
起因
最近在冲浪的时候看到了有人在分享Ollama的部署和使用体验,于是我也去官网下载体验了一下:ollama官网
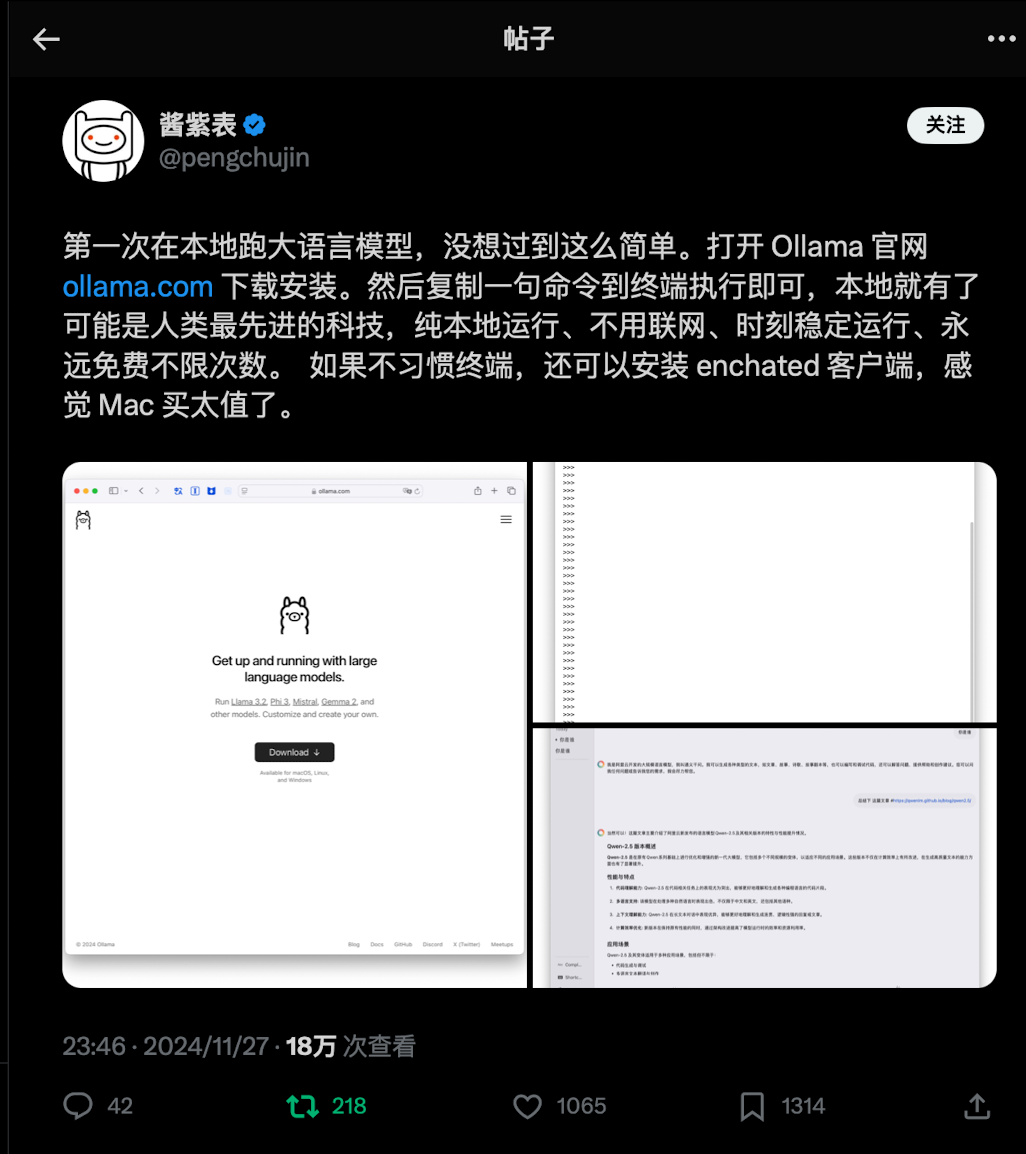
下载非常简单,一路到底,然后安装一个大语言模型即可,我选择了最新的llama
shell
ollama run llama3.2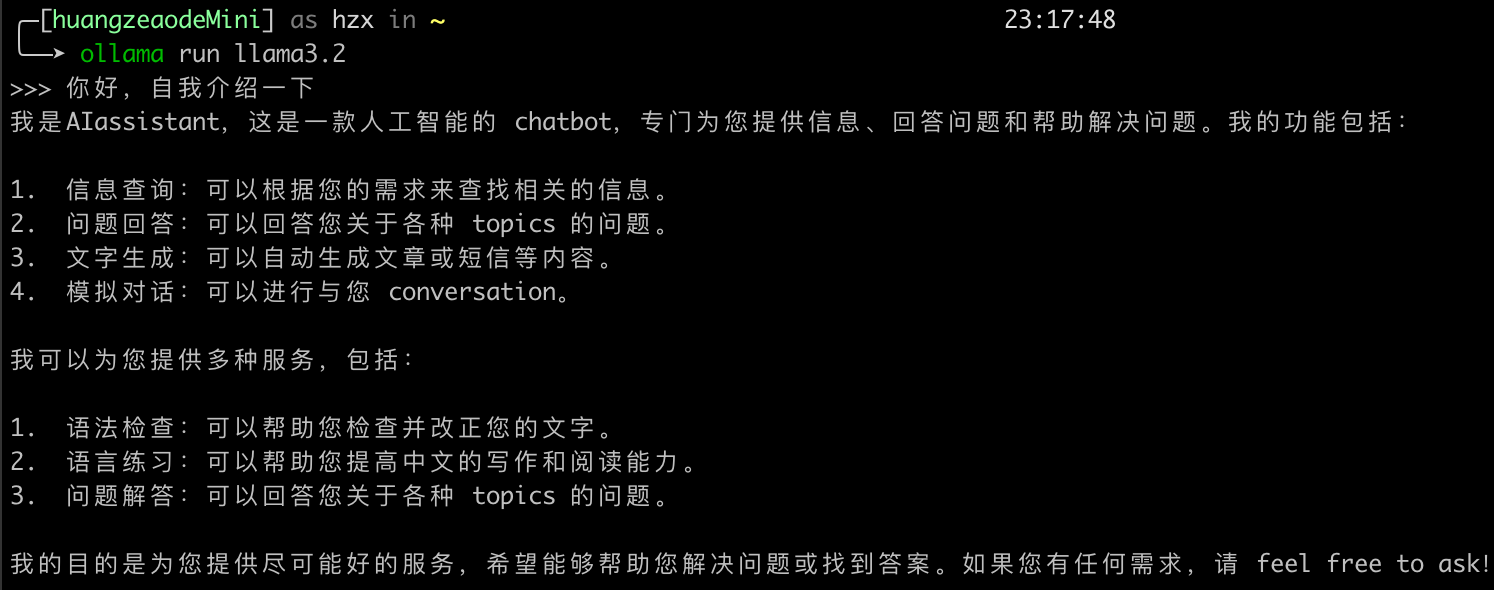
看起来挺简单的,但是我发现这个应用非常占内存!我16g的mac mini开始swap了!
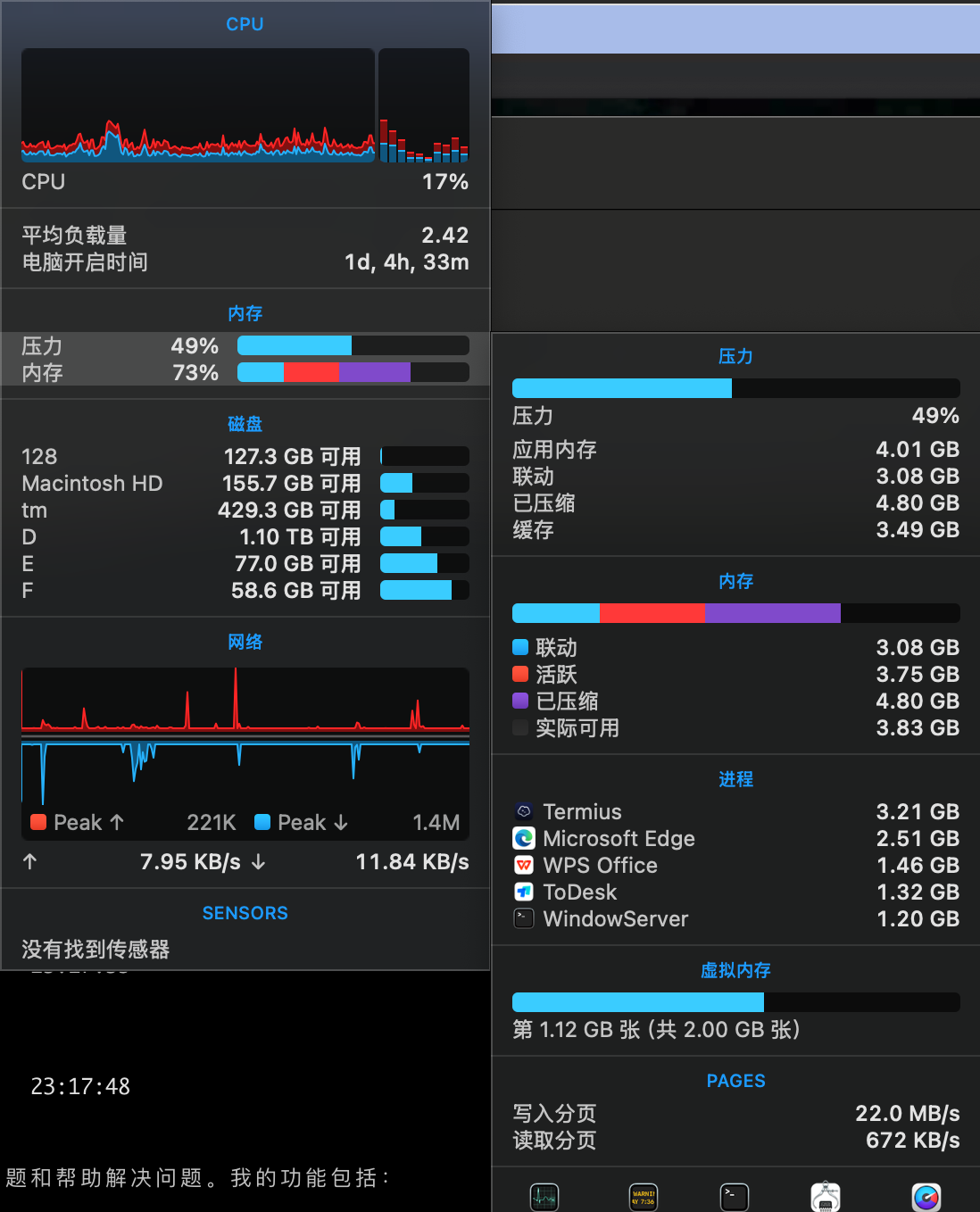
正好我手头有一台windows作为服务器,所以便开始折腾服务远程调用……
远程调用Ollama模型
客户端软件
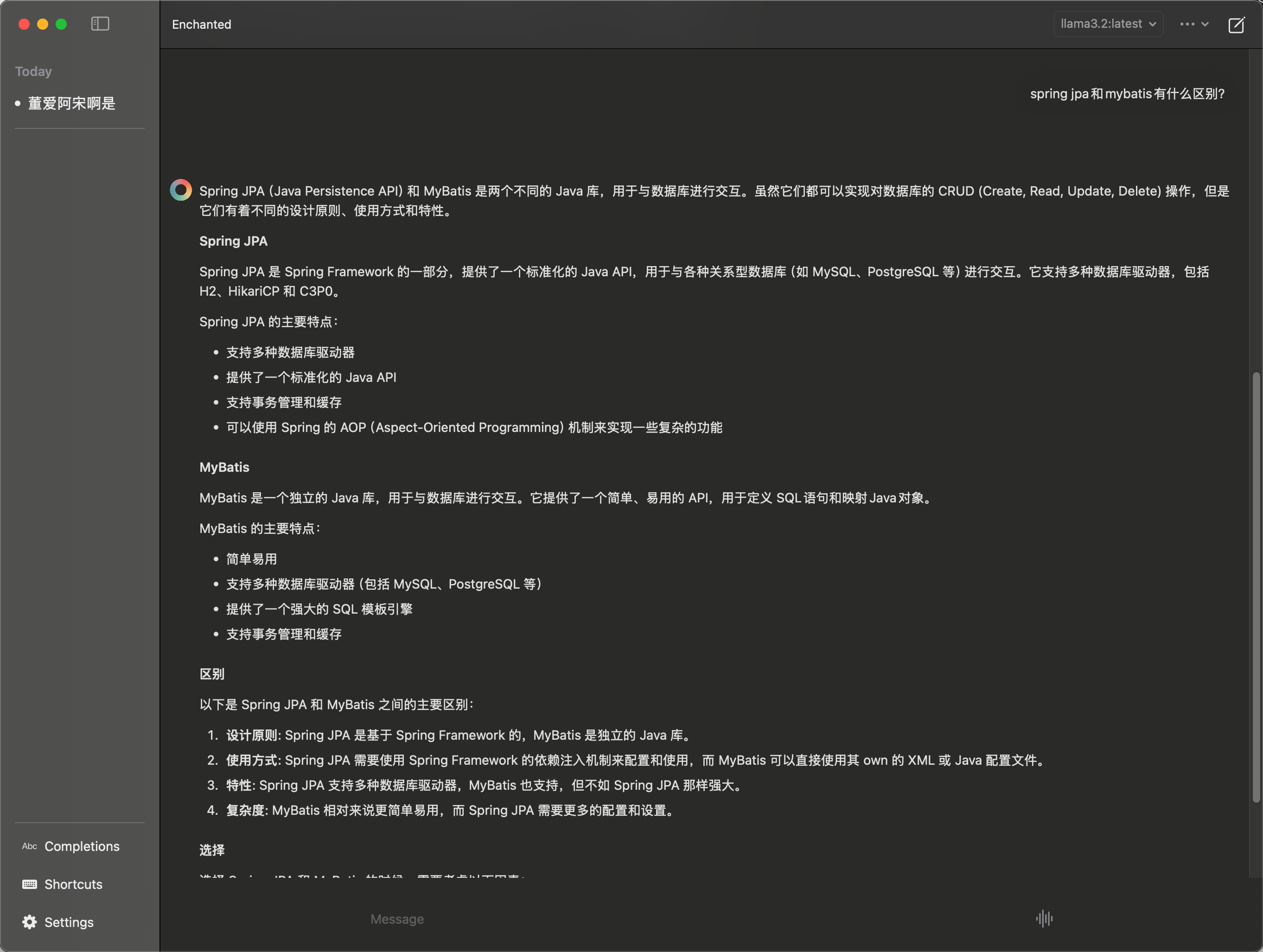
因为要在mac上使用,所以我选择用Enchanted这款软件,在AppStore里也能下载到,非常好用,支持本地Ollama、远程调用、api调用,功能强大,界面美观。
服务端配置
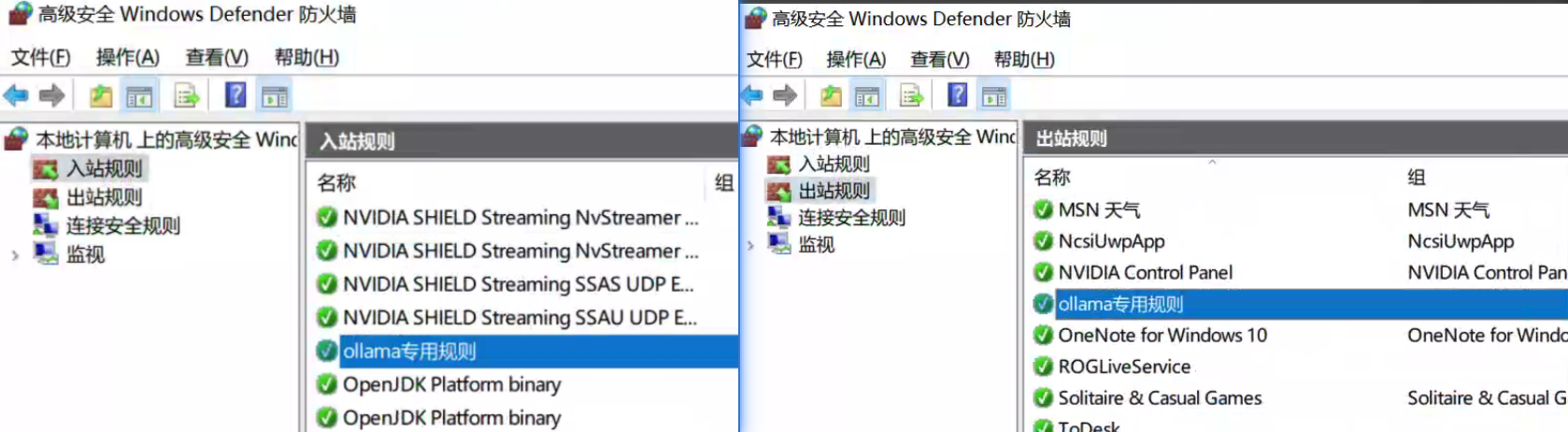
在服务端,我同样下载了Ollama,并开启了防火墙的11434端口:
测试、调用
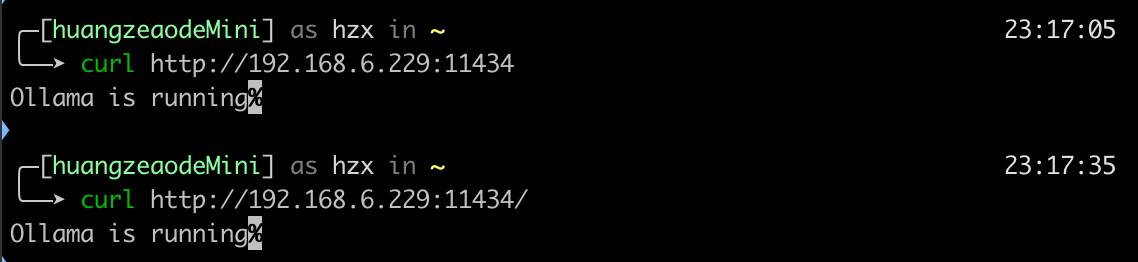
然后在mac上用telnet命令测试能否访问11434端口,发现一直显示Trying 192.168.6.229...,于是改用curl测试,发现可以访问,且因为Enchanted上有一个轮询的机制,所以并不难确认能否访问到端口:
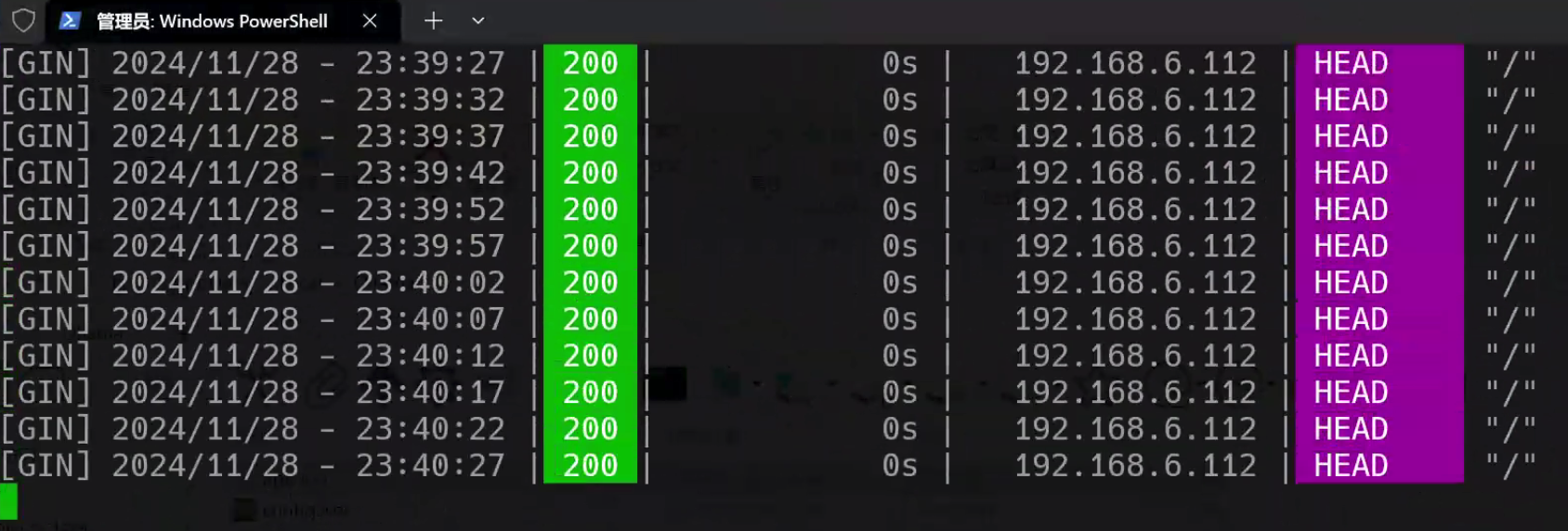
ok,至此就完成了,现在windows作为server端,mac作为client端,这样一个本地大模型就部署好了!