vector(动态数组)
尾部添加,push_back()
1 2 3 4 5 6 7 8 9 10 11 12 13 #include <iostream> #include <vector> using namespace std;int main (int argc, char *argv[]) vector<int > v; int n; cout<<"输入最大值n:" <<endl; cin>>n; for (int i=0 ;i<n;i++) { v.push_back (i); } }
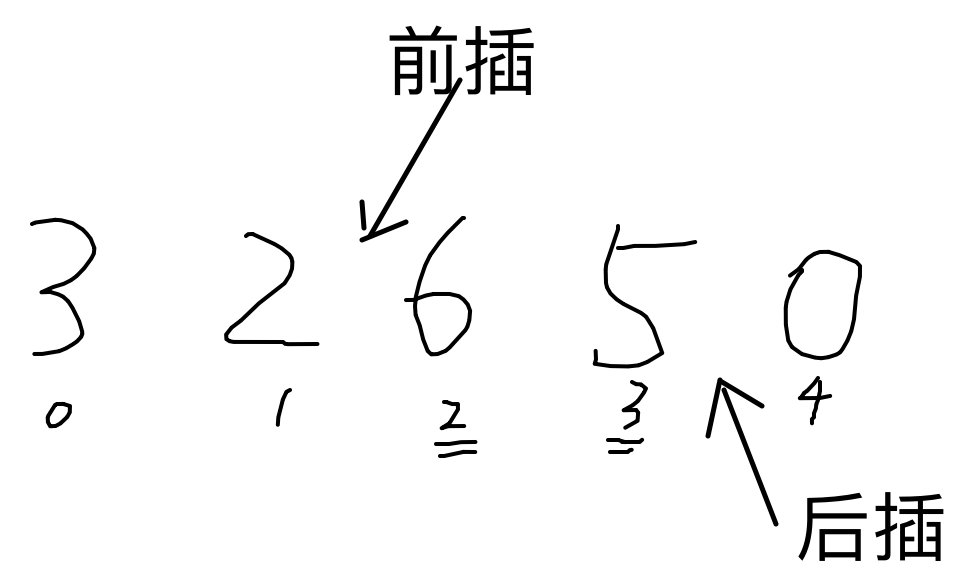
中间插入(前插入&后插入),insert()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 int main (int argc, char *argv[]) vector<int > v{3 ,2 ,6 ,5 ,0 }; v.insert (v.begin ()+2 ,111 ); print_container1 (v); v.insert (v.end ()-1 ,111 ); print_container1 (v); }
1 2 3 4 5 6 7 8 9 10 11 12 13 v.erase (v.begin ()); v.erase (v.end ()); v.erase (v.begin ()+x,v.end ()-y);
erase实例:去除偶数
1 2 3 4 5 6 7 8 9 10 11 12 13 vector<int > k{0 ,1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 ,9 }; vector<int > tmp = k; for (vector<int >::iterator it = tmp.begin ();it!=tmp.end ();){ if (*it%2 ==0 ){ it = tmp.erase (it); }else { it++; } } print_container1 (v);
数组长度&内存申请长度,size()&capacity()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 k.size (); k.capacity (); k.size (); k.capacity (); k.size (); k.capacity ();
转置,reverse()
1 2 3 4 5 6 7 8 9 vector<int > v = {0 ,1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 ,9 }; reverse (v.begin ()+2 , v.end ()-2 );for (int i=0 ;i<v.size (); i++) { cout<<v[i]<<endl; }
排序,sort()
1 2 3 4 5 6 7 8 9 bool Comp (const int &a,const int &b) return a>b; } int main (int argc, char *argv[]) vector<int > v = {2 ,1 ,3 ,5 ,7 ,9 ,8 ,0 ,6 ,4 }; sort (v.begin (), v.end ()); sort (v.begin (), v.end (),Comp); }
字符串的输入
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #include <iostream> using namespace std;int main (int argc, char *argv[]) string s1; string s2; char s[100 ]; scanf ("%s" ,s); s1 = s; cout<<s1<<endl; cin>>s2; cout<<s2<<endl; }
string实例,求一个整数各位数的和
经常会遇到这样一种情况,有一个数字,需要把每一位给提取出来,如果用取余数的方法,花费的时间就会很长,所以可以当成字符串来处理,方便、省时。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #include <iostream> #include <string> using namespace std;int main (int argc, char *argv[]) string s; s = "123456789" ; int sum = 0 ; for (int i = 0 ; i < s.size (); ++i){ switch (s[i]){ case '1' : sum += 1 ;break ; case '2' : sum += 2 ;break ; case '3' : sum += 3 ;break ; case '4' : sum += 4 ;break ; case '5' : sum += 5 ;break ; case '6' : sum += 6 ;break ; case '7' : sum += 7 ;break ; case '8' : sum += 8 ;break ; case '9' : sum += 9 ;break ; default :break ; } } cout << sum << endl; return 0 ; }
C语言的一些遗留问题,比如使用string类的自身方法c_str()去处理string和char*赋值问题,(这就是c++做得还不够好的地方)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #include <iostream> #include <string> #include <cstdio> using namespace std;int main () string s_string; char s_char[1000 ]; scanf ("%s" ,s_char); s_string = s_char; printf ("s_string.c_str():%s\n" , s_string.c_str ()); cout<<"s_string:" <<s_string<<endl; printf ("s_char:%s\n" ,s_char); cout<<"s_char:" <<s_char<<endl; cout<<"s_string" <<s_string<<endl; }
查找,find()
以及⬇️
反向查找,rfind()
首次出现位置,find_first_of()
最后出现位置,find_last_of()
这些我就不细说了,用法都是一样的,都是返回一个下标
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #include <cstring> #include <cstdio> #include <iostream> using namespace std;int main (int argc, char *argv[]) string s = "1a2b3c4d5e6f7jkg8h9i1a2b3c4d5e6f7g8ha9i" ; string flag; string::size_type position; position = s.find ("jk" ); cout<<position<<endl; if (position != s.npos){ printf ("position is : %lu\n" ,position); }else { printf ("Not found the flag\n" ); } }
关于string::size_type 的理解:
在C++标准库类型 string ,在调用size函数求解string 对象时,返回值为size_type类型,一种类似于unsigned类型的int 数据。可以理解为一个与unsigned含义相同,且能足够大能存储任意string的类型。在C++ primer 中 提到 库类型一般定义了一些配套类型,通过配套类型,库类型就能与机器无关。我理解为 机器可以分为16位 32位64位等,如果利用int等内置类型,容易影响最后的结果,过大的数据可能丢失。
string::size_type 的理解_nibiebiwo的博客-CSDN博客
查找子串
查找所有子串出现的位置
1 2 3 4 5 6 7 8 9 10 string s ("1a2b3c4d5e6f7jkg8h9i1a2b3c4d5e6f7g8ha9i" ) ;flag="a" ; position=0 ; int i=1 ;while ((position=s.find (flag,position))!=string::npos){ cout<<"position" <<i<<":" <<position<<endl; position++; i++; }
求和,accumulate()
1 2 3 #include <numeric> accumulate (v.begin (),v.end (),0 );
vector数组的3种遍历方法,我写了三个都挺好用的,可以适当修改一下输出格式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 void print_container1 (vector<int > vec) for (vector<int >::iterator it = vec.begin ();it!=vec.end ();it++){ cout<<*it<<endl; } } void print_container2 (vector<int > vec) vector<int >::iterator it = vec.begin (); while (it!=vec.end ()) { cout<<*it<<endl; it++; } } void print_container3 (vector<int > vec) for (int i=0 ;i<vec.size ();i++){ cout<<vec[i]<<endl; } }
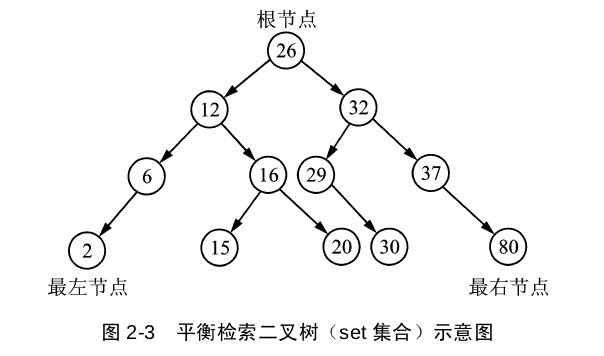
set容器
set是用红黑树的平衡二叉索引树的数据结构来实现的,插入时,它会自动调节二叉树排列,把元素放到适合的位置,确保每个子树根节点的键值大于左子树所有的值、小于右子树所有的值,插入重复数据时会忽略。set迭代器采用中序遍历,检索效率高于vector、deque、list,并且会将元素按照升序的序列遍历。set容器中的数值,一经更改,set会根据新值旋转二叉树,以保证平衡,构建set就是为了快速检索。
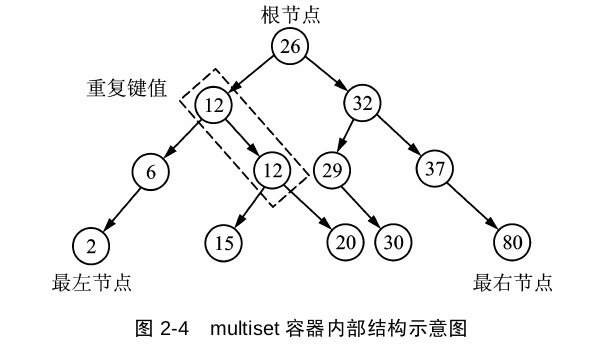
multiset,与set不同之处就是它允许有重复的键值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 #include <iostream> #include <set> using namespace std;int main (int argc, char *argv[]) set<int > v; v.insert (1 ); v.insert (3 ); v.insert (5 ); v.insert (2 ); v.insert (4 ); v.insert (3 ); for (set<int >::iterator it = v.begin (); it != v.end (); ++it){ cout<<*it<<" " ; } for (set<int >::reverse_iterator rit = v.rbegin (); rit != v.rend (); ++rit){ cout<<*rit<<" " ; } }
自定义比较函数,insert的时候,set会使用默认的比较函数(升序),很多情况下需要自己编写比较函数。
1、如果元素不是结构体,可以编写比较函数,下面这个例子是用降序排列的(和上例插入数据相同):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #include <iostream> #include <set> using namespace std;struct Comp { bool operator () (const int &a, const int &b) return a > b; } }; int main (int argc, char *argv[]) set<int > v; v.insert (1 ); v.insert (3 ); v.insert (5 ); v.insert (2 ); v.insert (4 ); v.insert (3 ); for (set<int ,Comp>::iterator it = v.begin (); it != v.end (); ++it){ cout << *it << " " ; } cout << endl; for (set<int ,Comp>::reverse_iterator rit = v.rbegin (); rit != v.rend (); ++rit){ cout << *rit << " " ; } cout << endl; }
2、元素本身就是结构体,直接把比较函数写在结构体内部,下面的例子依然降序:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 #include <iostream> #include <set> #include <string> using namespace std;struct Info { string name; double score; bool operator < (const Info &a) const { return a.score < score; } }; int main (int argc, char *argv[]) set<Info> s; Info info; info.name = "abc" ; info.score = 123.3 ; s.insert (info); info.name = "EDF" ; info.score = -23.53 ; s.insert (info); info.name = "xyz" ; info.score = 73.3 ; s.insert (info); for (set<Info>::iterator it = s.begin (); it != s.end (); ++it){ cout<<(*it).name<<":" <<(*it).score<<endl; } cout << endl; for (set<Info>::reverse_iterator rit = s.rbegin (); rit != s.rend (); ++rit){ cout<<(*rit).name<<":" <<(*rit).score<<endl; } cout << endl; }
multiset与set的不同之处就是key可以重复,以及erase(key)的时候会删除multiset里面所有的key并且返回删除的个数。
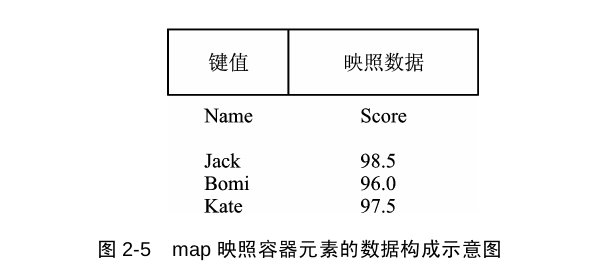
map容器
map也是使用红黑树,他是一个键值对(key:value映射),遍历时依然默认按照key程序的方式遍历,同set。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #include <iostream> #include <map> #include <string> using namespace std;int main (int argc, char *argv[]) map<string,double > m; m["li" ] = 123.4 ; m["wang" ] = 23.1 ; m["zhang" ] = -21.9 ; m["abc" ] = 12.1 ; for (map<string,double >::iterator it = m.begin (); it != m.end (); ++it){ cout << (*it).first << ":" << (*it).second << endl; } cout << endl; }
multimap
multimap由于允许有重复的元素,所以元素插入、删除、查找都与map不同。
插入insert(pair<a,b>(value1,value2)),至于删除和查找,erase(key)会删除掉所有key的map,查找find(key)返回第一个key的迭代器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 #include <iostream> #include <map> #include <string> using namespace std;int main (int argc, char *argv[]) multimap<string,double > m; m.insert (pair <string,double >("Abc" ,123.2 )); m.insert (pair <string,double >("Abc" ,123.2 )); m.insert (pair <string,double >("xyz" ,-43.2 )); m.insert (pair <string,double >("dew" ,43.2 )); for (multimap<string,double >::iterator it = m.begin (); it != m.end (); ++it ){ cout << (*it).first << ":" << (*it).second << endl; } cout << endl; }
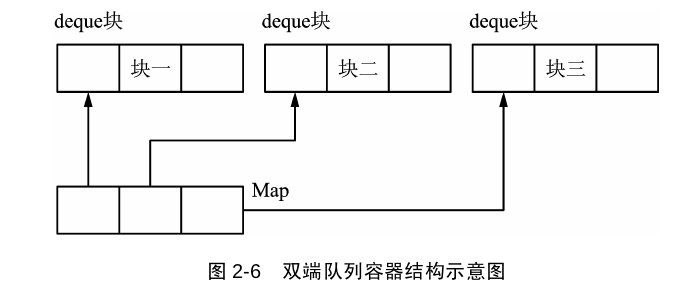
deque
deque和vector一样,采用线性表,与vector唯一不同的是,deque采用的分块的线性存储结构,每块大小一般为512字节,称为一个deque块,所有的deque块使用一个Map块进行管理,每个map数据项记录各个deque块的首地址,这样以来,deque块在头部和尾部都可已插入和删除元素,而不需要移动其它元素。
使用push_back()方法在尾部插入元素,
使用push_front()方法在首部插入元素,
使用insert()方法在中间插入元素。
一般来说,当考虑容器元素的内存分配策略和操作的性能时,deque相对vectore更有优势。
(下面这个图,我感觉Map块就是一个list< map<deque名字,deque地址> >)
deque的一些操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 #include <iostream> #include <deque> using namespace std;int main (int argc, char *argv[]) deque<int > d; d.push_back (1 ); d.push_back (3 ); d.push_back (2 ); d.push_front (10 ); d.push_front (-23 ); d.insert (d.begin () + 2 ,9999 ); d.clear (); d.pop_front (); d.pop_back (); d.erase (d.begin ()+2 ,d.end ()-5 ); for (deque<int >::iterator it = d.begin (); it != d.end (); ++it ){ cout << (*it) << " " ; } cout << endl << endl; for (deque<int >::reverse_iterator rit = d.rbegin (); rit != d.rend (); ++rit ){ cout << (*rit) << " " ; } cout << endl << endl; }
list(双向链表)
双向链表,常见的一种线性表,简单讲一下吧
插入:push_back尾部,push_front头部,insert方法前往迭代器位置处插入元素,链表自动扩张,迭代器只能使用++–操作,不能用+n -n,因为元素不是物理相连的。
遍历:iterator和reverse_iterator正反遍历
删除:pop_front删除链表首元素;pop_back()删除链表尾部元素;erase(迭代器)删除迭代器位置的元素,注意只能使用++–到达想删除的位置;remove(key) 删除链表中所有key的元素,clear()清空链表。
查找:it = find(l.begin(),l.end(),key)
排序:l.sort()
删除连续重复元素:l.unique() 【2 8 1 1 1 5 1】 –> 【 2 8 1 5 1】
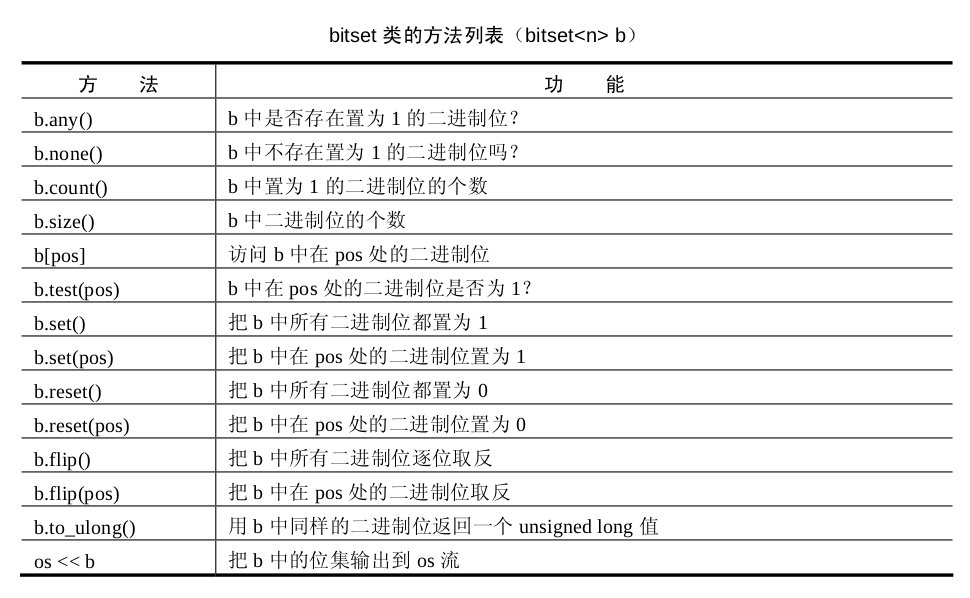
bitset
很少用到的容器,随便过一下
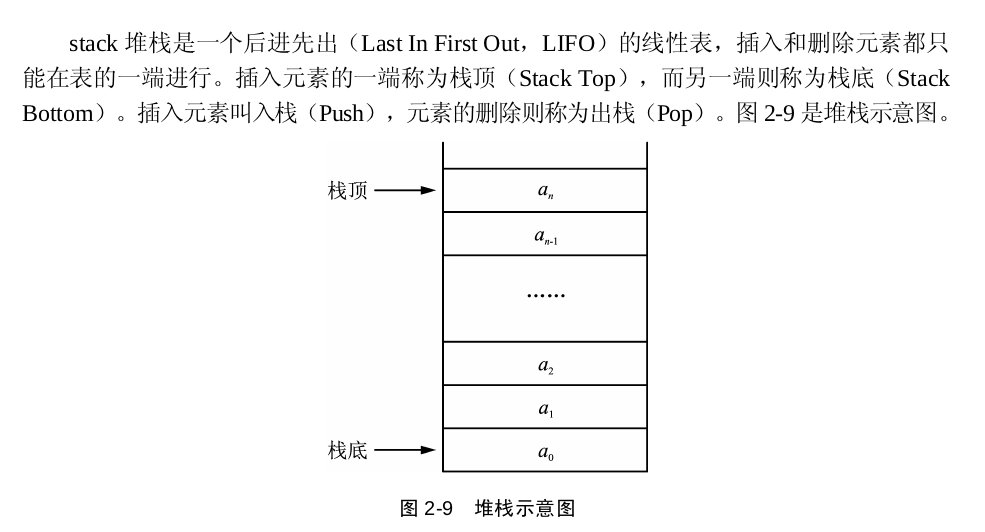
queue(栈)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 #include <iostream> #include <stack> using namespace std;int main (int argc, char *argv[]) stack<int > s; s.push (1 ); s.push (2 ); s.push (4 ); s.push (5 ); cout<<"s.size():" <<s.size ()<<endl; while (!s.empty ()){ cout<<s.top ()<<endl; s.pop (); } }
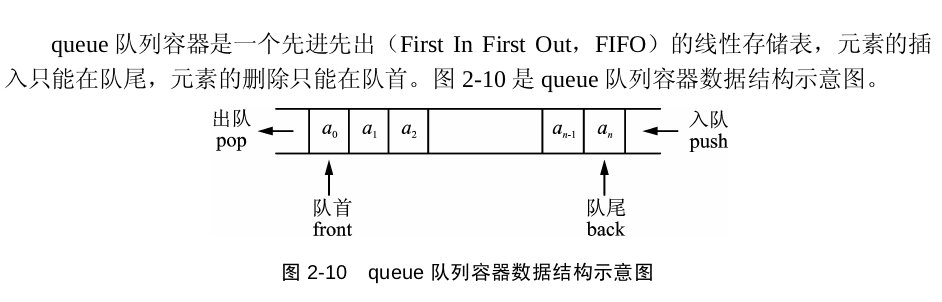
queue(队列)
queue有入队push(插入)、出队pop(删除)、读取队首元素front、读取队尾元素back、empty,size这几种方法,不多说了
priority_queue(优先队列)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 #include <iostream> #include <queue> using namespace std;int main (int argc, char *argv[]) priority_queue<int > pq; pq.push (1 ); pq.push (3 ); pq.push (2 ); pq.push (8 ); pq.push (9 ); pq.push (0 ); cout<<"pq.size:" <<pq.size ()<<endl; while (pq.empty () != true ){ cout << pq.top () << endl; pq.pop (); } }
重载操作符同set重载操作符

 中间删除,erase()
中间删除,erase()


 微信
微信 支付宝
支付宝