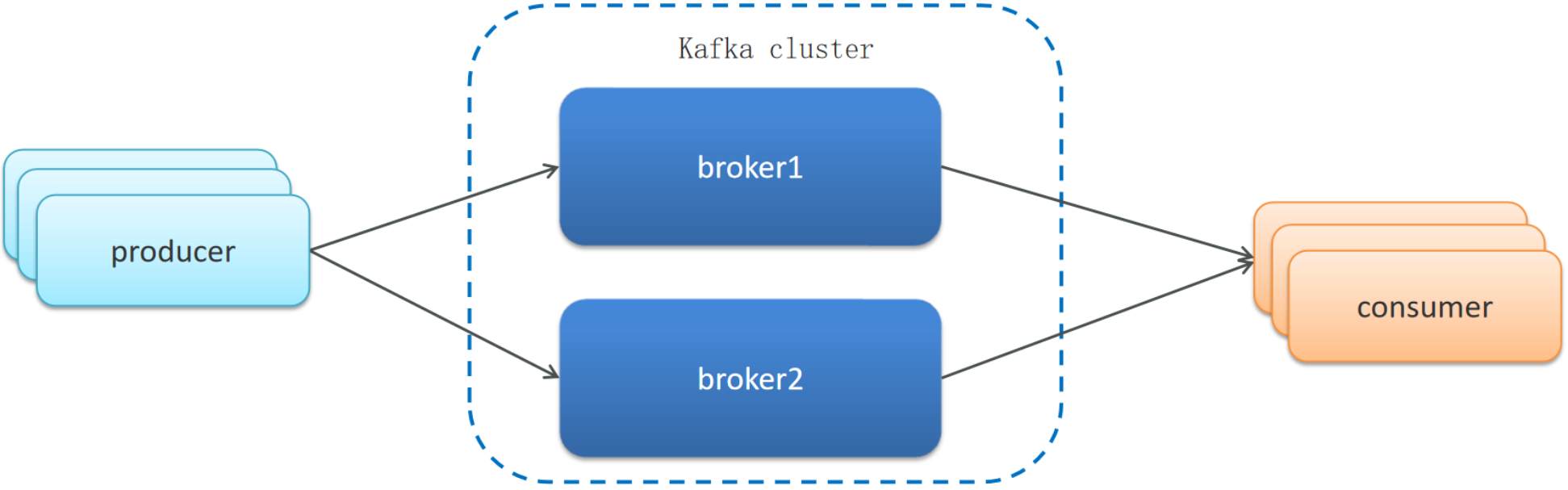
Leader-Follower机制(分区备份机制):
Kafka中每个分区都有一个Leader副本和多个Follower副本。生产者发送的消息首先会被写入Leader副本,然后同步到所有的Follower副本。消费者只从Leader副本读取消息。如果Leader副本失效,Kafka会自动从现有的Follower副本中选举一个新的Leader。
一个topic有多个分区,每个分区有多个副本,其中有一个leader,其余的是follower,副本存储在不同的broker中
所有的分区副本的内容是都是相同的,如果leader发生故障时,会自动将其中一个follower提升为leader
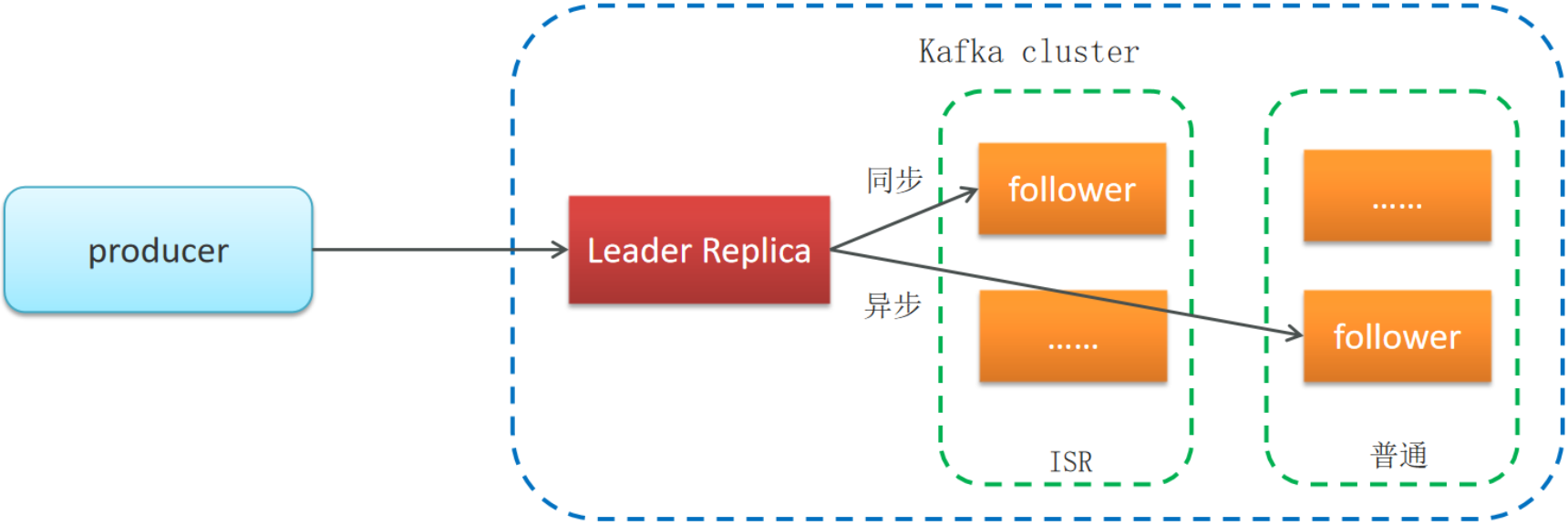
ISR(In-Sync Replicas)同步机制(分区副本复制机制):
ISR是指与Leader副本保持同步的所有副本集合。当Follower副本与Leader副本之间的延迟超过一定阈值时,该Follower副本将从ISR中移除。只有ISR中的副本才有资格被选为新的Leader,这确保了副本间的数据一致性。
ISR(in-sync replica)分区是Leader分区同步复制保存的一个队列,普通分区是Leader分区异步复制保存的一个队列。
如果leader失效后,需要选出新的leader,选举的原则如下:
- 第一:选举时优先从ISR中选定,因为这个列表中follower的数据是与leader同步的
- 第二:如果ISR列表中的follower都不行了,就只能从其他follower中选取
多副本策略:
Kafka允许为每个分区配置多个副本,这些副本分布在不同的Broker上。这样即使某个Broker出现故障,也不会影响整个集群的服务能力。此外,合理的副本分配策略还可以提高数据的安全性和系统的容错性。
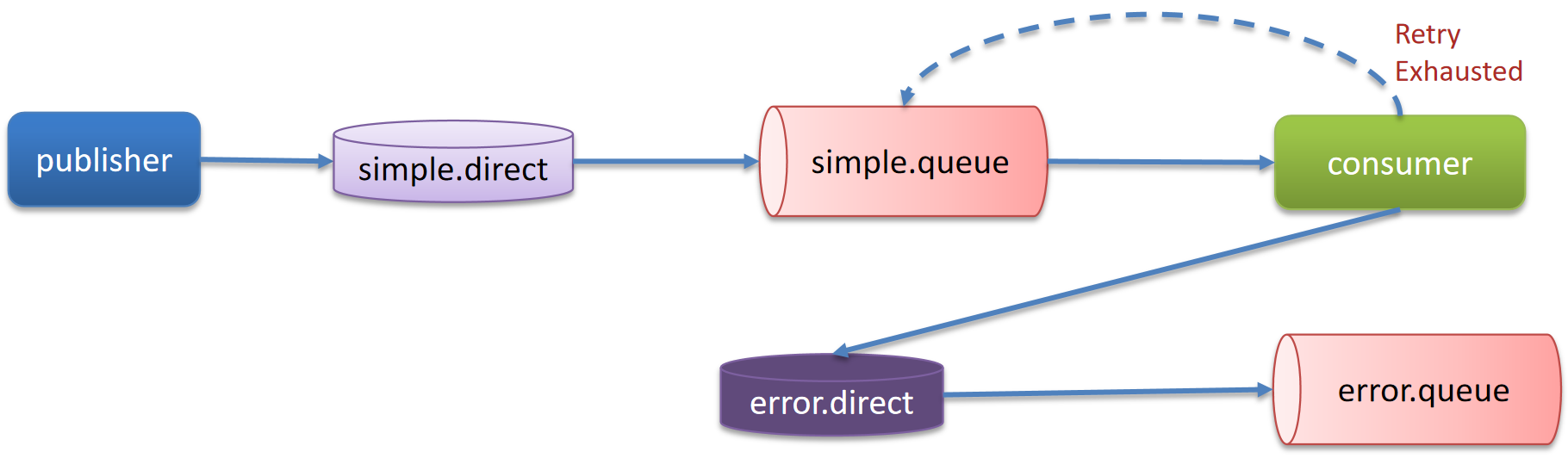
保证消息不丢失
RabbitMQ
消息持久化:RabbitMQ的消息默认是存储在内存,开启持久化功能将消息缓存在磁盘,可以确保消息不丢失,但会受IO性能影响。
- 交换机持久化

- 队列持久化

- 消息持久化,SpringAMQP中的的消息默认是持久的,可以通过MessageProperties中的DeliveryMode来指定的:

消费确认机制:消费者处理消息后可以向RabbitMQ发送ack回执,RabbitMQ收到ack回执后才会删除该消息。
SpringAMQP则允许配置三种确认模式:
manual:手动ack,需要在业务代码结束后,调用api发送ack。
auto:自动ack,由spring监测listener代码是否出现异常,没有异常则返回ack;抛出异常则返回nack
none:关闭ack,MQ假定消费者获取消息后会成功处理,因此消息投递后立即被删除
失败重试机制:在消费者出现异常时利用本地重试,设置重试次数,当次数达到了以后,如果消息依然失败,将消息投递到异常交换机,交由人工处理。
Kafka
从三个方面考虑消息丢失:
生产者发送消息到Brocker丢失:
- 设置异步发送,发送失败使用回调进行记录或重发

- 失败重试,参数配置,可以设置重试次数

消息在Brocker中存储丢失:
- 发送确认acks,选择all,让所有的副本都参与保存数据后确认
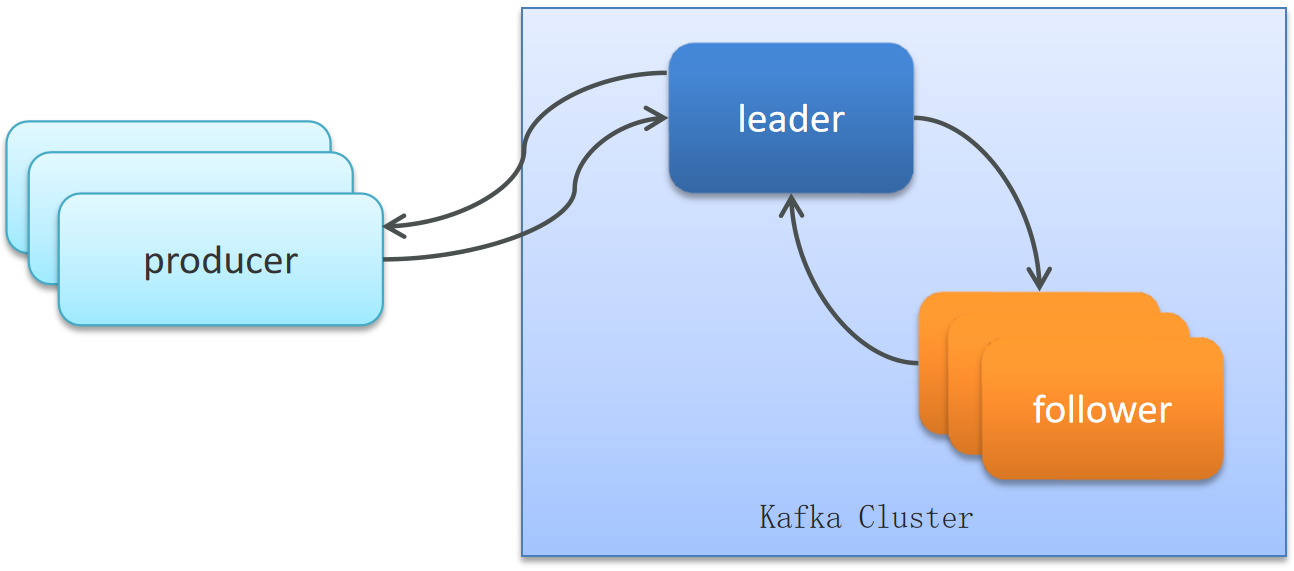
确认机制 说明 acks=0 生产者在成功写入消息之前不会等待任何来自服务器的响应,消息有丢失的风险,但是速度最快 acks=1(默认值) 只要集群主节点收到消息,生产者就会收到一个来自服务器的成功响应 acks=all 只有当所有参与赋值的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应 消费者从Brocker接收消息丢失(重平衡):
- 禁用自动提交偏移量,改为手动提交偏移量
- 提交方式,最好是异步(优先)+同步提交
避免重复消费
这依赖于外部设计,MQ和Kafka不做防范
RabbitMQ:
- 每条消息设置一个唯一的标识id:eg.在处理支付业务时,可以先拿着业务的唯一标识到数据库查询一下,如果这个数据不存在,说明没有处理过,这个时候就可以正常处理这个消息了。如果已经存在这个数据了,就说明消息重复消费了,我们就不需要再消费了。
- 幂等方案:redis分布式锁、数据库锁(悲观锁、乐观锁)
Kafka:
禁用自动提交偏移量,改为手动提交偏移量
提交方式,异步提交 + 同步提交
幂等方案:redis分布式锁、数据库锁(悲观锁、乐观锁)
解决消息堆积问题
增加更多消费者,提高消费速度
在消费者内开启线程池加快消息处理速度
扩大队列容积,提高堆积上限,采用惰性队列
- 在声明队列的时候可以设置属性
x-queue-mode为lazy,即为惰性队列 - 惰性队列基于磁盘存储,消息上限高
- 惰性队列性能比较稳定,但基于磁盘存储,受限于磁盘IO,时效性会降低
- RabbitMQ代码实现:

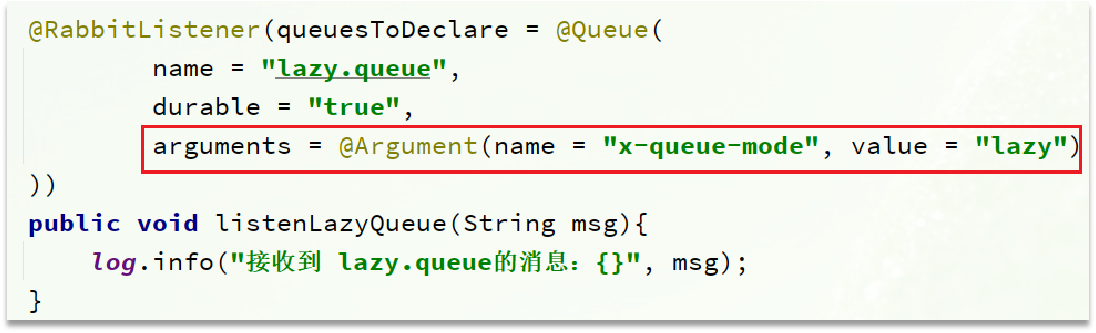
- 在声明队列的时候可以设置属性
保证消费的有序性
RabbitMQ:
- 单个消费者
最简单也是最直接的方法是使用单个消费者来消费队列中的消息。这样可以保证消息按照入队顺序被消费,因为不会有其他消费者干扰这一过程。
// 创建一个队列
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
// 设置预取计数为1,确保公平调度
channel.basicQos(1);
// 消费者回调函数
DeliverCallback deliverCallback = (consumerTag, delivery) -> {
String message = new String(delivery.getBody(), StandardCharsets.UTF_8);
System.out.println("Received message: '" + message + "'");
channel.basicAck(delivery.getEnvelope().getDeliveryTag(), false);
};
// 开始消费
channel.basicConsume(QUEUE_NAME, false, deliverCallback, consumerTag -> {});- 公平调度(Fair Dispatch)
即使在使用单个消费者的情况下,也可以通过设置 basicQos 来限制消费者在同一时间处理的消息数量,从而避免因处理速度差异而导致的顺序错乱。
// 设置预取计数为1
channel.basicQos(1);Kafka:
消息消费无序的原因:
一个topic的数据可能存储在不同的分区中,每个分区都有一个按照顺序的存储的偏移量,如果消费者关联了多个分区不能保证顺序。
topic分区中消息只能由消费者组中的唯一消费者处理,想要顺序的处理Topic的所有消息,那就为消息者只提供一个分区或将相同的业务设置相同的key。
解决方案:
发送消息时指定同一个topic的分区号
发送消息时按照相同的业务设置相同的key(分区默认通过key的hashcode值来选择分区,hash值一致,分区也一致)
代码实现:

RabbitMQ:死信消息
- 消息没有匹配的队列:如果消息发送到一个没有队列绑定的交换机,或者没有匹配的绑定键,那么消息将被丢弃或发送到死信队列。
- 消息被拒绝:如果消费者拒绝了消息,并且设置了
requeue=false,那么消息将被发送到死信队列。 - 消息过期:如果队列设置了过期时间(
x-message-ttl),消息在过期后将被发送到死信队列。
Kafka:消息的存储和清理
Kafka文件存储机制:
topic的数据存储在分区上,分区如果文件过大会分段(segment)存储。每个分段都在磁盘上以索引
xxxx.index和**日志文件xxxx.log**的形式存储,减少单个文件内容的大小,查找数据方便,方便kafka进行日志清理数据清理机制
- 根据消息的保留时间:当消息保存的时间超过了指定的时间,就会触发清理,默认是168小时( 7天)
- 根据topic存储的数据大小:当topic所占的日志文件大小大于一定的阈值,则开始删除最久的消息。(默认关闭)
Kafka:消息索引的设计
Kafka 的索引设计旨在优化消息查找的速度,同时保持磁盘空间的有效利用。
索引文件结构:Kafka 的索引文件与数据文件紧密相关。每个分区都有若干个段(segment),每个段对应一个 xxxx.log 文件和一个 xxxx.index 文件。以下是索引文件的一些关键特点:
- 索引文件与数据文件关联:每个数据文件都有对应的索引文件,索引文件记录了数据文件中消息的偏移量位置。
- 固定间隔索引:索引文件中记录的不是每一个消息的位置,而是每隔一定数量的消息记录一个索引项。这样可以显著减少索引文件的大小,同时仍然保持较快的查找速度。
索引文件格式:Kafka 的索引文件格式是高效的,主要包括以下几个方面:
- 压缩索引:索引文件通常比数据文件小得多,这有助于节省存储空间。
- 稀疏索引:索引文件记录的是每隔一定数量的消息的位置信息,而不是每个消息的位置信息。这使得索引文件更加紧凑。
- 二进制格式:索引文件是以二进制格式存储的,便于快速读取和解析。
索引更新机制:Kafka 的索引文件在写入新消息时会自动更新,以保持索引的最新状态:
- 动态更新:每当新消息被追加到数据文件时,索引文件也会相应更新,以反映最新的消息位置。
- 预分配空间:Kafka 会预先分配索引文件的空间,以避免频繁的文件扩展操作。
性能优势:Kafka 的索引设计带来了以下性能优势:
- 快速定位:通过索引文件,Kafka 可以迅速定位到消息的位置,从而加快消息的检索速度。
- 高效的存储:索引文件占用的空间相对较小,有助于节省存储资源。
- 可扩展性:索引设计使得 Kafka 能够在高并发环境下保持良好的性能表现。
Kafka:高性能设计
消息分区:不受单台服务器的限制,可以不受限的处理更多的数据
顺序读写:磁盘顺序读写,提升读写效率
页缓存:把磁盘中的数据缓存到内存中,把对磁盘的访问变为对内存的访问
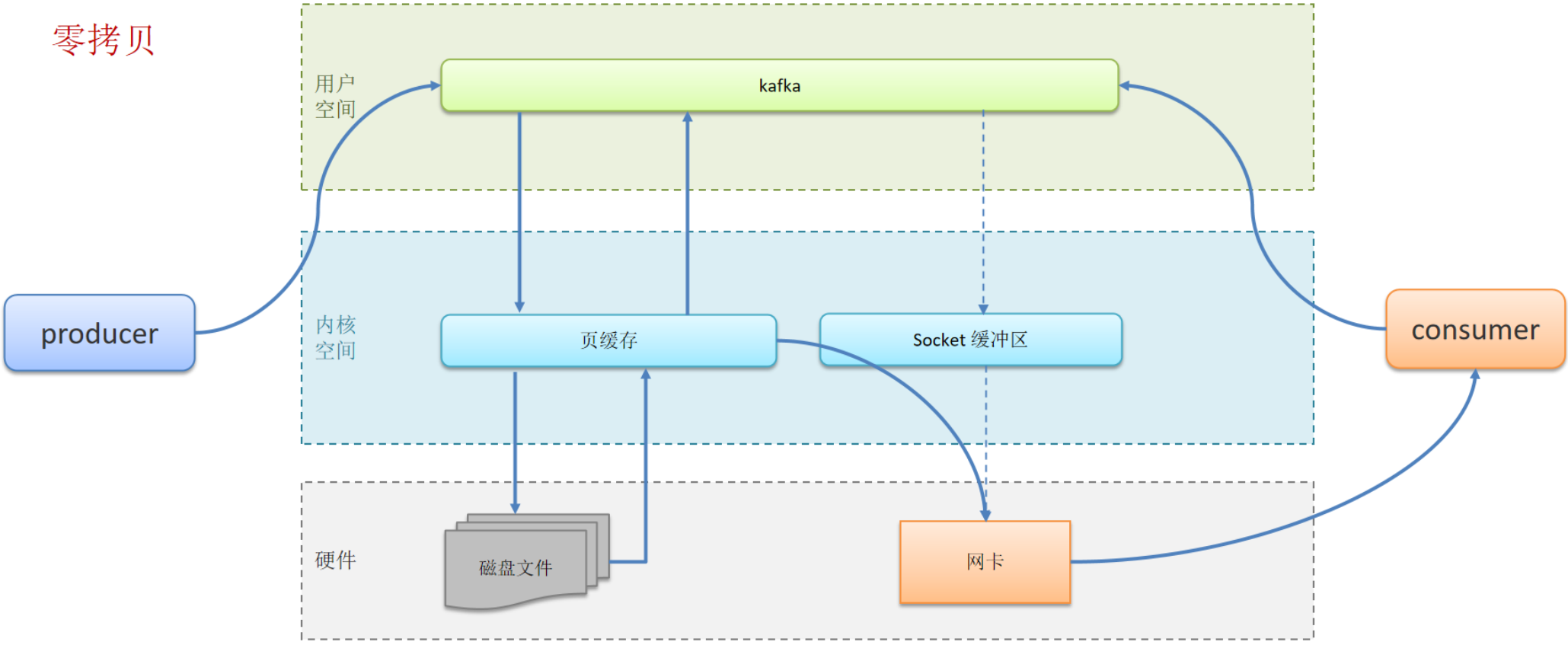
零拷贝:减少上下文切换及数据拷贝
消息压缩:减少磁盘IO和网络IO
分批发送:将消息打包批量发送,减少网络开销
Kafka:处理请求的全流程?
Kafka 处理请求的全流程是一个复杂的多步骤过程,涉及到网络通信、请求解析、元数据管理、消息存储等多个方面。下面详细介绍 Kafka 处理请求的具体流程:
1. 网络层接收请求
当客户端(如生产者或消费者)向 Kafka 发送请求时,请求首先到达 Kafka Broker 的网络层。
- Netty Server:Kafka 使用 Netty 框架来处理网络请求。Netty 是一个高性能、异步事件驱动的网络应用框架,它负责接收客户端的请求并将请求分发给相应的处理器。
- ChannelHandler:Netty 的 ChannelHandler 负责处理每个连接上的读写操作。当请求到达时,Netty 会调用 ChannelHandler 的
read方法来处理请求。
2. 请求解析与分发
请求到达后,Kafka 会对请求进行解析,并根据请求类型将其分发到相应的处理器。
- RequestHeader 解析:Kafka 会首先解析请求头(RequestHeader),从中提取请求的 API 类型和版本号。
- API 请求分发:根据请求头中的信息,Kafka 会将请求分发到相应的 API 层处理器,如
ProduceRequestHandler、FetchRequestHandler等。
3. 元数据校验
在处理请求之前,Kafka 会对请求中涉及的元数据进行校验。
- Topic 存在性检查:Kafka 会检查请求中的 Topic 是否存在。
- 权限校验:Kafka 会对请求进行权限校验,确保客户端有权执行所请求的操作。
4. 数据处理
一旦请求通过了元数据校验,Kafka 会根据请求类型进行相应的数据处理。
对于生产者请求(ProduceRequest)
- 消息写入:生产者请求包含要写入的消息。Kafka 会将消息写入到对应的分区中。
- 日志追加:消息被追加到分区的日志文件中。Kafka 使用追加操作来高效地写入数据。
- 同步到副本:Leader Broker 会将消息同步到副本 Broker,确保数据的一致性和持久性。
- 提交偏移量:一旦消息被成功写入并同步到副本,Leader Broker 会提交偏移量,并返回成功响应给生产者。
对于消费者请求(FetchRequest)
- 消息读取:消费者请求包含要读取的消息的偏移量。Kafka 会根据偏移量从分区中读取消息。
- 消息检索:Kafka 使用索引文件快速定位消息,并将消息读取到内存中。
- 返回消息:将检索到的消息返回给消费者。
5. 响应构建与发送
处理完请求后,Kafka 会构建响应,并通过网络层将响应发送回客户端。
- ResponseHeader 构建:构建响应头,包含响应的状态码等信息。
- 响应序列化:将响应数据序列化为字节数组。
- 响应发送:通过 Netty 的 ChannelHandler 将响应数据发送回客户端。
6. 异常处理
在整个请求处理过程中,Kafka 会捕获并处理可能出现的各种异常情况。
- 重试机制:对于可重试的错误(如网络中断),Kafka 会尝试重新处理请求。
- 错误记录:对于无法处理的错误,Kafka 会记录错误信息,并返回相应的错误码给客户端。
Kafka:Zookeeper 的作用
在 Kafka 的早期版本中,ZooKeeper 是一个不可或缺的组件,它在 Kafka 集群中起到了协调服务的作用。然而,从 Kafka 0.10 版本开始,Kafka 引入了内置的选举机制,减少了对 ZooKeeper 的依赖。尽管如此,ZooKeeper 仍然在 Kafka 中扮演着重要角色,特别是在老版本的 Kafka 中。
ZooKeeper 在 Kafka 中的主要作用
- 元数据管理:
- Broker 注册:在 Kafka 中,Broker 会向 ZooKeeper 注册自己,并维持一个心跳连接。ZooKeeper 用来存储 Broker 的信息,包括其 IP 地址和端口号。
- Topic 元数据:ZooKeeper 存储了所有 Topic 的元数据信息,包括分区(Partition)的数量、Leader Broker 的信息以及副本(Replica)的位置。
- 协调服务:
- Leader 选举:在 Kafka 的早期版本中,当一个分区的 Leader Broker 失效时,ZooKeeper 负责协调新的 Leader 选举过程。从 Kafka 0.10 版本开始,这一过程由 Kafka 自身的选举机制处理。
- Consumer Group 协调:ZooKeeper 负责协调 Consumer Group 的成员关系,包括分配分区给消费者以及处理消费者失效等情况。
- 故障恢复:
- Broker 失效检测:ZooKeeper 监控 Broker 的心跳,如果某个 Broker 长时间没有发送心跳,则认为该 Broker 已经失效,并触发相应的故障恢复机制。
- 分区重新分配:在 Broker 失效或新增 Broker 时,ZooKeeper 可以协助重新分配分区,确保集群的负载均衡。
Kafka 0.10+ 版本的变化
从 Kafka 0.10 版本开始,引入了一些改进来减少对 ZooKeeper 的依赖:
- 内置选举机制:Kafka 引入了内置的选举机制来处理 Leader 选举,减少了对 ZooKeeper 的依赖。
- 简化元数据存储:尽管 Kafka 依然使用 ZooKeeper 来存储一些元数据,但许多元数据已经被移到了 Kafka 自身的存储中。
当前版本(2024 年左右)的趋势
在当前版本中,Kafka 对 ZooKeeper 的依赖已经大大减少,但仍有一些场景下需要 ZooKeeper 的支持:
- Consumer Group 状态管理:虽然 Kafka 可以不依赖 ZooKeeper 来运行,但在 Consumer Group 状态管理方面,ZooKeeper 仍然提供了一种可靠的协调机制。
- 遗留系统兼容性:对于已经在生产环境中运行的老版本 Kafka 集群,ZooKeeper 仍然是必不可少的组件。
Kafka:为什么要摆脱 Zookeeper?
Kafka并没有完全抛弃ZooKeeper,而是在逐渐减少对 ZooKeeper 的依赖。
性能和延迟
- 减少延迟:ZooKeeper 作为集中式协调服务,每次需要进行元数据操作时都需要与 ZooKeeper 交互,这增加了系统的延迟。减少对 ZooKeeper 的依赖可以降低延迟,提高系统的整体性能。
- 提高吞吐量:通过减少对 ZooKeeper 的依赖,Kafka 可以更有效地处理大量的元数据操作,从而提高系统的吞吐量。
可靠性和可用性
- 单点故障:虽然 ZooKeeper 本身是一个分布式的协调服务,但如果 ZooKeeper 集群出现问题,整个 Kafka 集群可能会受到影响。减少对 ZooKeeper 的依赖可以降低单点故障的风险。
- 高可用性:通过内置的选举机制和其他协调功能,Kafka 可以实现更高的可用性,即使没有 ZooKeeper 的支持也能正常运行。
扩展性和管理
- 简化集群管理:减少对 ZooKeeper 的依赖意味着减少了集群管理的复杂性。管理员不需要同时管理 Kafka 和 ZooKeeper 两个独立的服务,降低了运维负担。
- 更好的水平扩展:Kafka 通过内置机制实现水平扩展,可以更好地适应大规模部署的需求,而不需要依赖外部服务来协调扩展。
内置功能增强
- 内置选举机制:Kafka 0.10 版本引入了内置的选举机制,可以更快速地进行 Leader 选举,而不需要通过 ZooKeeper 来协调。
- 元数据存储:Kafka 将更多元数据存储在本地的日志文件中,减少了对外部协调服务的依赖。
社区和生态发展
- 社区推动:Kafka 社区一直在努力改进 Kafka 的核心功能,减少对外部组件的依赖是其中的一个重要方向。
- 生态系统兼容性:随着 Kubernetes 和容器化技术的发展,简化部署和管理流程变得越来越重要。减少对 ZooKeeper 的依赖使得 Kafka 更容易与其他生态系统集成。
实际应用场景
在实际应用中,虽然 Kafka 逐渐减少了对 ZooKeeper 的依赖,但在某些场景下,ZooKeeper 仍然具有重要作用。例如,在 Consumer Group 的协调方面,ZooKeeper 仍然提供了一种可靠的协调机制。此外,在一些遗留系统中,ZooKeeper 依然是必要的组件。
--------------------Netty--------------------
网络通信的过程
服务端是怎么接收客户端的消息的?服务端是如何感知到数据的?
服务器使用非阻塞I/O(NIO)来接收客户端的消息。具体过程如下:
- 接收连接: 服务器通过
ServerSocketChannel监听特定端口,并接受来自客户端的连接请求,创建SocketChannel。 - 读取数据: 服务器在处理客户端连接时,会调用
SocketChannel.read()方法读取客户端发送的数据。此方法会将数据填充到一个ByteBuffer中。 - 感知数据到达: 服务器在循环中持续读取数据,直到没有更多数据可读。如果
read()方法返回的字节数大于0,说明有数据到达。 - 解析数据: 服务器在读取数据后,将数据进行解码。
- 循环处理: 服务器会继续循环,等待并处理后续消息,直到客户端关闭连接。
这种方式使得服务器能够有效地处理多个客户端的连接和消息,同时能够感知数据的到达。
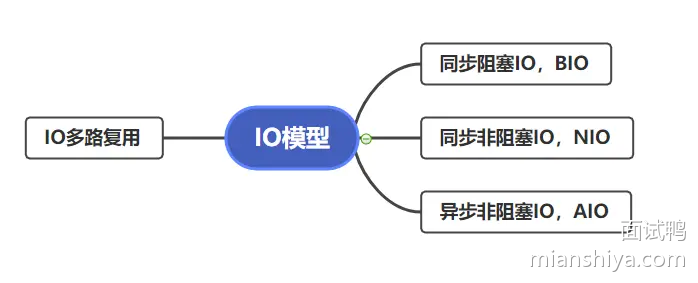
常见的I/O 模型
- 阻塞I/O(Blocking I/O):每个I/O操作都需要等待,效率较低。
- 非阻塞I/O(Non-blocking I/O):调用I/O操作后立即返回,可以通过轮询来检查操作是否完成。
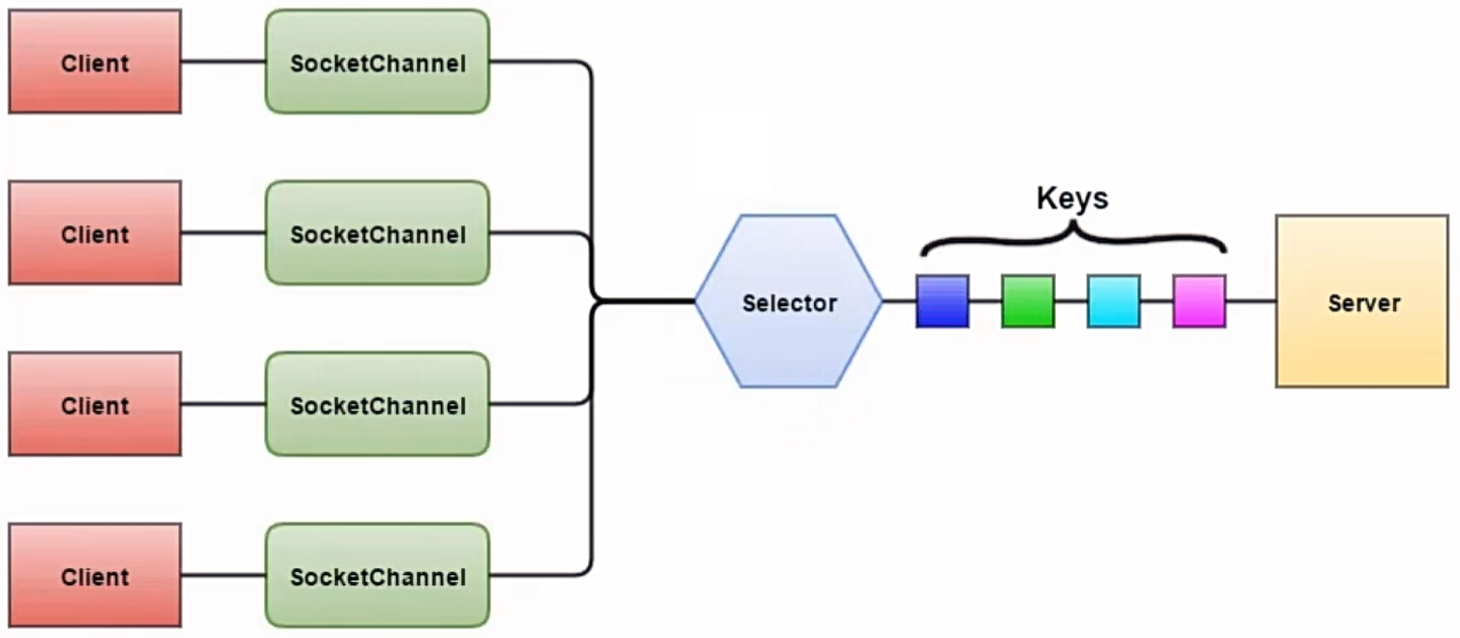
- 多路复用(Multiplexing I/O):使用
select、poll、epoll等机制,同时监视多个I/O操作,适合高并发场景。 - 异步I/O(Asynchronous I/O):操作完成时会通知应用程序,避免了轮询。
NIO产生的背景
对于每一个新的网络连接都分配给一个线程。每个线程都独自处理自己负责的socket连接的输入和输出。当然,服务器的监听线程也是独立的,任何socket连接的输入和输出处理都不会阻塞到后面新socket连接的监听和建立,这样服务器的吞吐量就得到了提升。早期版本的Tomcat服务器就是这样实现的。
- ConnectionPerThread模式(一个线程处理一个连接)的优点是解决了前面的新连接被严重阻塞的问题,在一定程度上较大地提高了服务器的吞吐量。
- ConnectionPer Thread模式的缺点是对应于大量的连接,需要耗费大量的线程资源,对线程资源要求太高。在系统中,线程是比较昂贵的系统资源。如果线程的数量太多,系统将无法承受。而且,线程的反复创建、销毁、切换也需要代价。
**JavaNlo(非阻塞IO)其工作原理是通过使用通道(Channels)和缓冲区(Buffers)**来实现数据的传输。与传统的面向流的I/O不同,NIO采用事件驱动的模型,允许单个线程监听多个通道上的事件,通过选择器(Selectors)来处理多个网络连接,从而实现高效率的数据读写操作,特别适用于高并发网络应用场景。
NIO和BIO的区别
NIO(New IO)和BIO(Blocking IO)是Java编程语言中用于处理输入输出(IO)操作的两种不同机制,它们之间存在一些显著的区别。
工作原理:
BIO:这是一种同步阻塞式IO。服务器实现模式为“一个连接一个线程”,即当客户端发送请求时,服务器端需要启动一个线程进行处理。如果连接不进行任何操作,会造成不必要的线程开销。虽然可以通过线程池机制改善这个问题,但在高并发环境下,BIO的性能可能会受到影响,因为每个连接都需要创建一个线程,而且线程切换开销较大。
NIO:这是一种同步非阻塞式IO。服务器实现模式为“一个请求一个线程”,即**客户端发送的连接请求都会注册到多路复用器(采用事件驱动思想实现)上,多路复用器轮询I/O请求时才启动一个线程进行处理。**NIO在处理IO操作时,会把资源先操作至内存缓冲区,然后询问是否IO操作就绪。如果就绪,则进行IO操作;否则,进行下一步操作,并不断轮询是否IO操作就绪。
资源利用:
- BIO:由于每个连接都需要创建一个线程,因此在高并发环境下可能会导致大量线程的创建和管理,这会增加系统开销。
- NIO:通过**单线程处理多个通道(Channel)**的方式,减少了线程的数量,从而降低了系统开销。此外,NIO使用缓冲区(Buffer)进行数据的读写,提高了IO的处理效率。
应用场景:
BIO:适合一些简单的、低频的、短连接的通信场景,例如HTTP请求。
NIO:适用于高并发、长连接、大量数据读写的场景,如文件传输、分布式计算等。
讲讲Java NIO
- 背景与目的
- NIO是为了弥补传统同步阻塞IO模型中的不足而设计的。它提供了更快的、基于块的数据处理方式。
- 核心概念
- Buffer(缓冲区):Buffer是NIO的核心组件之一,它是一个可以直接访问的数组,用于存储不同数据类型的数据。所有数据都会先经过Buffer来处理,无论是读取还是写入。
- Channel(通道):Channel是另一个关键组件,它允许数据从一个地方传输到另一个地方。与传统的流(Stream)不同,Channel是双向的,支持同时进行读写操作。
- Selector(选择器/多路复用器):Selector负责监听一个或多个Channel,并通知应用程序有关Channel的状态变化,如是否准备好进行读或写操作等。
- 工作流程
- 当应用程序需要读取数据时,数据首先被读取到Buffer中。
- 写入数据时,数据是从Buffer写入到Channel。
- Selector用于监控多个Channel的状态,并且当Channel准备好了相应的操作时,Selector会通知应用程序。
- 通过Selector返回的SelectionKey,可以获取就绪状态的Channel,并执行相应的IO操作。
- 优势
- NIO相比传统的IO模型更加高效,因为它允许单个线程管理多个Channel连接,从而提高了并发处理能力。
*讲讲Netty,它解决了什么问题?
- Netty是一个高性能、异步的事件驱动的网络应用框架,主要用于构建快速、可扩展的网络服务器和客户端。它简化了网络编程的复杂性,如处理TCP连接、数据传输、协议解析等,使开发者能够更专注于业务逻辑。
- Netty是一个高性能、异步事件驱动的网络应用程序框架,用于快速开发可靠的协议服务器和客户端。它基于Java NIO(非阻塞IO),提供了丰富的API来简化网络编程的复杂性。Netty可以用于开发多种协议的服务端和客户端,如HTTP、WebSocket、SMTP等,也可以用来开发自定义的二进制协议。
- Netty是一个基于NIO模型的高性能网络通信框架,它是对NIO网络通信的封装,我们可以利用这样一些封装好的api去快速开发一个网络程序。
- Netty在NIO的基础上做了很多优化,比如零拷贝机制、高性能无锁队列、内存池,因此性能比NIO更高。
- Netty可以支持多种的通信协议,例如:Http、WebSocket等,并且针对一些通信问题,Netty也内置了一些策略,例如拆包、粘包,所以在使用过程中会比较方便。
Netty 的应用场景
- 高性能网络服务器(如游戏服务器、即时通讯工具)
- 微服务架构中的服务通信
- WebSocket服务器
- 数据传输层(如RPC框架)
*为什么要使用Netty?Netty的特点
Netty相比与直接使用JDK自带的api更简单,因为它具有这样一些特点:
- 统一的api,支持多种传输类型、比如阻塞、非阻塞,以及epoll、poll等模型
- 可以使用非常少的代码去实现多线程Reactor模型,以及主从多线程Reactor模型
- 自带编解码器,解决了TCP粘包拆包的问题
- 自带各种通信协议
- 相比JDK自带的NIO,有更高的吞吐量、更低的延迟、更低的资源消耗、更低的内存复制
- 安全性较好,有完整的 SSL/TLS 的支持
- 经历了各种大的项目的考验,社区活跃度高,例如:Dubbo、Zookeeper、RocketMQ
*Netty可以做什么事情?
我们之所以要使用Netty,核心的点是要去解决服务器如何去承载更多的用户同时访问的问题,传统的BIO模型由于阻塞的特性使得在高并发的环境种很难去支持更高的吞吐量,尽管用NIO的多路复用模型可以在阻塞方面进行优化,但是它的api使用较为复杂,而Netty是基于NIO的封装,提供了成熟简单易用的api,降低了使用成本和学习成本,本质上来说Netty和NIO所扮演的角色是相同的,都是是去为了提升服务端的吞吐量,让用户获得更好的产品体验。
Netty核心组件
Netty有三层结构构成的,分别是:
网络通信层,有三个核心组件:
Bootstrap负责客户端启动,并且去连接远程的Netty ServerServerBootStrap负责服务端的监听,用来监听指定的一个端口Channel负责网络通信的一个载体——事件调度器。
事件调度层,有两个核心角色:
EventLoopGroup本质上是一个线程池,主要去负责接收IO请求,并分发给对应的EventLoop去执行处理请求EventLoop是相对于线程池里面的一个具体线程
事件调度层的工作流程
- 初始化:在 Netty 应用启动时,首先创建
EventLoopGroup,然后根据需要创建EventLoop。 - 注册:当客户端或服务端建立连接时,会创建一个
Channel,并将该Channel注册到EventLoop上。 - 事件处理:一旦
Channel上有事件发生(如读写事件),相应的EventLoop就会被唤醒,并处理这些事件。 - 任务执行:除了处理 I/O 事件外,
EventLoop还可以执行用户提交的任务,如定时任务、异步任务等。
javaEventLoopGroup bossGroup = new NioEventLoopGroup(); // (1) 负责接受传入的连接请求 EventLoopGroup workerGroup = new NioEventLoopGroup(); // (2) 负责处理已经被接受的连接上的 I/O 操作 try { ServerBootstrap b = new ServerBootstrap(); b.group(bossGroup, workerGroup) // (3) 将 `bossGroup` 和 `workerGroup` 绑定到 `ServerBootstrap` .channel(NioServerSocketChannel.class) // (4) 指定使用的 `Channel` 类型 .childHandler(new ChannelInitializer<SocketChannel>() { // (5) 设置一个 `ChannelInitializer`,用于初始化 `Channel` 的 `Pipeline` @Override public void initChannel(SocketChannel ch) throws Exception { ch.pipeline().addLast(new EchoServerHandler()); } }); ChannelFuture f = b.bind(port).sync(); // (6) 绑定并开始监听端口 f.channel().closeFuture().sync(); // (7) 等待 `ServerChannel` 关闭 } finally { bossGroup.shutdownGracefully(); // (8) 关闭 `EventLoopGroup`,释放所有资源 workerGroup.shutdownGracefully(); // (9) 关闭 `EventLoop`,释放所有资源 }服务编排层,有三个核心组件:
ChannelPipeline负责处理多个ChannelHandler,他会把多个Channelhandler的过成一个链,去形成一个PipelineChannelHandler主要是针对10数据的一个处理器,数据接收后,就通过指定的一个上Handler进行处理ChannelHandlerContext是用来去保存ChannelHandler的一个上下文信息的。
Reactor 模型、原理、作用
Reactor模式在高性能网络编程中至关重要。许多知名软件如Nginx、Redis和Netty都基于此模式实现。无论是为了开发还是学习,掌握Reactor模式都是理解和运用这些技术的基础。在大厂面试中,Reactor模式是一个常见的考察点。简而言之,对于高性能网络编程来说,了解并掌握Reactor模式是必不可少的。
Reactor模型中的几个重要的概念:
Acceptor处理客户端的连接请求Reactor负责将IO事件分派给对应的HandlerHandlers负责执行我们的业务逻辑的读写操作Worker负责执行I/O操作
Reactor线程模型是基于事件驱动的模型,在Reactor模式中有三个重要的组件:
- Reactor:负责监视I/O事件并分发事件。当检测到一个lO事件时将其发送给相应的Handler处理器去处理。这里的IO事件就是NIO中选择器查询出来的通道IO事件。
- Handler:处理具体的业务逻辑。与lO事件(或者选择键)绑定,负责lO事件的处理,完成真正的连接建立、通道的读取、处理业务逻辑、负责将结果写到通道等。
- Worker:执行I/O操作。可以使用多个Worker线程处理具体的请求,提高并发性能。
Netty提供了三种Reactor模型的支持:
单线程单Reactor模型。在单线程Reactor模型中,所有的I/O操作(如读取请求、处理请求、发送响应)都在同一个线程中完成。这种模型适用于连接数量较少、处理逻辑较简单的场景。
执行流程:
- 事件循环初始化:创建一个单线程的Reactor,通常会注册一个Selector或epoll来监听l/O事件。
- 事件注册:服务器启动后,将自已绑定到某个端口,并注册为“accept事件”,等待客户端连接。
- 事件分发:一旦有l/O事件发生(如客户端连接、读写操作),Reactor会从Selector中获取事件,并调用相应的处理器(Handler)。
- 处理请求:Handler执行处理逻辑,包括读取客户端数据、处理业务逻辑和发送响应。因为是单线程,所有操作都必须同步进行。
- 返回结果:将处理结果返回给客户端,处理完一个事件后,再去处理下一个事件。
优点:结构简单,适用于处理量不大、请求处理时间短的场景。
缺点:因为所有I/O事件都在一个线程中完成,若某个事件的处理时间较长,会阻塞其他事件的处理,导致性能瓶颈。
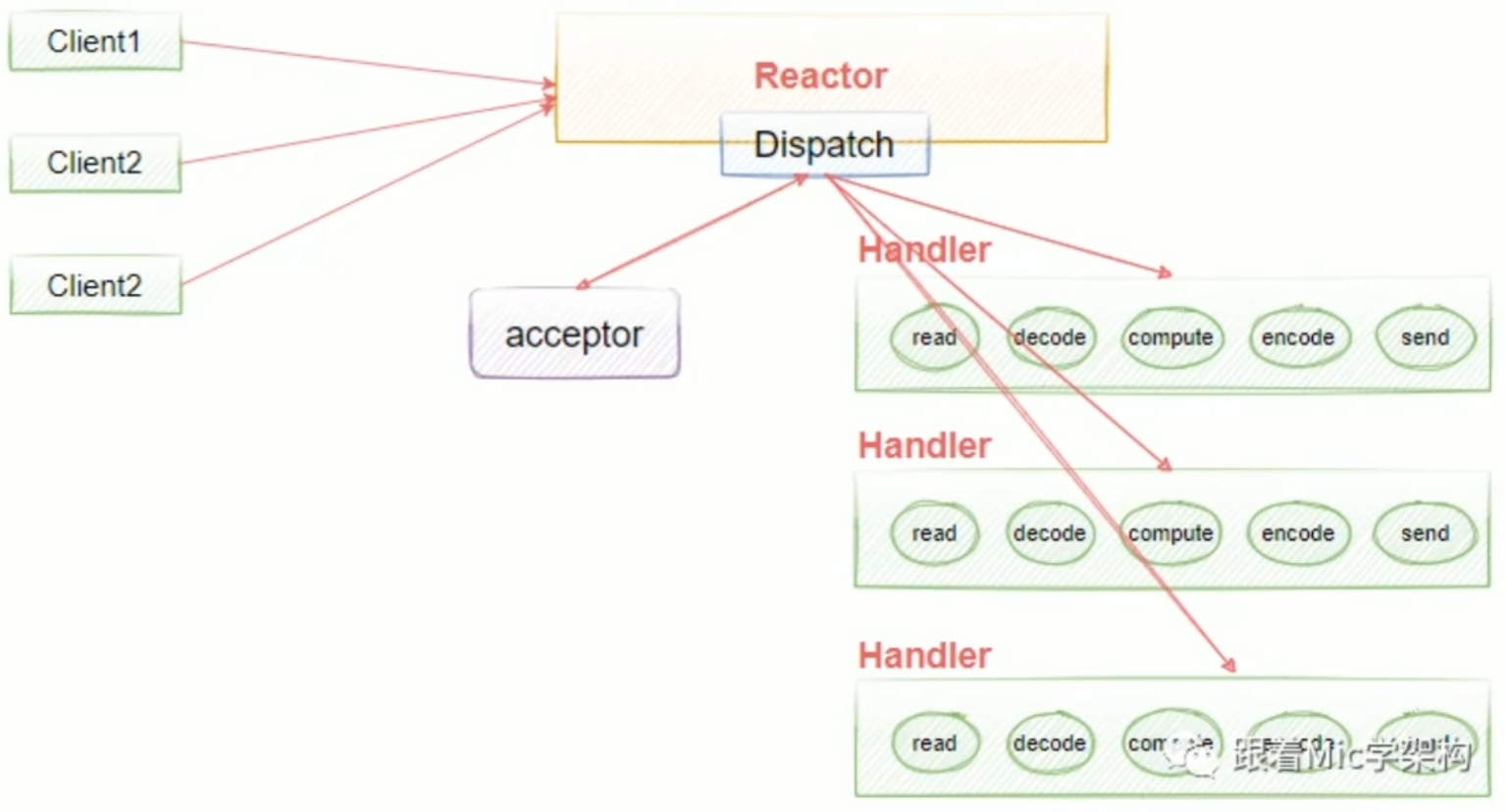
单线程单Reactor模型也有缺点:如果其中一个Handler的出现阻塞,就会导致后续的客户端无法被处理,因为它们是同一个线程,所以就导致无法接受新的请求。为了解决这个问题,就提出了使用多线程的方式(如下),也就是说在业务处理的时候加入线程池去异步处理,这样就可以解决handlers阻塞的一个问题。
多线程单Reactor模型。为了解决单线程中handlers阻塞的问题,我们引入了线程池去异步处理,这意味着我们把Reactor和handlers放在不同的线程里面去处理。在多线程单Reactor模型中,所有的IO操作都是由一个Reactor来完成的,这导致单个Reactor会存在一个性能瓶颈,对于小容量的场景影响不是很大,但是对于高并发的一些场景来说,很容易会因为单个Reactor线程的性能瓶颈,导致整个吞吐量会受到影响,所以当这个线程超过负载之后,处理的速度变慢,就会导致大量的客户端连接超时,超时之后往往会进行重发,这反而加重了这个线程的一个负载,最终会导致大量的消息积压和处理的超时,成为整个系统的一个性能瓶颈,所以我们还可以进行进一步的优化,也就是引入多线程多Reactor模型。
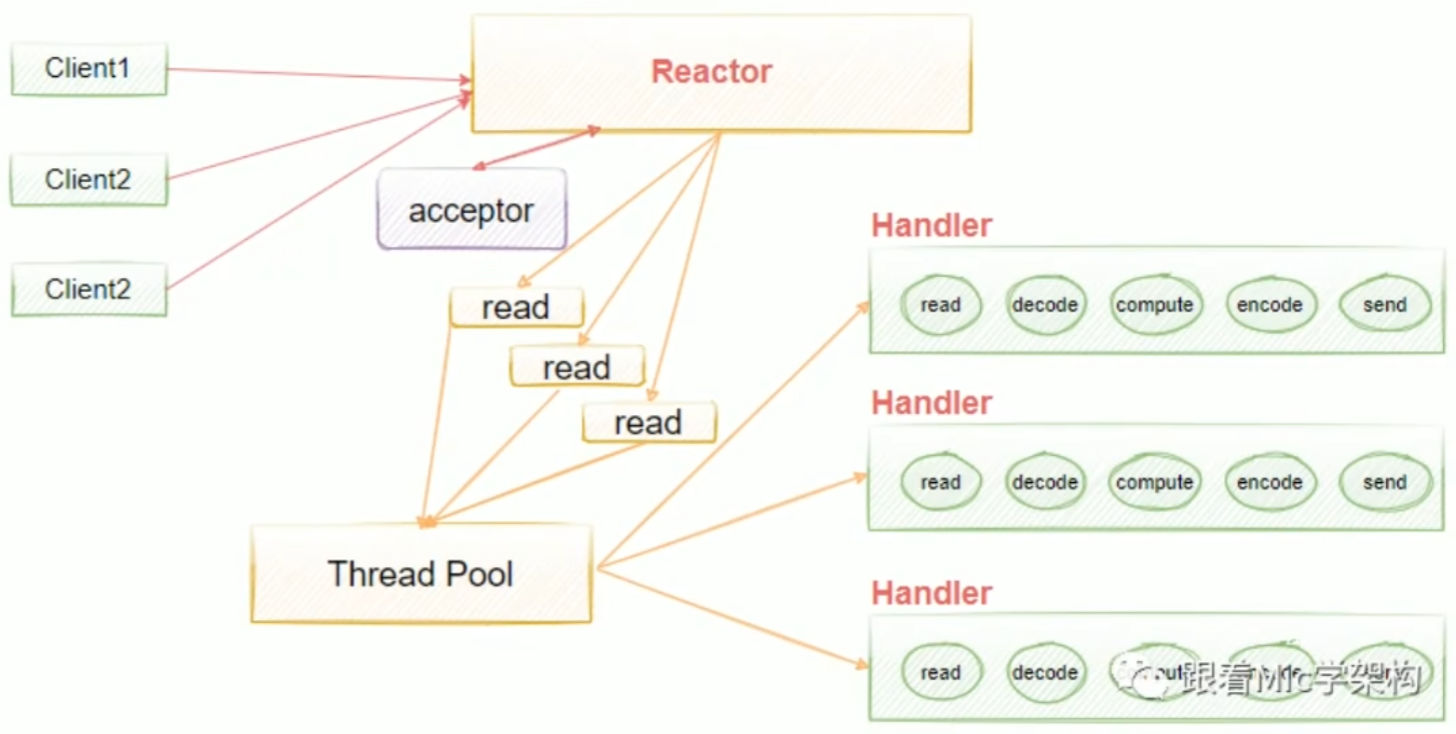
多线程Reactor模型是对单线程模型的扩展,使用了一个主线程(MainReactor)和多个工作线程(SubReactors),主线程负责事件分发,工作线程负责具体事件的处理。这种模型适用于高并发、大量连接的场景。
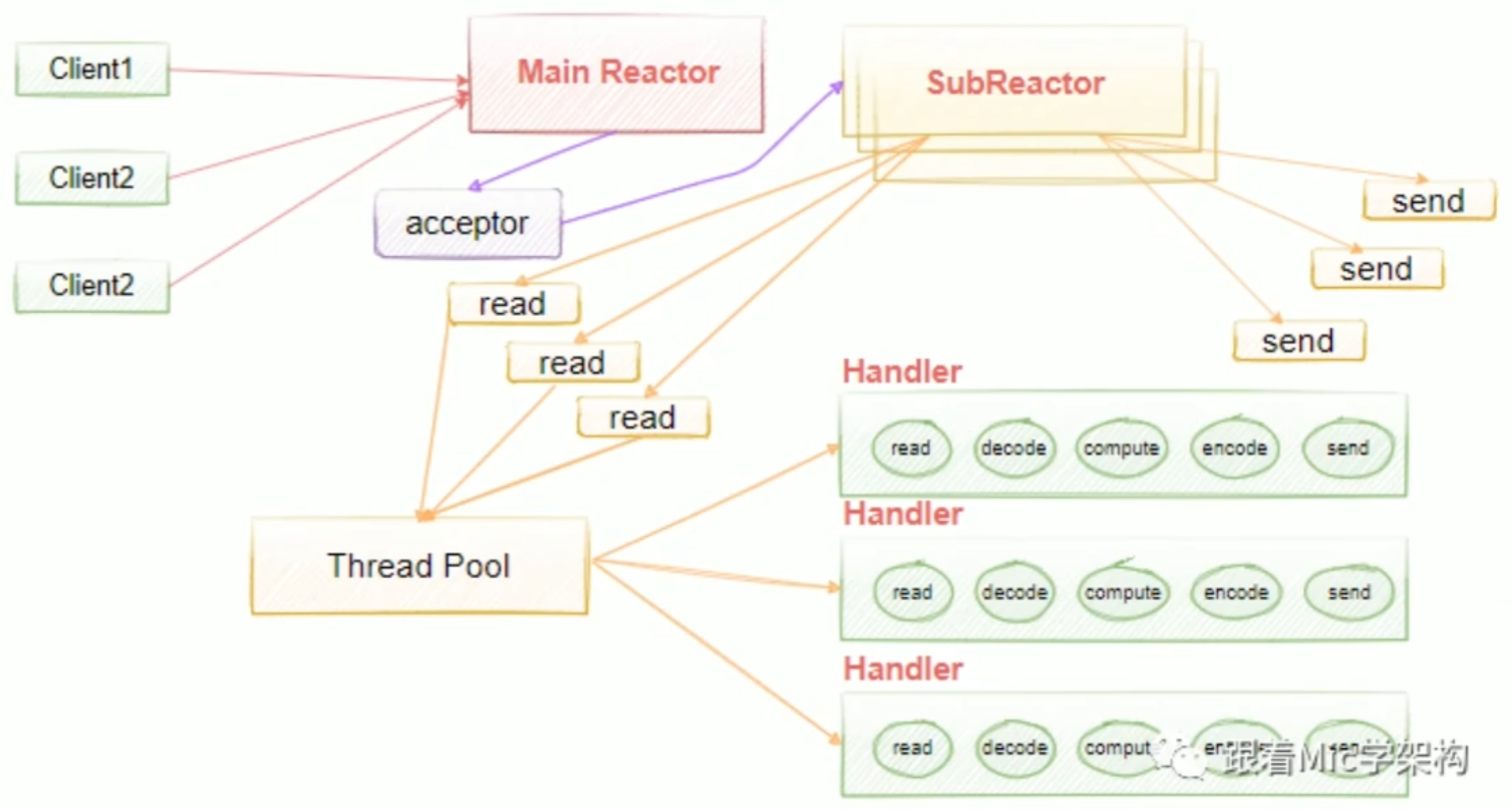
多线程多Reactor模型,也叫主从多线程Reactor模型。Main Reactor负责接收客户的连接请求,然后把接收的请求传递给Sub Reactor,Sub Reactorl我们可以配置多个,这样我们可以去进行灵活的扩容和缩容,具体的业务处理由Sub Reactor去完成,由它最终去绑定给对应的handler。Main Reactor扮演请求接收者,它会把接收的请求转发到Sub Reactor来处理,由Sub Reactor去进行真正意义上的分发。
执行流程:
- 事件循环初始化:创建一个主Reactor线程,用于监听accept事件。主Reactor的Selector负责监听客户端的连接请求。
- 事件注册:主Reactor监听客户端连接请求,并将连接的l/O事件注册到对应的工作线程的Selector上。
- 事件分发:当客户端连接建立后,主Reactor将l/O操作交给工作线程(SubReactor)处理,避免阻塞主线程。
- 处理请求:每个工作线程都有自己的Selector,并独立处理其上注册的读写事件。这样多个请求可以并行处理。
- 返回结果:处理完成后,工作线程将结果返回给客户端,同时继续监听新的/O事件。
优点:
- 主Reactor只负责连接分发,减少了阻塞,工作线程并行处理l/O事件,大大提高了处理效率。
- 支持高并发,并能有效避免单个事件处理时间过长对系统性能的影响。
缺点:
- 需要协调多个线程的资源,会增加一些开发复杂性。
- 若线程数配置不合理,可能导致频繁的上下文切换,增加系统开销。
适用场景总结
- 单线程Reactor适用于连接数量少、处理时间短的场景。
- 多线程Reactor更适合高并发、业务处理耗时较长的场景。
有了NlO为什么还需要Reactor?
在JavaNIO出现之后,为什么还需要Reactor模式?这主要是因为Reactor模式提供了一种高效的事件处理机制,它能够更好地利用NIO的特性,提高应用程序的性能和可扩展性。
以下是几个具体的理由:
- 可扩展性:通常情况下,我们会把NIO理解成单线程处理多请求的情况,对多线程的支持不太好,而Reactor模式使得系统更加容易扩展。随着并发连接数的增加,Reactor模式可以通过增加处理事件的线程数(基于线程池)来应对更高的负载。
- 事件驱动:Reactor模式也是一种基于事件驱动的设计模式,它能够处理多个并发的事件或请求,并且可以在单个或少量线程中管理这些事件。这与NIO本身的事件通知机制相辅相成。
- 解耦:Reactor模式将事件接收、事件分发和事件处理分离开来,降低了各部分之间的耦合度,使得系统更加模块化,易于维护和扩展。
- 异步处理:Reactor模式天然支持非阻塞处理,这意味着应用程序可以在不等待IO操作完成的情况下继续执行,从而提高了系统的响应速度。
Netty高性能设计
- 非阻塞IO模型:Netty基于NIO实现,使用非阻塞IO模型,减少了线程的使用,从而减少了上下文切换的开销。
- 事件驱动:Netty采用了事件驱动的设计模式,当有IO事件发生时,才会被处理,这样可以有效地利用CPU资源。
- 零拷贝技术:Netty支持直接缓冲区(DirectByteBuffer),在数据传输中减少了数据的拷贝次数,提高了数据传输的效率。具体做法是:使用
FileChannel的transferTo()和transferFrom()等方法实现文件传输时,避免了将数据从用户空间复制到内核空间的过程,提高了性能。 - 线程模型:Netty提供了高效的线程模型,如Boss/Worker模型,使得任务的分配更加合理,充分利用多核CPU的计算能力。
Netty设计模式
- 单例模式:如EventLoop。
- 观察者模式:事件的注册和触发。
- 责任链模式:通过ChannelPipeline处理多个ChannelHandler。
- 适配器模式:将不同的Handler统一处理。
处理粘包、拆包问题
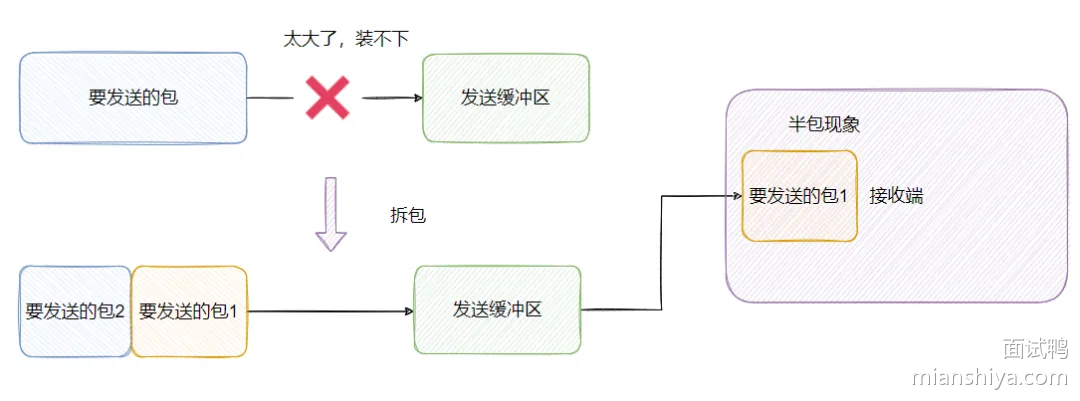
在Netty中,粘包和拆包的问题通常通过消息编码器和解码器(如LengthFieldBasedFrameDecoder、DelimiterBasedFrameDecoder等)来解析数据流。
Netty提供了几种方式来处理这种情况:
- 定长消息:如果消息长度固定,可以直接读取固定长度的数据。
- 使用分隔符(Delimiters):对于文本协议,可以使用特定的分隔符(如'\n')来分隔消息。
- 自定义协议头:在消息前加上长度字段,这样接收方可以根据长度字段读取完整的消息。
- 使用现成的编解码器:Netty提供了如LengthFieldBasedFrameDecoder这样的解码器,它可以根据消息长度字段自动处理粘包和拆包的问题。
异步非阻塞的IO操作
Netty通过使用Java NIO(非阻塞IO)技术实现了异步非阻塞的IO操作。具体来说:
- NIO:Netty基于Java NIO来实现非阻塞IO模型,使用
Selector来监听多个Channel的事件,当有事件发生时,Selector会通知相应的Channel进行处理。 - EventLoop:Netty中的
EventLoop是一个不断循环的线程,负责处理绑定在其上的Channel的所有IO操作。每个EventLoop都关联了一个Selector,用来监听Channel上的事件。 - Channel:每个
Channel都绑定了一个或多个ChannelHandler,用来处理读写事件。当有事件发生时,EventLoop会调用相应的ChannelHandler来处理事件。
示例代码如下:
// 创建EventLoopGroup
EventLoopGroup group = new NioEventLoopGroup();
try {
// 创建Bootstrap
Bootstrap b = new Bootstrap();
b.group(group)
.channel(NioSocketChannel.class)
.handler(new MyClientInitializer());
// 连接服务器
ChannelFuture cf = b.connect(new InetSocketAddress("localhost", 8080));
Channel channel = cf.sync().channel();
// 发送数据
channel.writeAndFlush(Unpooled.copiedBuffer("Hello, World!", StandardCharsets.UTF_8));
// 等待连接关闭
cf.channel().closeFuture().sync();
} finally {
group.shutdownGracefully();
}消息的有序发送
在Netty中实现消息的有序发送,可以通过以下几种方式:
- 单线程模型:如果业务逻辑要求消息必须按顺序发送,可以将所有消息的发送操作放在同一个线程中执行。这样可以保证消息的顺序性。
- ChannelPipeline:利用
ChannelPipeline中的ChannelHandler来控制消息的顺序。可以自定义ChannelHandler来实现消息的排队发送。 - ChannelFutureListener:使用
ChannelFutureListener来监听ChannelFuture的状态,确保前一个消息发送成功后再发送下一个消息。
示例代码如下:
public class OrderedMessageHandler extends SimpleChannelInboundHandler<String> {
private int messageCount = 0;
@Override
protected void channelRead0(ChannelHandlerContext ctx, String msg) throws Exception {
System.out.println("Received message " + messageCount + ": " + msg);
messageCount++;
}
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception {
for (int i = 0; i < 10; i++) {
final int index = i;
ctx.writeAndFlush("Message " + index).addListener((ChannelFutureListener) future -> {
if (future.isSuccess()) {
System.out.println("Sent message " + index);
} else {
System.err.println("Failed to send message " + index);
}
});
}
}
@Override
public void channelReadComplete(ChannelHandlerContext ctx) throws Exception {
ctx.flush();
}
}异步任务的调度
Netty提供了ScheduledExecutorService来实现异步任务调度。ScheduledExecutorService可以用来安排定时任务,包括一次性任务和周期性任务。
示例代码如下:
public class ScheduledTaskHandler extends SimpleChannelInboundHandler<String> {
private final ScheduledExecutorService scheduler = Executors.newScheduledThreadPool(1);
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception {
scheduler.scheduleAtFixedRate(() -> {
ctx.writeAndFlush("Heartbeat");
}, 0, 5, TimeUnit.SECONDS);
}
@Override
public void channelRead0(ChannelHandlerContext ctx, String msg) throws Exception {
System.out.println("Received message: " + msg);
}
@Override
public void channelReadComplete(ChannelHandlerContext ctx) throws Exception {
ctx.flush();
}
@Override
public void channelInactive(ChannelHandlerContext ctx) throws Exception {
scheduler.shutdown();
}
}参考计数
Netty中的参考计数(Reference Counting)是Netty为了管理内存而采用的一种机制。它主要用于追踪ByteBuf的引用次数。每个ByteBuf都有一个内部的引用计数器,当ByteBuf被引用时,计数器加一;当引用被释放时,计数器减一。
当ByteBuf的引用计数降到0时,意味着没有引用再指向这个ByteBuf,此时Netty会自动释放这个ByteBuf所占的内存空间。这种方式可以防止内存泄漏,并且在多线程环境下确保内存的安全释放。
异常的处理方案
在Netty中,异常处理通常是通过ChannelFutureListener和ChannelInboundHandler来实现的。
- ChannelFutureListener:可以注册一个ChannelFutureListener来监听ChannelFuture的完成状态,当操作失败时,可以抛出异常或进行其他错误处理。
- ChannelInboundHandler:当ChannelPipeline中的某个Handler抛出异常时,可以通过实现ExceptionCaught()方法来捕获并处理这些异常。通常在这个方法中打印堆栈跟踪信息或采取其他补救措施。
此外,Netty还提供了全局异常处理机制,可以注册GlobalChannelInboundHandler来处理所有未捕获的异常。
Netty 如何解决 NIO 中的空轮询 Bug
Netty通过使用Selector的poll方法,并结合EventLoop进行优化,避免了空轮询的情况。它会在没有事件时进行适当的休眠,减少CPU资源的浪费。
Channel、ChannelHandlerContext
- Channel:表示一个连接,可以是服务器端或客户端的
SocketChannel,它负责数据的读写。 - ChannelHandlerContext:表示在ChannelPipeline中每个ChannelHandler的上下文,提供了访问Channel和其他Handler的功能,用于在Handler之间传递事件和数据。
ChannelPipeline是什么?它是如何工作的?
ChannelPipeline是Netty中的一个重要概念,它是一个责任链模式的具体实现。
在Netty中,每当有数据从网络到达或者需要发送数据时,数据会沿着ChannelPipeline中的处理器链进行传递。每个处理器(Handler)都可以对数据进行处理,比如编码、解码、日志记录等。ChannelPipeline使得我们可以方便地组织和管理这些处理器,按需插入、删除或替换处理器,从而实现了高度的灵活性。
ChannelPipeline是Netty中的一个责任链模式的实现,用于管理一系列的ChannelHandler。它的工作原理如下:
- 责任链:
ChannelPipeline中包含了一系列的ChannelHandler,这些ChannelHandler按照添加的顺序组成一个责任链。 - 消息传递:当有消息从网络到达或需要发送时,消息会沿着
ChannelPipeline中的ChannelHandler传递。 - 事件传播:除了消息外,
ChannelPipeline还可以传播各种事件,如连接建立、关闭等。 - 上下文管理:通过
ChannelHandlerContext来管理当前ChannelHandler的上下文信息。
示例代码如下:
public class MyInitializer extends ChannelInitializer<SocketChannel> {
@Override
protected void initChannel(SocketChannel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast(new LoggingHandler(LogLevel.DEBUG));
pipeline.addLast(new MyHandler());
}
}
public class MyHandler extends SimpleChannelInboundHandler<String> {
@Override
protected void channelRead0(ChannelHandlerContext ctx, String msg) throws Exception {
System.out.println("Received message: " + msg);
ctx.writeAndFlush("Hello from client!");
}
@Override
public void channelReadComplete(ChannelHandlerContext ctx) throws Exception {
ctx.flush();
}
}ChannelHandler是什么?它们之间是如何通信的?
ChannelHandler是一个接口,它定义了处理网络事件的方法,如读取数据、写入数据等。我们通常会实现这个接口或者继承自AbstractChannelHandler来创建自定义的处理器。
ChannelHandler之间可以通过ChannelPipeline来通信。ChannelPipeline管理了一系列的ChannelHandler,并按照顺序处理消息。
- 消息传递:消息从一个ChannelHandler传递到另一个ChannelHandler时,会按照ChannelPipeline中定义的顺序依次处理。每个ChannelHandler可以对消息进行处理、修改或转发。
- Context传递:ChannelHandlerContext提供了与ChannelHandler相关的上下文信息,包括获取当前ChannelHandler的前后Handler,以及发送消息给当前Channel或者管道中的其他ChannelHandler。
- 事件传播:除了消息外,ChannelPipeline还可以传播各种事件,如连接建立、断开等。这些事件同样会按照顺序传递给ChannelPipeline中的各个ChannelHandler。
示例代码如下:
public class MyHandler extends ChannelInboundHandlerAdapter {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
// 对消息进行处理
ctx.fireChannelRead(msg); // 将消息传递给下一个Handler
}
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception {
// 当Channel激活时触发
ctx.fireChannelActive(); // 触发事件给下一个Handler
}
}ChannelHandlerContext是什么?有什么作用?
ChannelHandlerContext则是ChannelHandler的上下文环境,它提供了与处理器相关的上下文信息,比如可以获取当前处理器的前一个和下一个处理器,以及用于发送消息、注册定时器等功能的方法。ChannelHandlerContext在处理器中非常关键,因为它让我们可以方便地与ChannelPipeline交互。
ChannelHandlerContext是Netty中的一个重要的上下文环境对象,它提供了与ChannelHandler相关的上下文信息。主要作用包括:
- 上下文信息:提供当前
ChannelHandler的上下文信息,如获取当前ChannelHandler的前后ChannelHandler。 - 消息传递:可以用来向当前
Channel或管道中的其他ChannelHandler发送消息。 - 事件传播:可以用来触发事件给当前
Channel或管道中的其他ChannelHandler。 - 访问Channel属性:提供了访问和修改
Channel属性的方法。
示例代码如下:
public class MyHandler extends SimpleChannelInboundHandler<String> {
@Override
protected void channelRead0(ChannelHandlerContext ctx, String msg) throws Exception {
System.out.println("Received message: " + msg);
ctx.writeAndFlush("Hello from client!"); // 向服务器发送消息
}
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) throws Exception {
cause.printStackTrace();
ctx.close(); // 关闭连接
}
}Channel和ChannelHandlerContext的关系是什么?
在Netty中,Channel代表了网络连接的一个端点,它封装了网络连接的生命周期,包括连接、读取、写入等操。
ChannelHandlerContext则是Channel的一个上下文环境,它为ChannelHandler提供了执行上下文。
ChannelHandlerContext包含了当前ChannelHandler的信息,以及对ChannelPipeline的操作方法。通过ChannelHandlerContext,我们可以获取当前ChannelHandler的前后Handler,发送消息给当前Channel或者管道中的其他ChannelHandler,以及访问Channel的各种属性等。
Channel和ChannelFuture的区别是什么?
Channel和ChannelFuture`在Netty中有不同的作用:
Channel:代表了网络连接的一个端点,封装了网络连接的生命周期,包括连接、读取、写入等操作。Channel提供了执行这些操作的方法。ChannelFuture:表示异步通道操作的结果,提供了方法来检查异步操作的状态,如是否完成、成功或失败等。ChannelFuture通常用于异步操作的同步等待和结果监听。
示例代码如下:
public class MyServerInitializer extends ChannelInitializer<SocketChannel> {
@Override
protected void initChannel(SocketChannel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast(new LoggingHandler(LogLevel.DEBUG));
pipeline.addLast(new MyServerHandler());
// 使用ChannelFuture进行同步等待
ChannelFuture future = ch.closeFuture();
future.sync();
}
}Selector机制是如何工作的?
Netty中的Selector机制主要用于处理网络连接的读写事件。在Java NIO中,Selector允许我们监听多个Channel的事件,如连接、读取、写入等。当有事件发生时,Selector会通知相应的Channel,这样我们就可以处理这些事件。
在Netty中,通常每个EventLoopGroup对应一个Selector,而每个EventLoop负责处理绑定到它的Channel的IO操作。当一个Channel上有事件发生时,EventLoop会轮询Selector,发现有事件就调用相应的Handler来处理。
EventLoop和EventLoopGroup有什么区别?
EventLoop和EventLoopGroup是Netty中用来处理IO操作的关键组件。
- EventLoop:它是Netty中的一个线程,负责处理绑定到它的Channel的IO操作,如读取、写入和连接等。每个EventLoop都有一个Selector,用来监听Channel上的事件。
- EventLoopGroup:它是一组EventLoop的集合,用于管理多个EventLoop。EventLoopGroup负责为新创建的Channel分配合适的EventLoop。Netty中有两种类型的EventLoopGroup:BossGroup和WorkerGroup。BossGroup负责接受客户端的连接请求,而WorkerGroup负责处理已经被接受的连接上的读写操作。
Future和Promise是什么?它们的作用是什么?
Netty中的Future和Promise是用于处理异步操作的结果和状态的。
- Future:表示异步操作的结果,它提供了一些方法来检查异步操作是否完成,以及获取操作的结果或抛出异常。使用Future可以很容易地实现异步编程模型。
- Promise:是一个特殊的Future,它还提供了一个方法来设置异步操作的结果。Promise通常用于Channel操作,如注册、连接、写入等,它允许在异步操作完成后设置结果或异常。
使用Future和Promise可以更好地控制异步操作的生命周期,处理异步回调中的异常,并且可以方便地进行链式调用。
接口不能包含构造函数,接口中的成员变量默认为常量。
抽象类可以包含构造函数,成员变量可以有不同的访问修饰符。
3)多继承
抽象类只能单继承,接口可以有多个实现。
-----------------容器化技术----------------
Docker 的基本概念和工作原理
Docker 是一种开源的容器化平台,允许开发者和运维人员以一致的方式部署应用程序。通过将应用程序及其所有依赖打包到一个单独的容器中,Docker 提供了一种便捷的方式来执行和移动应用程序。这种容器在任何符合所需条件的环境中都能保证其运行一致。
工作原理上,Docker 利用 Linux 容器(LXC)的技术,并通过镜像(Image)、容器(Container)、仓库(Repository)等主要概念来实现应用的生命周期管理。具体来说,开发者首先创建一个 Docker 镜像,镜像是一个只读模板,包含应用程序及其运行所需的所有文件。然后,基于这个镜像,Docker 可以启动一个或多个容器,容器是镜像的运行实例。
Docker Compose 的主要用途是什么?
Docker Compose 是用于定义和运行多容器 Docker 应用程序的工具。Compose 使用 YAML 文件定义服务、网络和卷,通过一条简单的命令 docker-compose up 就可以启动并运行整个配置的应用环境。
举个例子,如果你有一个 web 应用,需要用到 MySQL 数据库,传统上你可能需要分别配置和运行这两个服务。而在 Docker Compose 中,你只需要创建一个 docker-compose.yml 文件,定义好 web 服务和 db 服务的配置,然后运行 docker-compose up 即可。
Docker 镜像的构建过程
- 编写 Dockerfile:其中包含了一系列的指令,描述了如何构建一个 Docker 镜像。
- 构建镜像:使用
docker build命令,通过读取 Dockerfile 的内容,逐步执行其中的指令,最终生成一个 Docker 镜像。 - 保存镜像:构建完成的镜像会被保存到本地的 Docker 镜像库中,可以使用
docker images命令查看。 - 发布镜像:如果需要共享镜像,可以将其推送到 Docker Hub 或其他镜像仓库,使用
docker push命令完成发布。 - 使用镜像:最终用户可以使用
docker run命令来启动基于该镜像的容器,完成应用的部署和运行。
Dockerfile 的作用
- 描述构建过程:Dockerfile 通过一系列的指令详细描述了构建镜像的步骤,包括基础镜像、环境配置、软件安装等。
- 保证一致性:同一个 Dockerfile 可以在不同环境下生成一致的镜像,确保应用运行环境的稳定和一致。
- 自动化构建:通过 Dockerfile,可以方便地实现镜像的自动化构建,简化了持续集成和持续部署(CI/CD)过程。
- 版本管理:Dockerfile 可以使用版本控制工具进行管理,方便回滚或跟踪更改记录。
使用 Dockerfile 创建自定义镜像
- 编写 Dockerfile:Dockerfile 是一个文本文件,包含了一系列指令,每个指令用来描述如何构建镜像。通常包括基础镜像的选择、复制文件、安装包以及配置环境等操作。
- 构建镜像:使用
docker build命令来构建镜像。
简单示例:
- 创建一个名为
Dockerfile的文件,内容如下:
# 选择基础镜像
FROM ubuntu:latest
# 安装一些软件包
RUN apt-get update && apt-get install -y python3 python3-pip
# 设置工作目录
WORKDIR /app
# 复制当前目录下的文件到工作目录
COPY .. /app
# 安装 Python 依赖
RUN pip3 install -r requirements.txt
# 暴露端口
EXPOSE 80
# 设置容器启动时默认执行的命令
CMD ["python3", "app.py"]- 运行构建命令,将 Dockerfile 构建为镜像:
docker build -t my_custom_image:latest .如何优化容器启动时间?
- 使用较小的基础镜像:选择精简的基础镜像,例如
alpine,或其他定制过的轻量级基础镜像,例如scratch。 - 减少镜像层数:每一层都会增加容器启动的开销,精简 Dockerfile,合并多个
RUN命令,将有助于减少层数。 - 利用缓存:在构建镜像时尽量利用 Docker 的缓存功能,避免每次都重建镜像。
- 适当配置健康检查:配置适当的健康检查策略,让容器可以尽快转为运行状态,而不是卡在启动过程中。
- 本地化镜像:将常用的容器镜像保存在本地镜像库中,避免每次启动时从远程仓库拉取。
如何实现容器之间的通信?
- 使用同一个网络: 将多个容器连接到同一个 Docker 网络中,这样容器之间可以通过容器名称进行互相通信。
- 端口映射: 将容器的端口映射到宿主机的端口,通过宿主机的 IP 和映射的端口进行通信。
- Docker Compose: 使用 Docker Compose 来编排多个服务,可以为每个服务定义网络,并对网络进行配置。
- 共享网络命名空间: 通过创建共享网络命名空间的方式,使多个容器共享网络设置。
如何实现资源限制?
- 为了限制容器使用的 CPU 数量,可以使用
--cpu-shares或--cpus参数。--cpu-shares:使用相对权重方式分配 CPU 资源。--cpus:直接指定容器可使用的 CPU 核数。
- 为了限制容器使用的内存量,可以使用
-m或--memory参数。--memory:指定容器最大内存限制。
举个简单的例子,如果我们希望某个容器最多使用一个CPU核心和 512MB 内存,可以使用以下命令:
docker run --cpus=1 --memory=512m [container_name]----------------自动化服务器---------------
自动发布的好处
CI/CD:持续集成(CI)、持续交付(CD)
持续交付:指开发人员频繁地将代码更改合并到主代码库中。每次提交后,自动化工具会执行构建和测试,以确保新代码不会引入错误。
持续交付:旨在通过自动化构建、测试和部署过程,使得软件能够在任何时间点都可以安全地发布到生产环境中。
一般认为:自动发布可以节省人工编译、部署的时间
那是否?只有项目较大、服务器较多的情况下才需要自动发布呢?
无论项目大小、服务器多少都应该采用自动发布进行编译、部署,包括开发环境、测试环境、生产环境,因为在实际发布的环境下除了替换程序、重启服务,还需要人工修改配置、替换某些文件等,一些服务的启动顺序也是有特殊要求的,而且如果发布测试时发现了问题,则发布行为需要循环多次,如果是人工发布,则会产生很多人为失误,一来二去,会花掉很多不必要的时间。
自动发布真正的好处:并不是单单节省了多服务器的部署时间,免去人工编译、部署时可能发生的人为失误,从而节省无意间浪费的成本。
Jenkins介绍
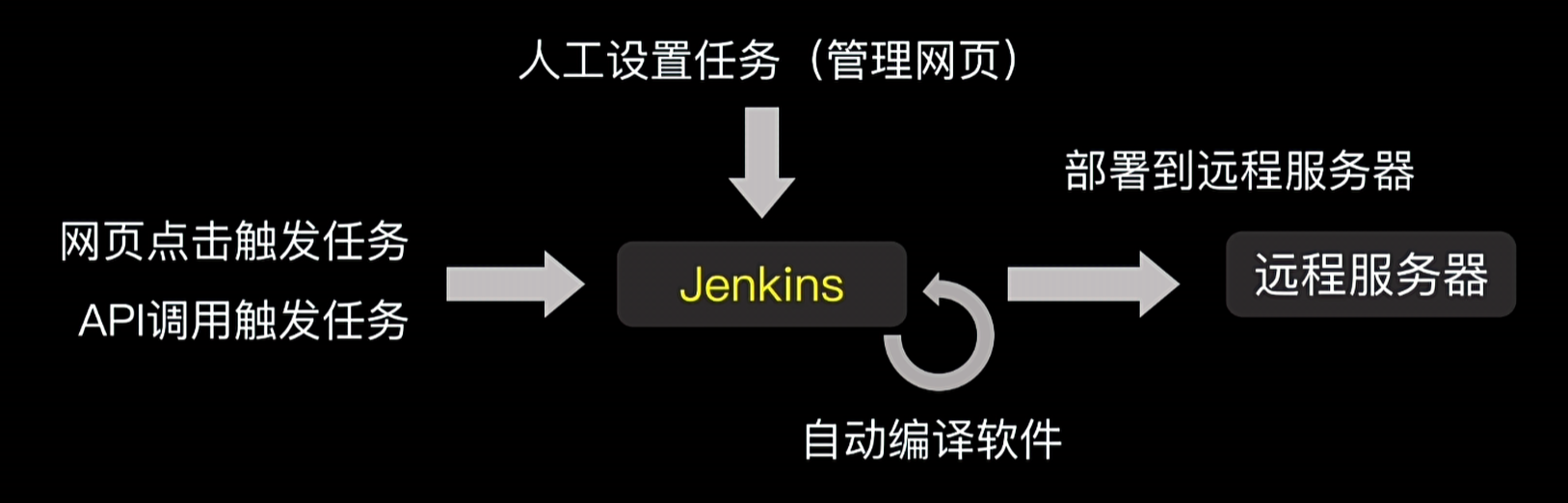
Jenkins是一个自动发布部署软件的系统,可以简单地将Jenkins理解为一个网站系统,在管理网站上,用户可以编排自动发布任务,可以实现代码下载-代码编译-文件发送-执行远程命令等场景,当条件触发时,Jenkins就会自动按预设任务进行编译部署。
例如:Git代码仓库创建了新tag标识后,Jenkins可以自动下载代码并编译发布到运行的服务器,实现自动发布。
Jenkins安装
使用1Panel一键安装
Jenkins发布流程配置
TODO
如何使用 Jenkins 与 Docker 集成?
- 安装必要的插件:在 Jenkins 中,安装 Docker plugin 和 Pipeline plugin 等必要插件。
- 配置 Jenkins:配置环境,确保 Jenkins 可以访问 Docker 命令。
- 创建 Jenkins Pipeline:在 Jenkins 中创建一个 Pipeline 项目,并在 Pipeline Script 中编写构建、测试和部署的脚本,通常使用 Jenkinsfile。
- 运行与监控:配置好所有步骤后,运行 Pipeline 并监控执行过程,确保一切正常工作。
----------------容器编排引擎----------------
Kubernetes 是什么?
Kubernetes,它是 Google 开源的神器,它介于应用服务和服务器之间,能够通过策略,协调和管理多个应用服务,只需要一个 yaml 文件配置,定义应用的部署顺序等信息,就能自动部署应用到各个服务器上,还能让它们挂了自动重启,自动扩缩容。
Kubernetes 解决的问题
随着应用服务变多,需求也千奇百怪。有的应用服务不希望被外网访问到,有的部署的时候要求内存得大于 xxGB 才能正常跑。 你每次都需要登录到各个服务器上,执行手动操作更新。不仅容易出错,还贼浪费时间。那么问题就来了,有没有一个办法,可以解决上面的问题?当然有,没有什么是加一个中间层不能解决的,如果有,那就再加一层。这次要加的中间层,叫 Kubernetes。
为什么要用 Kubernetes ?
在Kubernetes出现之前,我们一般都是使用Docker来管理容器化的应用。
但是Docker只是一个单机的容器管理工具,它只能管理单个节点上的容器,当我们的应用程序需要运行在多个节点上的时候,就需要使用一些其他的工具来管理这些节点,比如Docker Swarm、Mesos、Kubernetes等等。
这些工具都是容器编排引擎,它们可以用来管理多个节点上的容器,但是它们之间也有一些区别:
- Docker Swarm是Docker官方提供的一个容器编排引擎,它的功能比较简单,适合于一些小型的、简单的场景
- Mesos和Kubernetes则是比较复杂的容器编排引擎,Mesos是Apache基金会的一个开源项目
- Kubernetes是Google在2014年开源的,目前已经成为了CNCF(Cloud Native Computing Foundation)的一个顶级项目,基本上已经成为了容器编排引擎的事实标准了。
Kunbernetes 与 Docker之间的关系
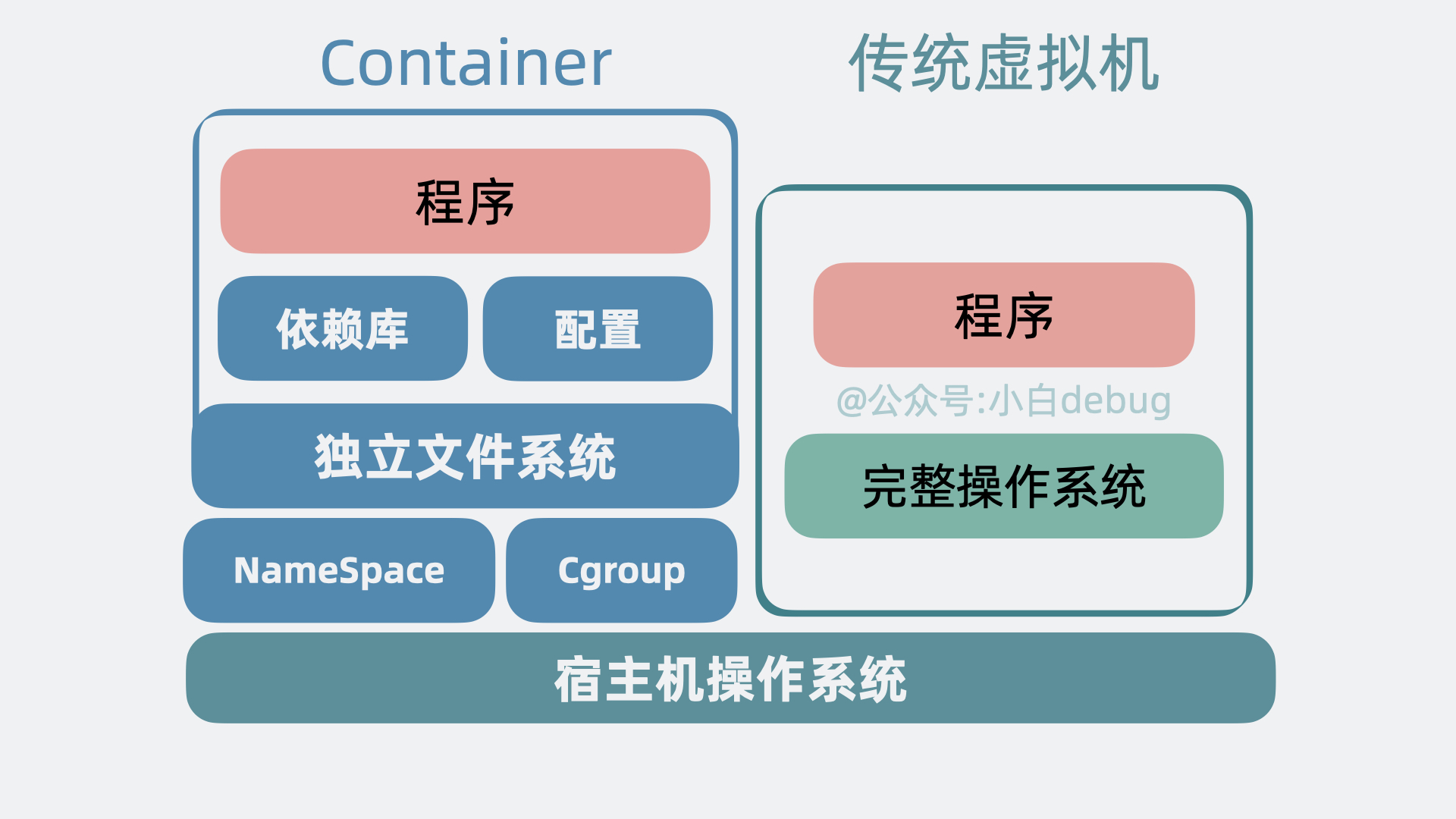
Kubernetes 与 Docker 之间的关系可以概括为互补关系,两者在容器化技术的不同层面发挥作用。
Docker
Docker 是一个开源的容器化平台,它允许开发人员将应用程序及其依赖项打包到一个可移植的容器中,确保这些容器可以在任何支持 Docker 的环境中一致地运行。Docker 解决了开发、测试和生产环境之间的一致性问题,使得应用程序的开发、测试和部署过程更加一致和可靠。Docker 的主要组成部分包括:
- 镜像:包含了应用程序及其所需的所有依赖项的快照。
- 容器:基于镜像运行的实例,提供了一个隔离的环境来运行应用程序。
- 仓库:存储和分享镜像的地方,如 Docker Hub。
Kubernetes
Kubernetes 是一个开源的容器编排系统,它用于自动化部署、扩展和管理容器化应用程序。Kubernetes 提供了一系列强大的功能,比如服务发现、负载均衡、滚动更新、自动恢复等,使得开发人员可以更加轻松地构建、部署和管理大规模容器化应用程序。Kubernetes 的核心概念包括:
- Pod:Kubernetes 中最小的部署单位,它可以包含一个或多个容器,这些容器共享存储、网络等资源。
- Service:一种抽象,定义了一组逻辑上的 Pod 和访问策略。
- Deployment:用于管理应用程序的副本,确保指定数量的 Pod 始终处于运行状态。
- StatefulSet:用于管理有状态的应用程序,保证每个 Pod 的唯一身份。
关系
- 互补性:Docker 和 Kubernetes 各自解决了容器化技术的不同方面。Docker 专注于单个容器的生命周期管理,而 Kubernetes 则关注多个容器的组织、管理和调度。
- 集成:虽然 Kubernetes 可以使用多种容器运行时(如 containerd、CRI-O 等),但 Docker 是最常用的容器运行时之一。Kubernetes 可以直接使用 Docker 镜像,并通过其 Pod 概念管理 Docker 容器。
- 生态系统:两者都拥有庞大的生态系统和社区支持,共同推动了容器技术的发展。
实际应用
在实际应用中,开发人员通常会使用 Docker 来构建和打包应用程序,然后使用 Kubernetes 来部署和管理这些容器化应用程序。这种结合使用的方式可以充分利用 Docker 和 Kubernetes 的各自优势,提高应用程序的开发、测试和部署效率。
总之,Kubernetes 和 Docker 之间是互补而非竞争的关系。它们共同构成了现代云原生应用开发和部署的重要基石。

Kubernetes 架构原理
为了实现上面的功能,Kubernetes 会将我们的服务器划为两部分,一部分叫控制平面(control plane,以前叫master),另一部分叫工作节点,也就是 Node。简单来说它们的关系就是老板和打工人, 用现在流行的说法就是训练师和帕鲁。控制平面负责控制和管理各个 Node,而 Node 则负责实际运行各个应用服务。
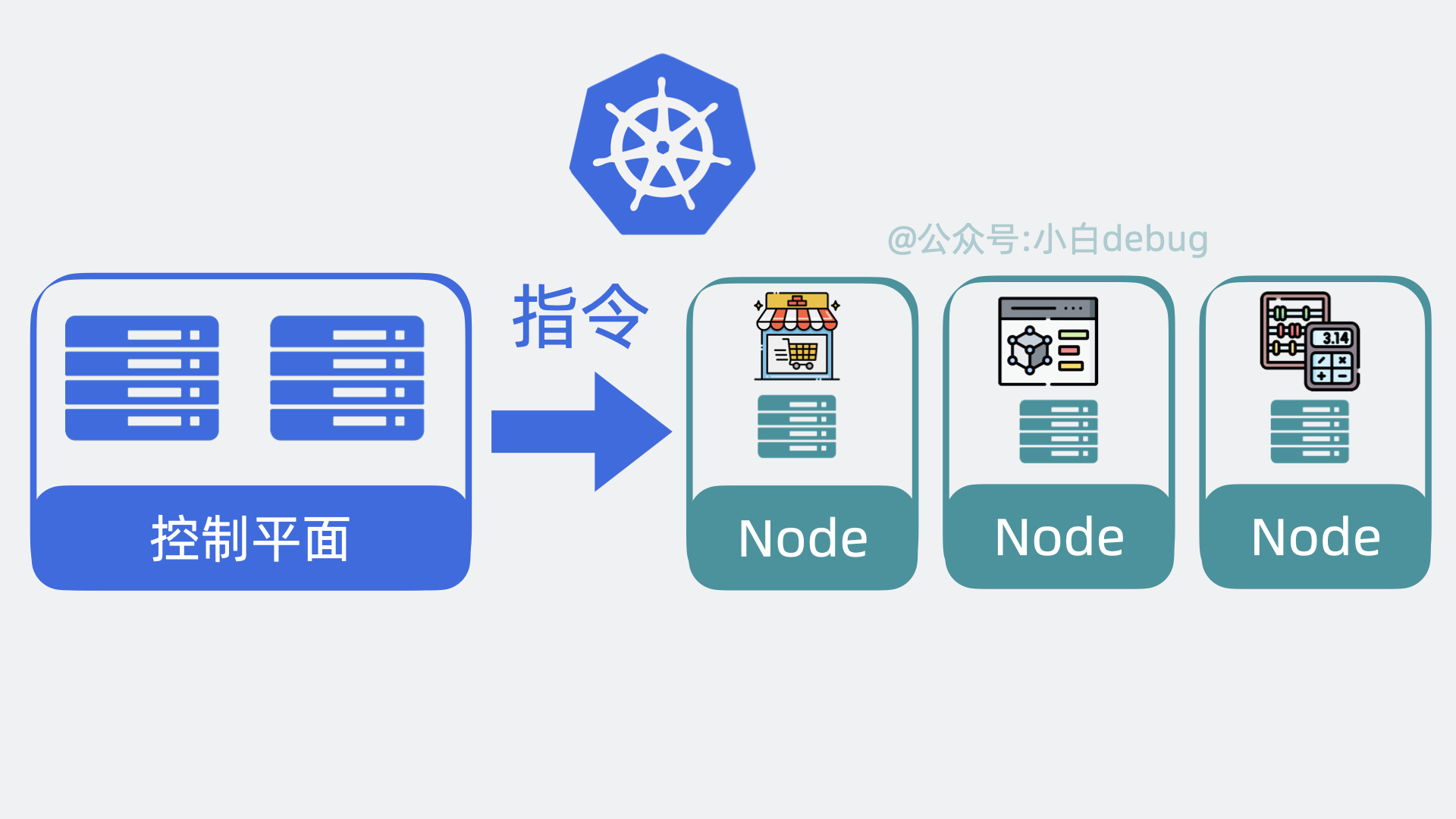
我们依次看下这两者的内部架构。
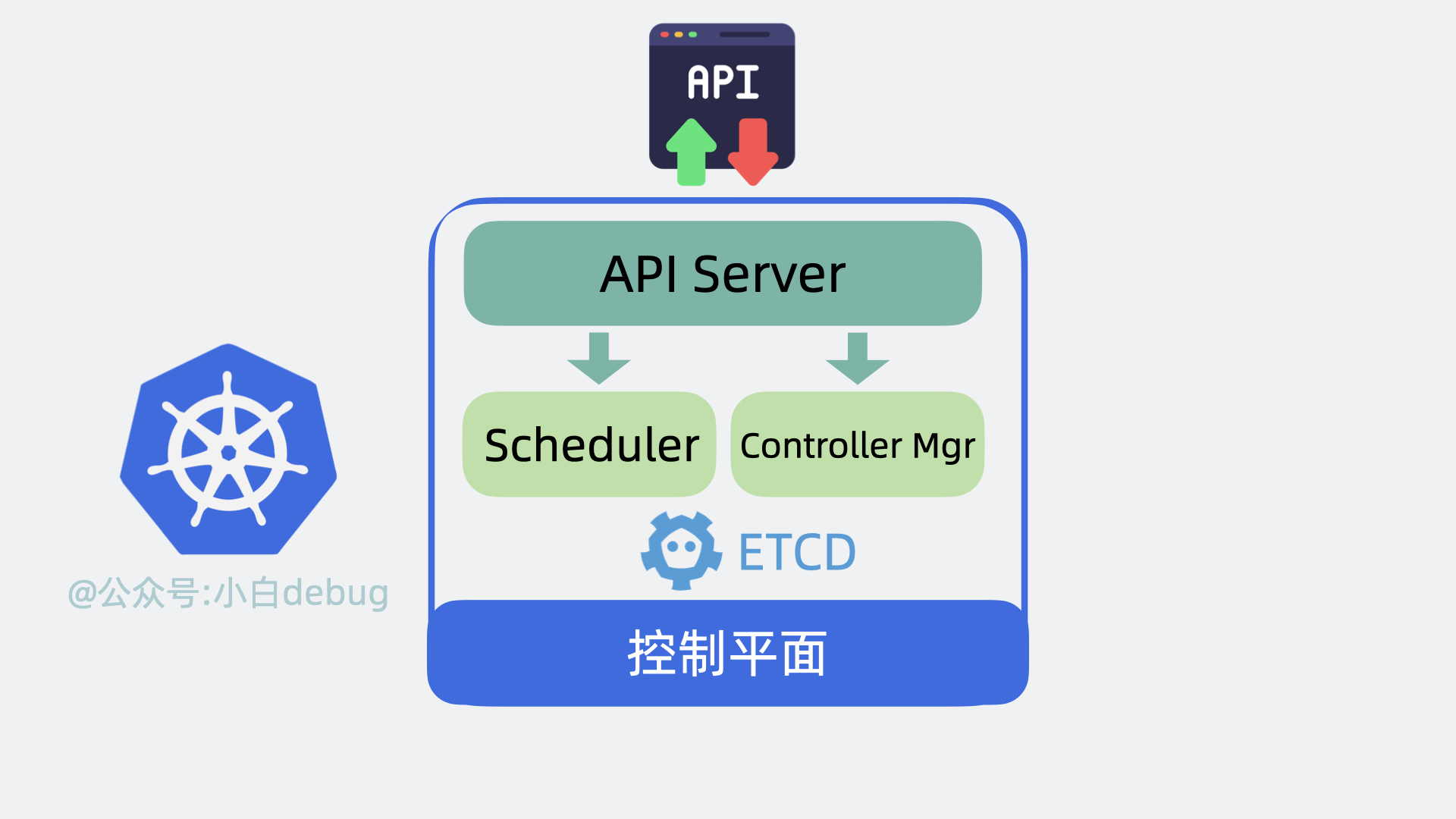
控制平面内部组件
- 以前我们需要登录到每台服务器上,手动执行各种命令,现在我们只需要调用 k8s 的提供的 api 接口,就能操作这些服务资源,这些接口都由 API Server 组件提供。
- 以前我们需要到处看下哪台服务器 cpu 和内存资源充足,然后才能部署应用,现在这部分决策逻辑由 Scheduler(调度器)来完成。
- 找到服务器后,以前我们会手动创建,关闭服务,现在这部分功能由 Controller Manager(控制器管理器)来负责。
- 上面的功能都会产生一些数据,这些数据需要被保存起来,方便后续做逻辑,因此 k8s 还会需要一个存储层,用来存放各种数据信息,目前是用的 etcd,这部分源码实现的很解耦,后续可能会扩展支持其他中间件。
以上就是控制平面内部的组件。
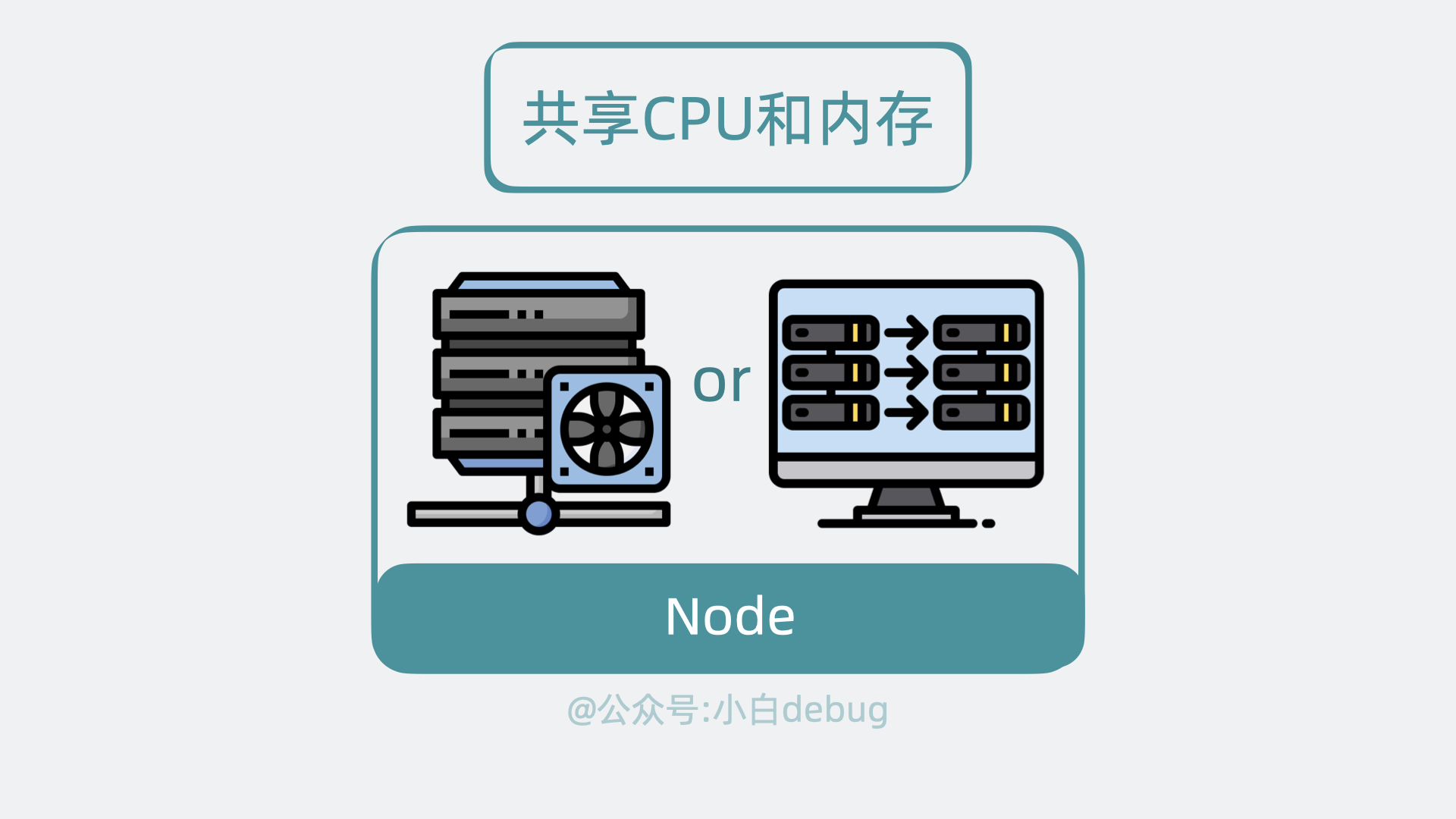
我们接下来再看看 Node 里有哪些组件。
Node 内部组件
Node 是实际的工作节点,它既可以是裸机服务器,也可以是虚拟机。它会负责实际运行各个应用服务。多个应用服务共享一台 Node 上的内存和 CPU 等计算资源。
在文章开头,我们聊到了部署多个应用服务的场景。以前我们需要上传代码到服务器,而用了 k8s 之后,我们只需要将服务代码打包成Container Image(容器镜像),就能一行命令将它部署。
如果你不了解容器镜像的含义,你可以简单理解为它其实就是将应用代码和依赖的系统环境打了个压缩包,在任意一台机器上解压这个压缩包,就能正常运行服务。为了下载和部署镜像,Node 中会有一个 Container runtime 组件。
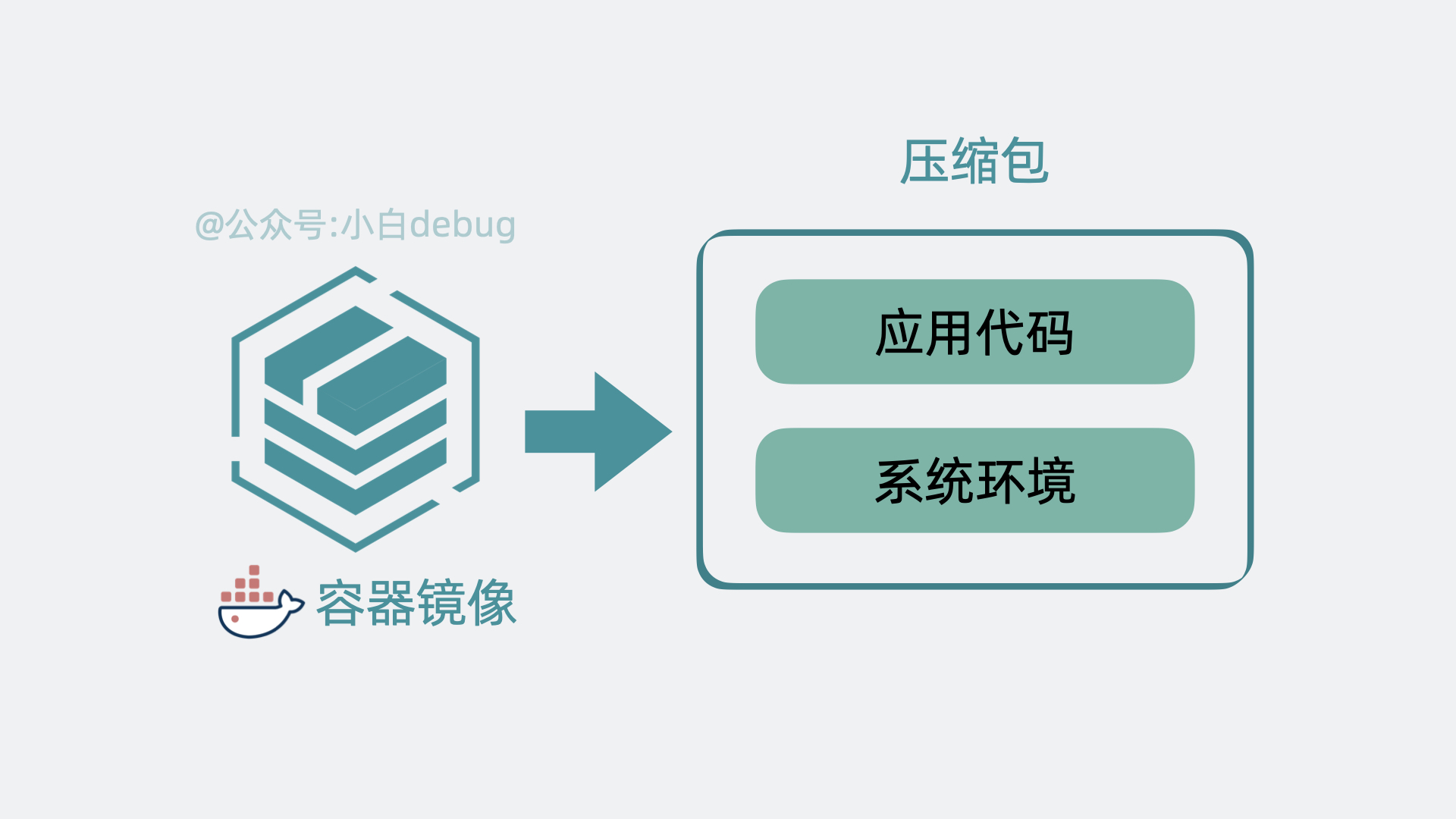
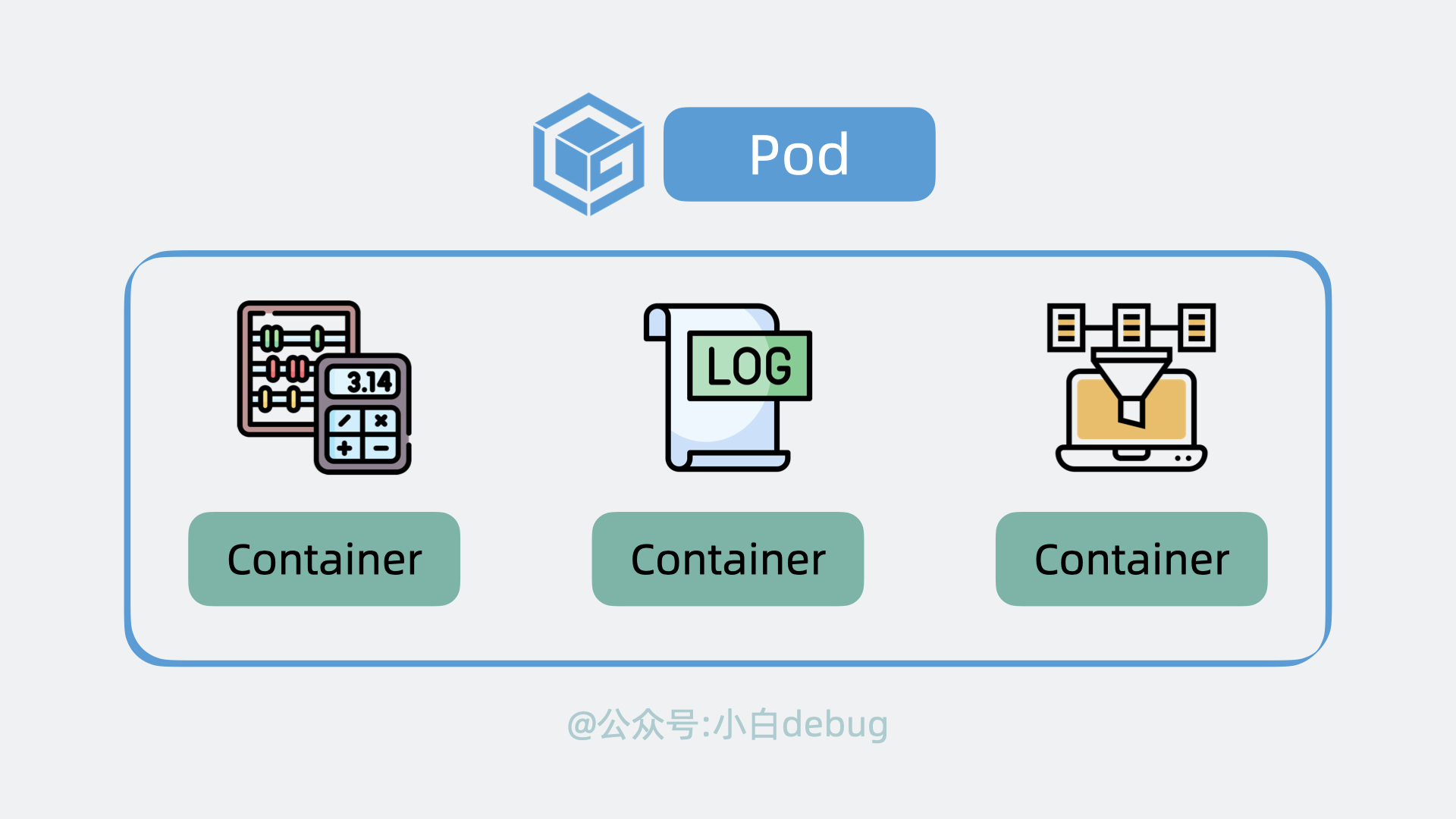
每个应用服务都可以认为是一个 Container(容器), 并且大多数时候,我们还会为应用服务搭配一个日志收集器 Container 或监控收集器 Container,多个 Container 共同组成一个一个 Pod,它运行在 Node 上。
k8s 可以将 pod 从某个 Node 调度到另一个 Node,还能以 pod 为单位去做重启和动态扩缩容的操作。 所以说 Pod 是 k8s 中最小的调度单位。
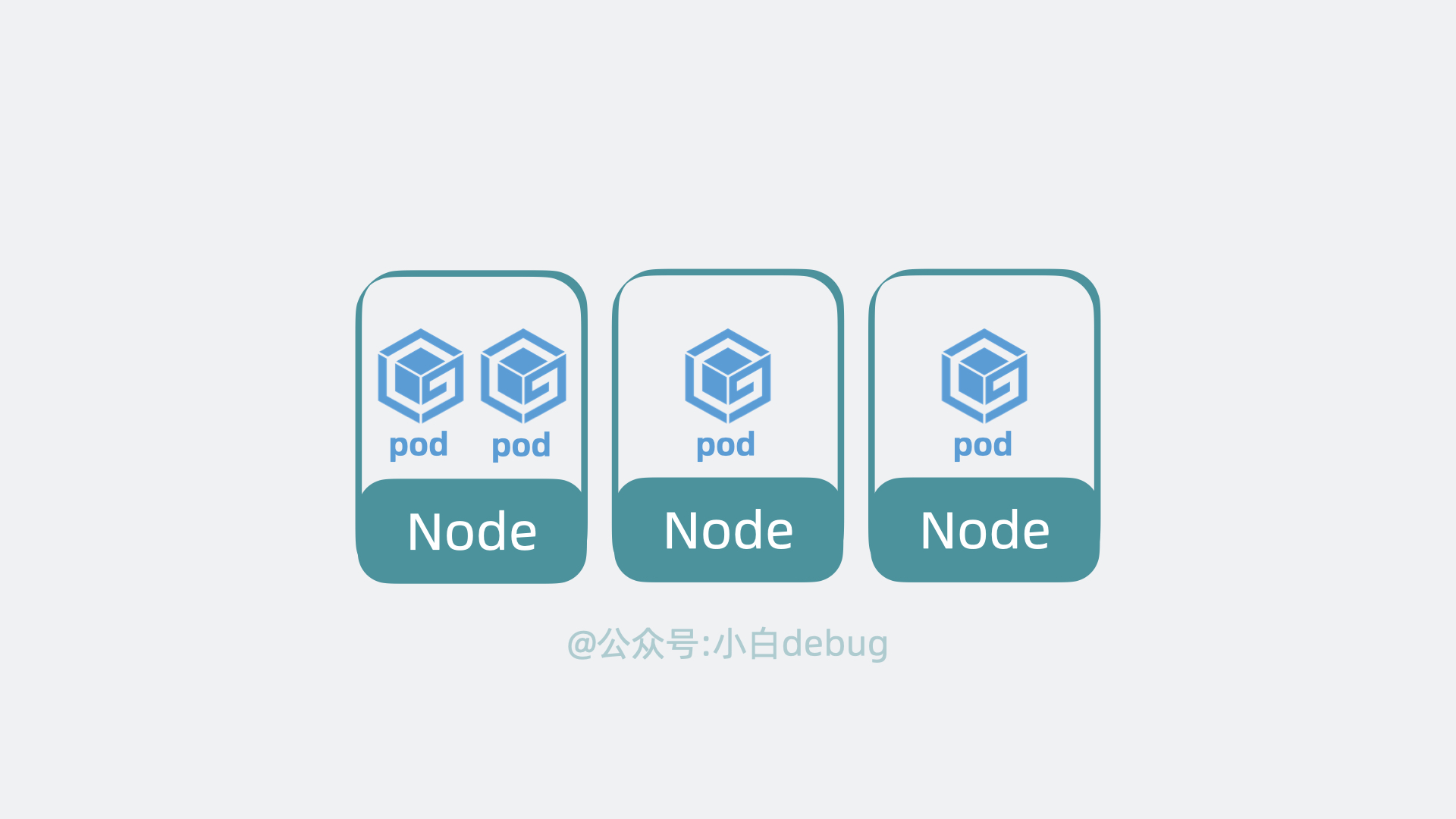
另外,前面提到控制平面会用 Controller Manager (通过API Server)控制 Node 创建和关闭服务,那 Node 也得有个组件能接收到这个命令才能去做这些动作,这个组件叫 kubelet,它主要负责管理和监控 Pod。最后,Node 中还有个 Kube Proxy ,它负责 Node 的网络通信功能,有了它,外部请求就能被转发到 Pod 内。
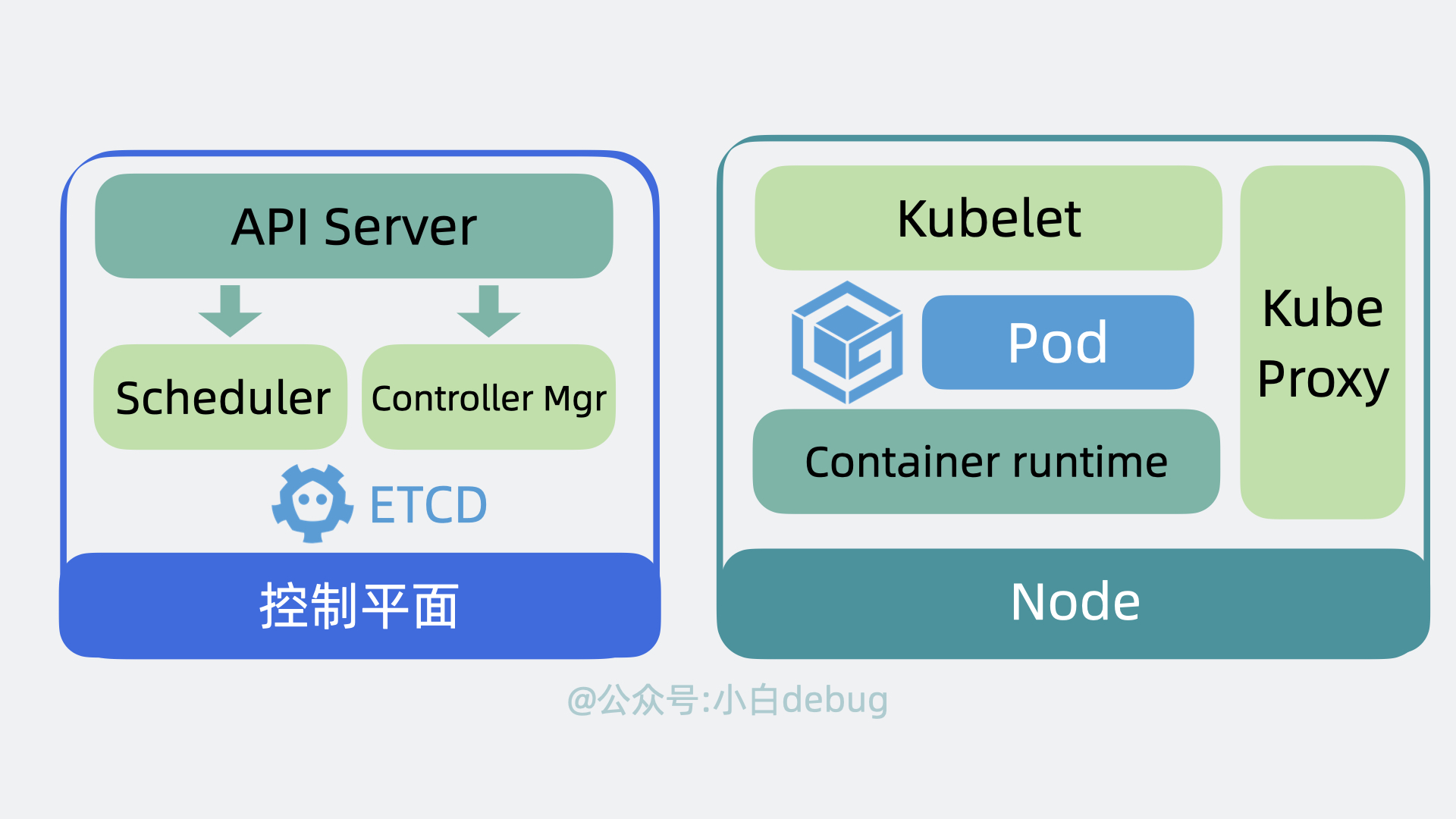
Cluster
控制平面和Node 共同构成了一个 Cluster,也就是集群。在公司里,我们一般会构建多个集群, 比如测试环境用一个集群,生产环境用另外一个集群。同时,为了将集群内部的服务暴露给外部用户使用,我们一般还会部署一个入口控制器,比如 Ingress 控制器(比如Nginx),它可以提供一个入口让外部用户访问集群内部服务。
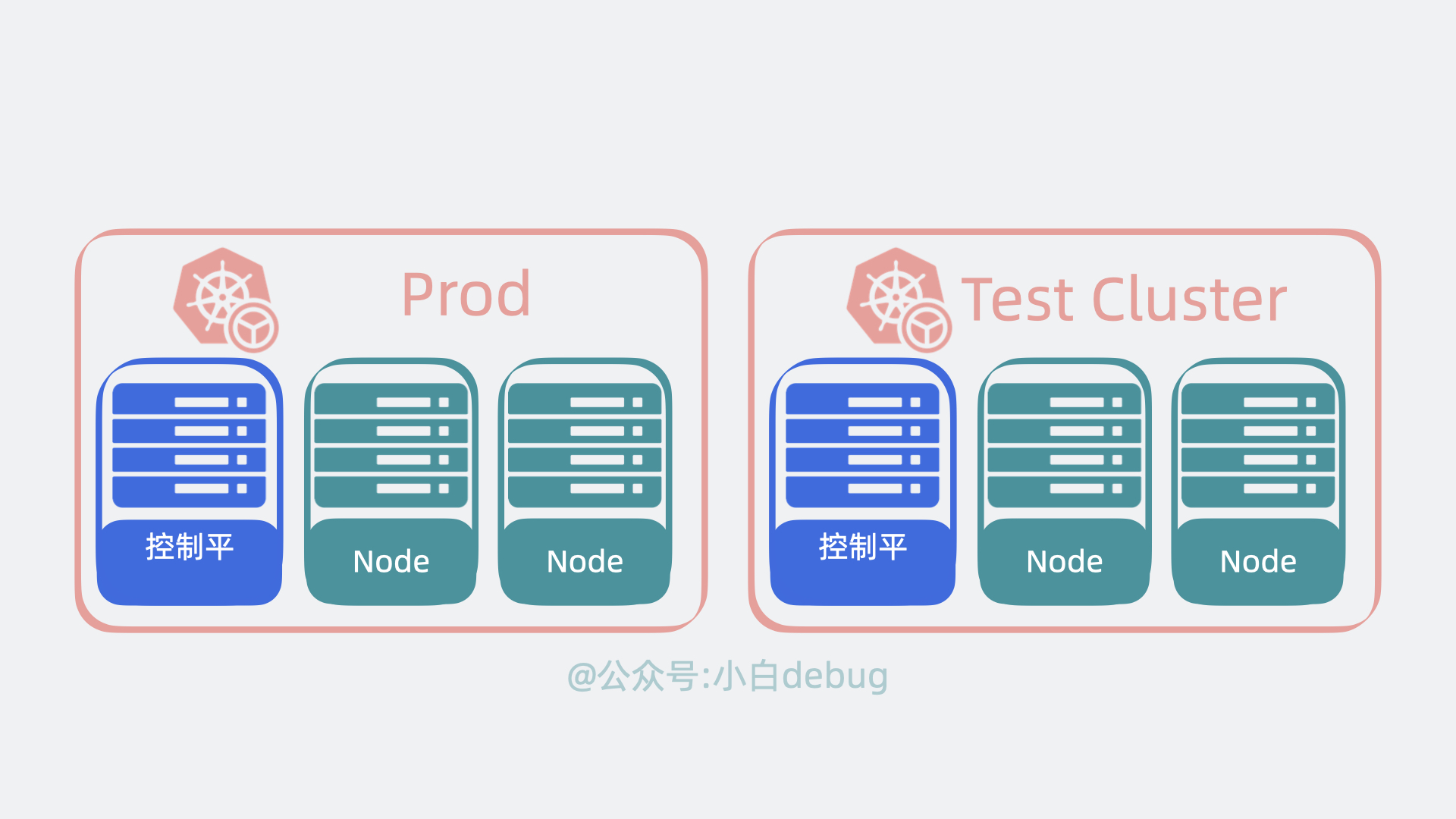
kubectl
上面提到说我们可以使用 k8s 提供的 API 去创建服务,但问题就来了,这是需要我们自己写代码去调用这些 API 吗?答案是不需要,k8s 为我们准备了一个命令行工具 kubectl,我们只需要执行命令,它内部就会调用 k8s 的 API。
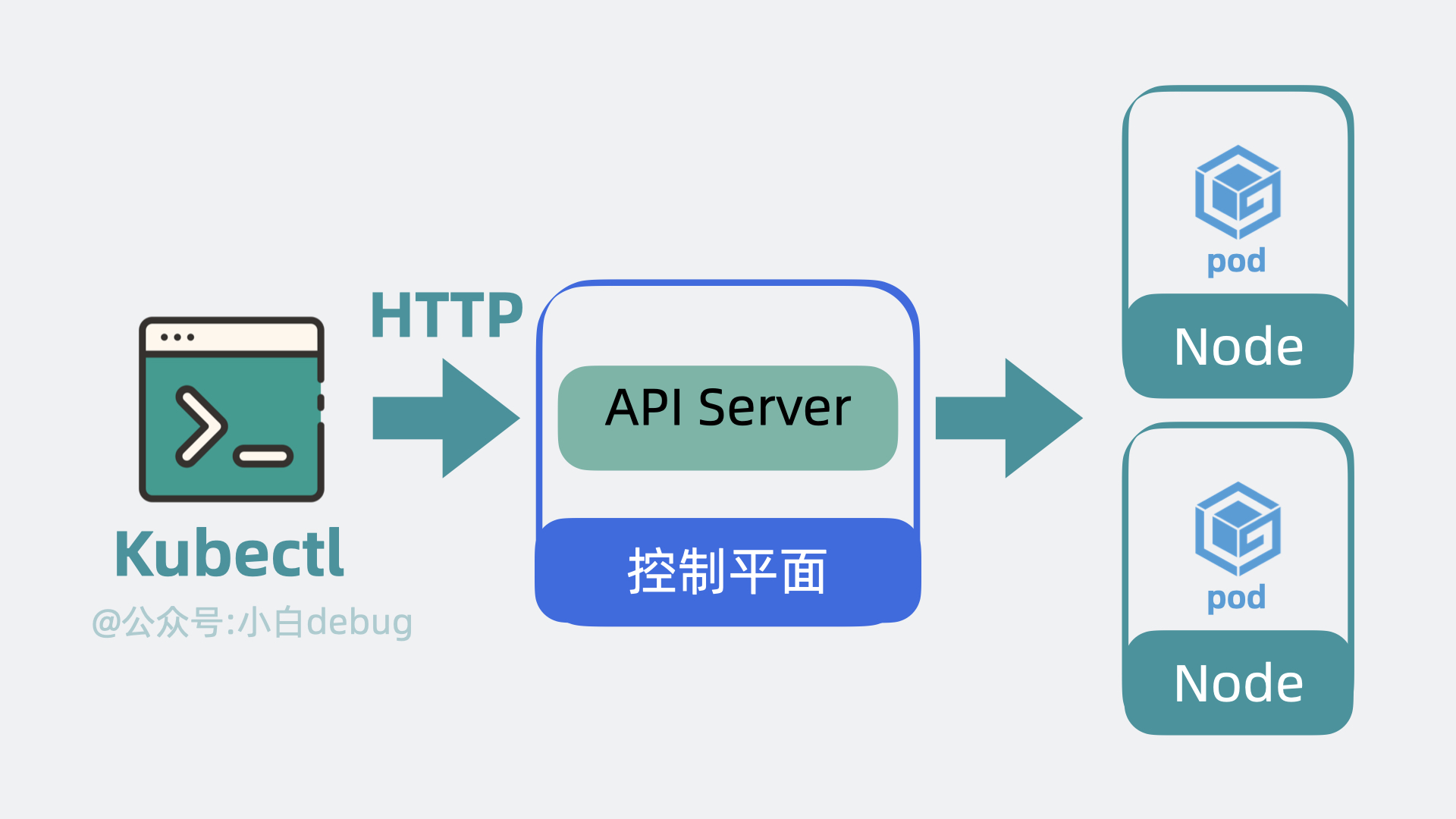
接下来我们以部署服务为例子,看下 k8s 是怎么工作的。
部署 Kubernetes 服务
首先我们需要编写 YAML 文件,在里面定义 Pod 里用到了哪些镜像,占用多少内存和 CPU 等信息。然后使用 kubectl 命令行工具执行 kubectl apply -f xx.yaml ,此时 kubectl 会读取和解析 YAML 文件,将解析后的对象通过 API 请求发送给 Kubernetes 控制平面内 的 API Server。API Server 会根据要求,驱使 Scheduler 通过 etcd 提供的数据寻找合适的 Node, Controller Manager 会通过 API Server 控制 Node 创建服务,Node 内部的 kubelet 在收到命令后会开始基于 Container runtime 组件去拉取镜像创建容器,最终完成 Pod 的创建。
至此服务完成创建。
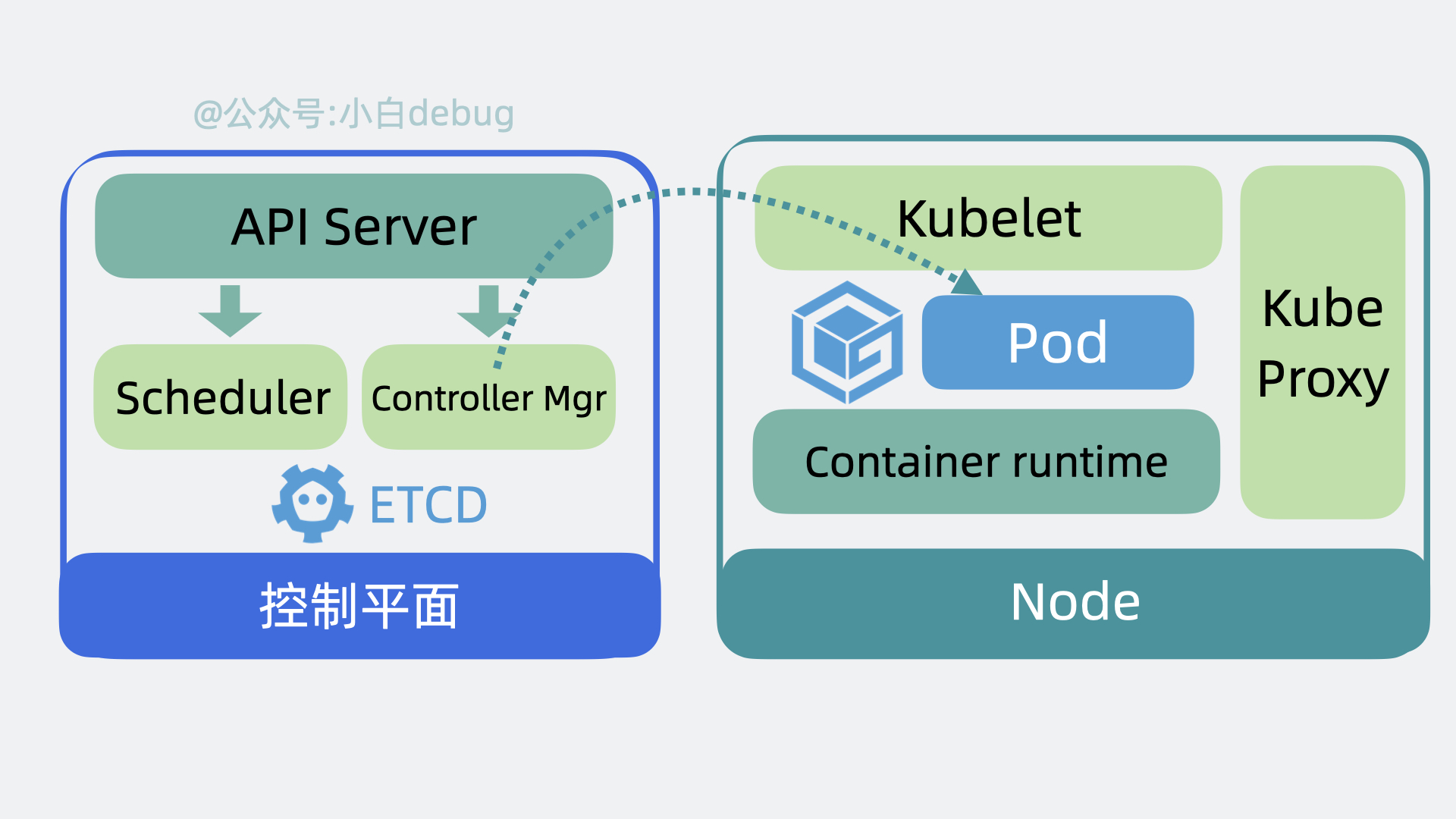
整个过程下来,我们只需要写一遍 yaml 文件,和执行一次 kubectl 命令,比以前省心太多了!部署完服务后,我们来看下服务是怎么被调用的。
调用 Kubernetes 服务
以前外部用户小明,直接在浏览器上发送 http 请求,就能打到我们服务器上的 Nginx,然后转发到部署的服务内。用了 k8s 之后,外部请求会先到达 Kubernetes 集群的 Ingress 控制器,然后请求会被转发到 Kubernetes 内部的某个 Node 的 Kube Proxy 上,再找到对应的 pod,然后才是转发到内部容器服务中,处理结果原路返回,到这就完成了一次服务调用。
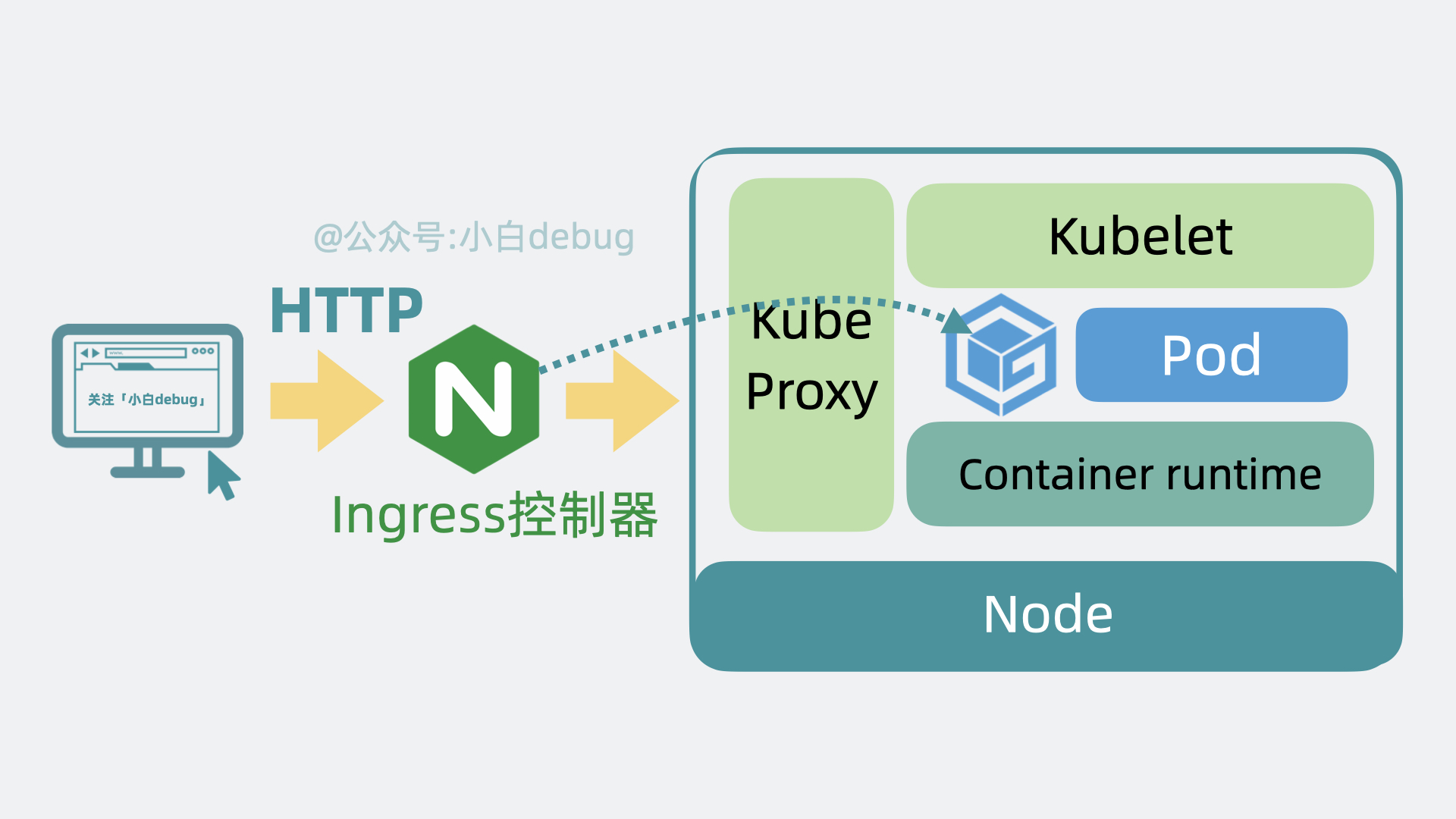
到这里我们就大概了解了 k8s 的工作原理啦,它本质上就是应用服务和服务器之间的中间层,通过暴露一系列 API 能力让我们简化服务的部署运维流程。
并且,不少中大厂基于这些 API 能力搭了自己的服务管理平台,程序员不再需要敲 kubectl 命令,直接在界面上点点几下,就能完成服务的部署和扩容等操作,是真的嘎嘎好用。