
vector(动态数组)
尾部添加,push_back()
#include <iostream>
#include <vector>
using namespace std;
int main(int argc, char *argv[]) {
vector<int> v;
int n;
cout<<"输入最大值n:"<<endl;
cin>>n;
for(int i=0;i<n;i++) {
v.push_back(i);
}
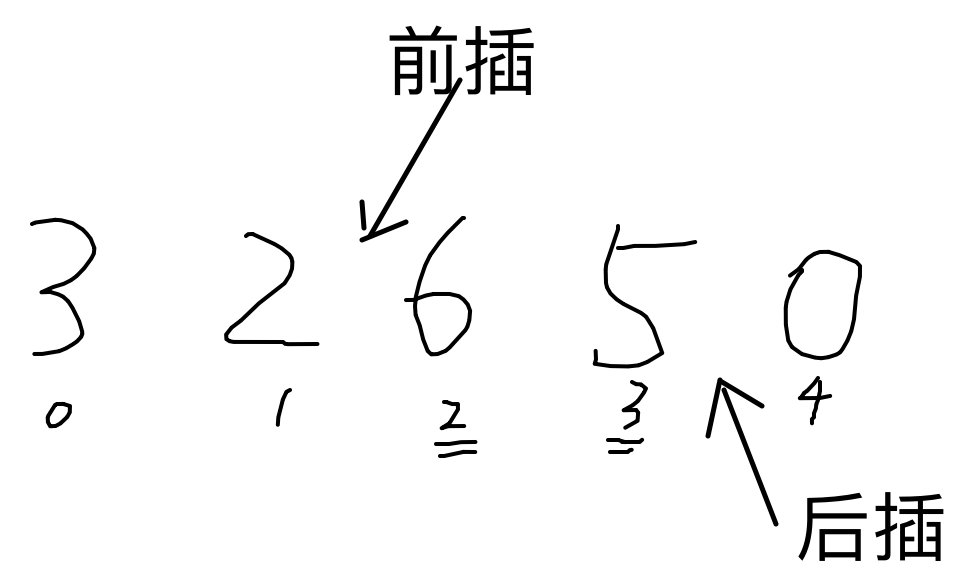
}中间插入(前插入&后插入),insert()
int main(int argc, char *argv[]) {
vector<int> v{3,2,6,5,0};
//begin返回指向容器第一个元素的迭代器
//begin+n 从下标0开始,在0+n下标的元素前面插入,begin就是在最前面插入
v.insert(v.begin()+2,111);//3 2 111 6 5 0
print_container1(v);
//end返回指向容器最后一个元素下一个位置的迭代器
//end + n 从最后一个元素开始,在倒数n个元素之前插入,end就是直接在最后插入
v.insert(v.end()-1,111);//3 2 6 5 111 0
print_container1(v);
} 中间删除,erase()
中间删除,erase()
v.erase(v.begin());//删除第一个数(下标为0)
v.erase(v.end());//删除最后一个数(下标为n-1)
v.erase(v.begin()+x,v.end()-y);//删除下标0+x~n-1-y的数
/*
思考:
vector<int> v = {0,1,2,3,4,5,6,7,8,9};
v.erase(v.begin()+2,v.end()-3);
结果:0 1 7 8 9
只保留了前2个数和后3个数。因此,v.erase(v.begin()+x,v.end()-y)的作用就是保留前x个数和后y个数的意思
*/erase实例:去除偶数
vector<int> k{0,1,2,3,4,5,6,7,8,9};
vector<int> tmp = k;//不破坏原数组
for(vector<int>::iterator it = tmp.begin();it!=tmp.end();){
if(*it%2==0){//*it是当前下标的数,it是指向当前位置数的迭代器(指针)
it = tmp.erase(it);//把当前位置的迭代器(指针)删除,就删除这个指针所指向的数,因此这个数就被删除了
}else{
it++;
}
}
print_container1(v);
/*结果:
1 3 5 7 9
*/数组长度&内存申请长度,size()&capacity()
//假设我往数组v中推了10个数
k.size();//10
k.capacity();//16
//假设我往数组v中推了33个数
k.size();//33
k.capacity();//64
//假设我往数组v中推了1025个数
k.size();//1025
k.capacity();//2048
/*
因此,不难得出结论,size()是数组真实的长度,capacity()是数组占用内存的长度
*/转置,reverse()
vector<int> v = {0,1,2,3,4,5,6,7,8,9};
reverse(v.begin()+2, v.end()-2);
for (int i=0 ;i<v.size(); i++) {
cout<<v[i]<<endl;
}
/*
结果:0 1 7 6 5 4 3 2 8 9
倒置的输入参数与insert同理,倒置的作用就是把范围内的数组颠倒了
*/排序,sort()
//自定义比较函数
bool Comp(const int &a,const int &b){
return a>b;
}
int main(int argc, char *argv[]) {
vector<int> v = {2,1,3,5,7,9,8,0,6,4};
sort(v.begin(), v.end());//默认升序:0 1 2 3 4 5 6 7 8 9
sort(v.begin(), v.end(),Comp);//降序:9 8 7 6 5 4 3 2 1 0
}字符串的输入
#include <iostream>
using namespace std;
int main(int argc, char *argv[]) {
string s1;
string s2;
char s[100];
scanf("%s",s);//scanf输入速度比cin快得多,但是scanf是C函数,不可以输入string
s1 = s;//因此需要用等号赋值给string(但是这个操作不好,用printf会报错,后面会说的)
cout<<s1<<endl;
cin>>s2;//但是用cin就方便很多
cout<<s2<<endl;
}string实例,求一个整数各位数的和
经常会遇到这样一种情况,有一个数字,需要把每一位给提取出来,如果用取余数的方法,花费的时间就会很长,所以可以当成字符串来处理,方便、省时。
#include<iostream>
#include<string>
using namespace std;
int main(int argc, char *argv[]) {
string s;
s = "123456789";
int sum = 0;
for(int i = 0; i < s.size(); ++i){
switch(s[i]){
case '1': sum += 1;break;
case '2': sum += 2;break;
case '3': sum += 3;break;
case '4': sum += 4;break;
case '5': sum += 5;break;
case '6': sum += 6;break;
case '7': sum += 7;break;
case '8': sum += 8;break;
case '9': sum += 9;break;
default:break;
}
}
cout << sum << endl;
return 0;
}
/*输出结果:
45
*/C语言的一些遗留问题,比如使用string类的自身方法c_str()去处理string和char*赋值问题,(这就是c++做得还不够好的地方)
#include<iostream>
#include<string>
#include<cstdio>//需要包含cstring的字符串的库
using namespace std;
int main(){
string s_string;
char s_char[1000];
scanf("%s",s_char);
s_string = s_char;
printf("s_string.c_str():%s\n", s_string.c_str());//printf输出char*时用c_str处理,c_str()函数返回一个指向正规C字符串的指针, 内容与本string串相同
cout<<"s_string:"<<s_string<<endl;
printf("s_char:%s\n",s_char);
cout<<"s_char:"<<s_char<<endl;
cout<<"s_string"<<s_string<<endl;
}查找,find()
以及⬇️
反向查找,rfind()
首次出现位置,find_first_of()
最后出现位置,find_last_of()
这些我就不细说了,用法都是一样的,都是返回一个下标
#include<cstring>
#include<cstdio>
#include<iostream>
using namespace std;
int main(int argc, char *argv[]) {
////find函数返回类型 size_type
string s = "1a2b3c4d5e6f7jkg8h9i1a2b3c4d5e6f7g8ha9i";
string flag;
string::size_type position;
//find函数返回“jk”在s中的下标位置
position = s.find("jk");
cout<<position<<endl;
if (position != s.npos){ //如果没找到,返回一个特别的标志c++中用npos表示,我这里npos取值是4294967295
printf("position is : %lu\n" ,position);
}else{
printf("Not found the flag\n");
}
}
/*
输出结果:
13
position:13
*/关于string::size_type 的理解:
在C++标准库类型 string ,在调用size函数求解string 对象时,返回值为size_type类型,一种类似于unsigned类型的int 数据。可以理解为一个与unsigned含义相同,且能足够大能存储任意string的类型。在C++ primer 中 提到 库类型一般定义了一些配套类型,通过配套类型,库类型就能与机器无关。我理解为 机器可以分为16位 32位64位等,如果利用int等内置类型,容易影响最后的结果,过大的数据可能丢失。
查找子串
position=s.find("b",5);//查找从某个位置之后第一次出现子串的位置查找所有子串出现的位置
//查找s 中flag 出现的所有位置。
string s("1a2b3c4d5e6f7jkg8h9i1a2b3c4d5e6f7g8ha9i");
flag="a";
position=0;
int i=1;
while((position=s.find(flag,position))!=string::npos){
cout<<"position"<<i<<":"<<position<<endl;
position++;
i++;
}
求和,accumulate()
#include <numeric>
//起始位置,结束位置,起始累加值(一般都是从0开始吧)
accumulate(v.begin(),v.end(),0);vector数组的3种遍历方法,我写了三个都挺好用的,可以适当修改一下输出格式
void print_container1(vector<int> vec){
for(vector<int>::iterator it = vec.begin();it!=vec.end();it++){
cout<<*it<<endl;
}
}
void print_container2(vector<int> vec){
vector<int>::iterator it = vec.begin();
while(it!=vec.end()) {
cout<<*it<<endl;
it++;
}
}
void print_container3(vector<int> vec){
for(int i=0;i<vec.size();i++){
cout<<vec[i]<<endl;
}
}set容器
set是用红黑树的平衡二叉索引树的数据结构来实现的,插入时,它会自动调节二叉树排列,把元素放到适合的位置,确保每个子树根节点的键值大于左子树所有的值、小于右子树所有的值,插入重复数据时会忽略。set迭代器采用中序遍历,检索效率高于vector、deque、list,并且会将元素按照升序的序列遍历。set容器中的数值,一经更改,set会根据新值旋转二叉树,以保证平衡,构建set就是为了快速检索。
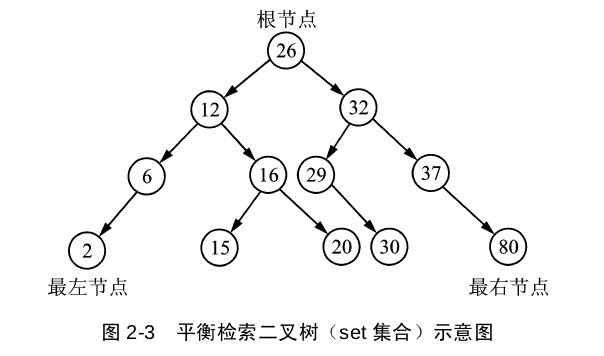
multiset,与set不同之处就是它允许有重复的键值。
#include<iostream>
#include<set>
using namespace std;
int main(int argc, char *argv[]) {
set<int> v;
v.insert(1);//边插边排序
v.insert(3);
v.insert(5);
v.insert(2);
v.insert(4);
v.insert(3);//会被忽略
//中序遍历 升序遍历
for(set<int>::iterator it = v.begin(); it != v.end(); ++it){
cout<<*it<<" ";
}
for(set<int>::reverse_iterator rit = v.rbegin(); rit != v.rend(); ++rit){
cout<<*rit<<" ";
}
}
/*结果:
1 2 3 4 5 //升序iterator
5 4 3 2 1 //降序reverse_iterator
*/自定义比较函数,insert的时候,set会使用默认的比较函数(升序),很多情况下需要自己编写比较函数。
1、如果元素不是结构体,可以编写比较函数,下面这个例子是用降序排列的(和上例插入数据相同):
#include<iostream>
#include<set>
using namespace std;
struct Comp{
//重载()
bool operator()(const int &a, const int &b){
return a > b;
}
};
int main(int argc, char *argv[]) {
set<int> v;
v.insert(1);
v.insert(3);
v.insert(5);
v.insert(2);
v.insert(4);
v.insert(3);
for(set<int,Comp>::iterator it = v.begin(); it != v.end(); ++it){
cout << *it << " ";
}
cout << endl;
for(set<int,Comp>::reverse_iterator rit = v.rbegin(); rit != v.rend(); ++rit){
cout << *rit << " ";
}
cout << endl;
}
/*结果://这个之前的正好相反
5 4 3 2 1
1 2 3 4 5
*/2、元素本身就是结构体,直接把比较函数写在结构体内部,下面的例子依然降序:
#include<iostream>
#include<set>
#include<string>
using namespace std;
struct Info{
string name;
double score;
//重载 <
bool operator < (const Info &a) const{
return a.score < score;
}
};
int main(int argc, char *argv[]) {
set<Info> s;
Info info;
info.name = "abc";
info.score = 123.3;
s.insert(info);
info.name = "EDF";
info.score = -23.53;
s.insert(info);
info.name = "xyz";
info.score = 73.3;
s.insert(info);
for(set<Info>::iterator it = s.begin(); it != s.end(); ++it){
cout<<(*it).name<<":"<<(*it).score<<endl;
}
cout << endl;
for(set<Info>::reverse_iterator rit = s.rbegin(); rit != s.rend(); ++rit){
cout<<(*rit).name<<":"<<(*rit).score<<endl;
}
cout << endl;
}
/*
abc:123.3
xyz:73.3
EDF:-23.53
EDF:-23.53
xyz:73.3
abc:123.3
*/multiset与set的不同之处就是key可以重复,以及erase(key)的时候会删除multiset里面所有的key并且返回删除的个数。
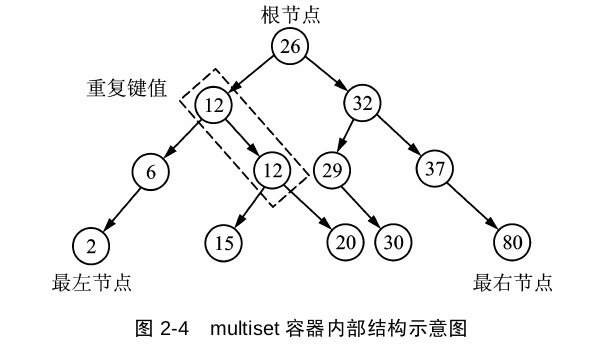
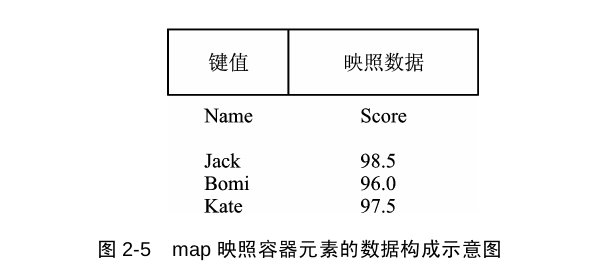
map容器
map也是使用红黑树,他是一个键值对(key:value映射),遍历时依然默认按照key程序的方式遍历,同set。
#include<iostream>
#include<map>
#include<string>
using namespace std;
int main(int argc, char *argv[]){
map<string,double> m;
//声明即插入
m["li"] = 123.4;
m["wang"] = 23.1;
m["zhang"] = -21.9;
m["abc"] = 12.1;
for(map<string,double>::iterator it = m.begin(); it != m.end(); ++it){
//first --> key second --> value
cout << (*it).first << ":" << (*it).second << endl;
}
cout << endl;
}
/*结果:
abc:12.1
li:123.4
wang:23.1
zhang:-21.9
*/multimap
multimap由于允许有重复的元素,所以元素插入、删除、查找都与map不同。
插入insert(pair<a,b>(value1,value2)),至于删除和查找,erase(key)会删除掉所有key的map,查找find(key)返回第一个key的迭代器
#include <iostream>
#include <map>
#include <string>
using namespace std;
int main(int argc, char *argv[]) {
multimap<string,double> m;
m.insert(pair<string,double>("Abc",123.2));
m.insert(pair<string,double>("Abc",123.2));
m.insert(pair<string,double>("xyz",-43.2));
m.insert(pair<string,double>("dew",43.2));
for(multimap<string,double>::iterator it = m.begin(); it != m.end(); ++it ){
cout << (*it).first << ":" << (*it).second << endl;
}
cout << endl;
}
/*结果:
Abc:123.2
Abc:123.2
dew:43.2
xyz:-43.2
*/deque
deque和vector一样,采用线性表,与vector唯一不同的是,deque采用的分块的线性存储结构,每块大小一般为512字节,称为一个deque块,所有的deque块使用一个Map块进行管理,每个map数据项记录各个deque块的首地址,这样以来,deque块在头部和尾部都可已插入和删除元素,而不需要移动其它元素。
使用push_back()方法在尾部插入元素,
使用push_front()方法在首部插入元素,
使用insert()方法在中间插入元素。
一般来说,当考虑容器元素的内存分配策略和操作的性能时,deque相对vectore更有优势。
(下面这个图,我感觉Map块就是一个list< map<deque名字,deque地址> >)
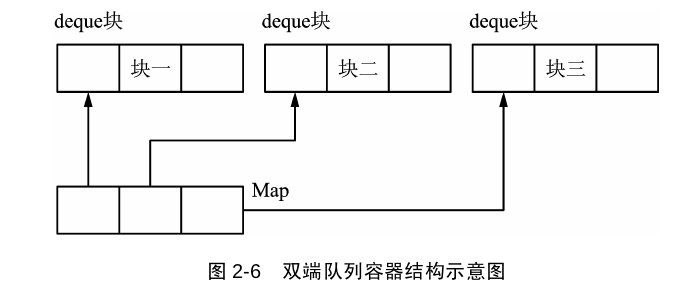
deque的一些操作
#include <iostream>
#include <deque>
using namespace std;
int main(int argc, char *argv[]) {
deque<int> d;
//尾部插入
d.push_back(1);
d.push_back(3);
d.push_back(2);
//头部插入
d.push_front(10);
d.push_front(-23);
//中间插入
d.insert(d.begin() + 2,9999);
//清空
d.clear();
//从头部删除元素
d.pop_front();
//从尾部删除元素
d.pop_back();
//中间删除
d.erase(d.begin()+2,d.end()-5);
//正方向遍历
for(deque<int>::iterator it = d.begin(); it != d.end(); ++it ){
cout << (*it) << " ";
}
cout << endl << endl;
//反方向遍历
for(deque<int>::reverse_iterator rit = d.rbegin(); rit != d.rend(); ++rit ){
cout << (*rit) << " ";
}
cout << endl << endl;
}list(双向链表)
双向链表,常见的一种线性表,简单讲一下吧
插入:push_back尾部,push_front头部,insert方法前往迭代器位置处插入元素,链表自动扩张,迭代器只能使用++--操作,不能用+n -n,因为元素不是物理相连的。
遍历:iterator和reverse_iterator正反遍历
删除:pop_front删除链表首元素;pop_back()删除链表尾部元素;erase(迭代器)删除迭代器位置的元素,注意只能使用++--到达想删除的位置;remove(key) 删除链表中所有key的元素,clear()清空链表。
查找:it = find(l.begin(),l.end(),key)
排序:l.sort()
删除连续重复元素:l.unique() 【2 8 1 1 1 5 1】 --> 【 2 8 1 5 1】
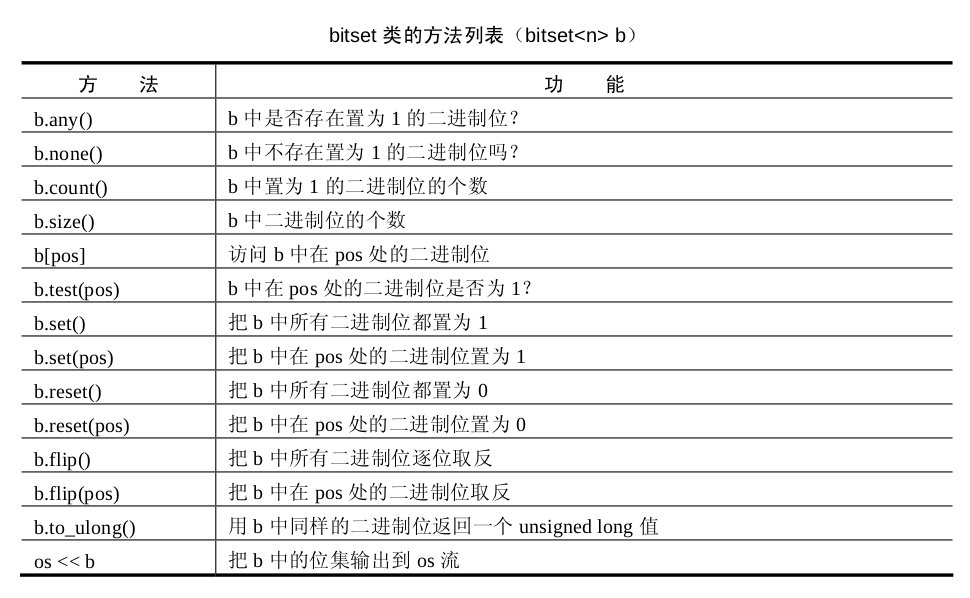
bitset
很少用到的容器,随便过一下

queue(栈)
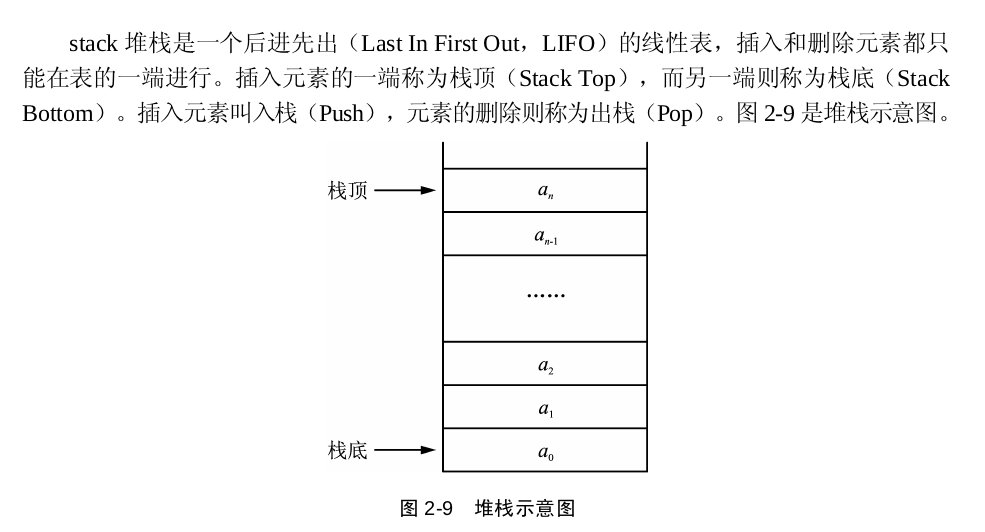
#include <iostream>
#include <stack>
using namespace std;
int main(int argc, char *argv[]){
stack<int> s;
s.push(1);
s.push(2);
s.push(4);
s.push(5);
cout<<"s.size():"<<s.size()<<endl;
while(!s.empty()){
cout<<s.top()<<endl;
s.pop();
}
}
/*结果:
s.size():4
5
4
2
1
*/queue(队列)
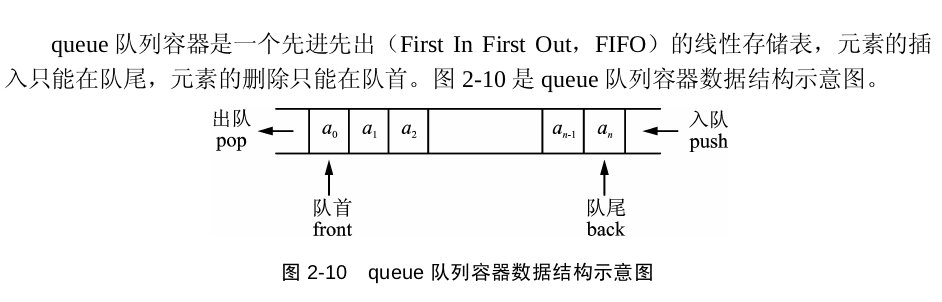
queue有入队push(插入)、出队pop(删除)、读取队首元素front、读取队尾元素back、empty,size这几种方法,不多说了
priority_queue(优先队列)

#include <iostream>
#include <queue>
using namespace std;
int main(int argc, char *argv[]) {
priority_queue<int> pq;
pq.push(1);
pq.push(3);
pq.push(2);
pq.push(8);
pq.push(9);
pq.push(0);
cout<<"pq.size:"<<pq.size()<<endl;
while(pq.empty() != true){
cout << pq.top() << endl;
pq.pop();
}
}
/*结果:
pq.size:6
9
8
3
2
1
0
*/重载操作符同set重载操作符